[1] 1 2 1 9[1] "numeric"NULLnon oui
1 2 <labelled<double>[4]>
[1] 1 2 1 9
Labels:
value label
1 non
2 oui[1] "haven_labelled" "vctrs_vctr" "double" Dans le domaine des grandes enquêtes, il est fréquent de coder les variables catégorielles avec des codes numériques auxquels on associé une certaines valeurs. Par exemple, une variable milieu de résidence pourrait être codée 1 pour urbain
, 2 pour semi-urbain
, 3 pour rural
et 9 pour indiquer une donnée manquante. Une variable binaire pourrait quant à elle être codée 0 pour non
et 1 pour oui
. Souvent, chaque enquête définit ses propres conventions.
Les logiciels statistiques propriétaires SPSS, Stata et SAS ont tous les trois un système d’étiquettes de valeurs pour représenter ce type de variables catégorielles.
R n’a pas, de manière native, de système d’étiquettes de valeurs. Le format utilisé en interne pour représenter les variables catégorielles est celui des facteurs (cf. Chapitre 9). Cependant, ce dernier ne permet de contrôler comment sont associées une étiquette avec une valeur numérique précise.
haven_labelled
Afin d’assurer une importation complète des données depuis SPSS, Stata et SAS, le package haven a introduit un nouveau type de vecteurs, la classe haven_labelled, qui permet justement de rendre compte de ces vecteurs labellisés (i.e. avec des étiquettes de valeurs). Le package labelled fournie un jeu de fonctions pour faciliter la manipulation des vecteurs labellisés.
Les vecteurs labellisés sont un format intermédiaire qui permets d’importer les données telles qu’elles ont été définies dans le fichier source. Il n’est pas destiné à être utilisé pour l’analyse statistique.
Pour la réalisation de tableaux, graphiques, modèles, R attend que les variables catégorielles soit codées sous formes de facteurs, et que les variables continues soient numériques. On aura donc besoin, à un moment ou à un autre, de convertir les vecteurs labellisés en facteurs ou en variables numériques classiques.
Pour définir des étiquettes, la fonction de base est labelled::val_labels(). Il est possible de définir des étiquettes de valeurs pour des vecteurs numériques, d’entiers et textuels. On indiquera les étiquettes sous la forme étiquette = valeur. Cette fonction s’utilise de la même manière que labelled::var_label() abordée au chapitre précédent (cf. Chapitre 11). Un appel simple renvoie les étiquettes de valeur associées au vecteur, NULL s’il n’y en n’a pas. Combiner avec l’opérateur d’assignation (<-), on peut ajouter/modifier les étiquettes de valeurs associées au vecteur.
[1] 1 2 1 9[1] "numeric"NULLnon oui
1 2 <labelled<double>[4]>
[1] 1 2 1 9
Labels:
value label
1 non
2 oui[1] "haven_labelled" "vctrs_vctr" "double" Comme on peut le voir avec cet exemple simple :
haven_labelled) ;double indiquant ici qu’il s’agit d’un vecteur numérique ;9).La fonction labelled::val_label() (notez l’absence d’un s à la fin du nom de la fonction) permet d’accéder / de modifier l’étiquette associée à une valeur spécifique.
[1] "non"NULL<labelled<double>[4]>
[1] 1 2 1 9
Labels:
value label
1 non
9 (manquant)Pour supprimer, toutes les étiquettes de valeurs, on attribuera NULL avec labelled::val_labels().
On remarquera que, lorsque toutes les étiquettes de valeurs sont supprimées, la nature de l’objet change à nouveau et il redevient un simple vecteur numérique.
Il est essentiel de bien comprendre que l’ajout d’étiquettes de valeurs ne change pas fondamentalement la nature du vecteur. Cela ne le transforme pas en variable catégorielle. À ce stade, le vecteur n’a pas été transformé en facteur. Cela reste un vecteur numérique qui est considéré comme tel par R. On peut ainsi en calculer une moyenne, ce qui serait impossible avec un facteur.
Les fonctions labelled::val_labels() et labelled::val_label() peuvent également être utilisées sur les colonnes d’un tableau.
# A tibble: 4 × 2
x y
<dbl+lbl> <dbl+lbl>
1 1 [non] 3
2 2 [oui] 9 [(manquant)]
3 1 [non] 9 [(manquant)]
4 2 [oui] 3 On pourra noter, que si notre tableau est un tibble, les étiquettes sont rendues dans la console quand on affiche le tableau.
La fonction labelled::look_for() est également un bon moyen d’afficher les étiquettes de valeurs.
pos variable label col_type missing values
1 x — dbl+lbl 0 [1] non
[2] oui
2 y — dbl+lbl 0 [9] (manquant)La fonction guideR::view_dictionary(), déjà présentée dans le chapitre sur les étiquettes de variables, cf. @#sec-etiquettes-variables, est ici aussi bien pratique.
labelled fournie 3 fonctions directement applicables sur un tableau de données : labelled::set_value_labels(), labelled::add_value_labels() et labelled::remove_value_labels(). La première remplace l’ensemble des étiquettes de valeurs associées à une variable, la seconde ajoute des étiquettes de valeurs (et conserve celles déjà définies), la troisième supprime les étiquettes associées à certaines valeurs spécifiques (et laisse les autres inchangées).
pos variable label col_type missing values
1 x — dbl+lbl 0 [1] non
[2] oui
2 y — dbl+lbl 0 [9] (manquant) pos variable label col_type missing values
1 x — dbl+lbl 0 [2] yes
2 y — dbl+lbl 0 [3] a répondu
[9] refus de répondre pos variable label col_type missing values
1 x — dbl+lbl 0 [2] yes
[1] no
2 y — dbl+lbl 0 [3] a réponduLa classe haven_labelled permets d’ajouter des métadonnées aux variables sous la forme d’étiquettes de valeurs. Lorsque les données sont importées depuis SAS, SPSS ou Stata, cela permet notamment de conserver le codage original du fichier importé.
Mais il faut noter que ces étiquettes de valeur n’indique pas pour autant de manière systématique le type de variable (catégorielle ou continue). Les vecteurs labellisés n’ont donc pas vocation à être utilisés pour l’analyse, notamment le calcul de modèles statistiques. Ils doivent être convertis en facteurs (pour les variables catégorielles) ou en vecteurs numériques (pour les variables continues).
La question qui peut se poser est donc de choisir à quel moment cette conversion doit avoir lieu dans un processus d’analyse. On peut considérer deux approches principales.
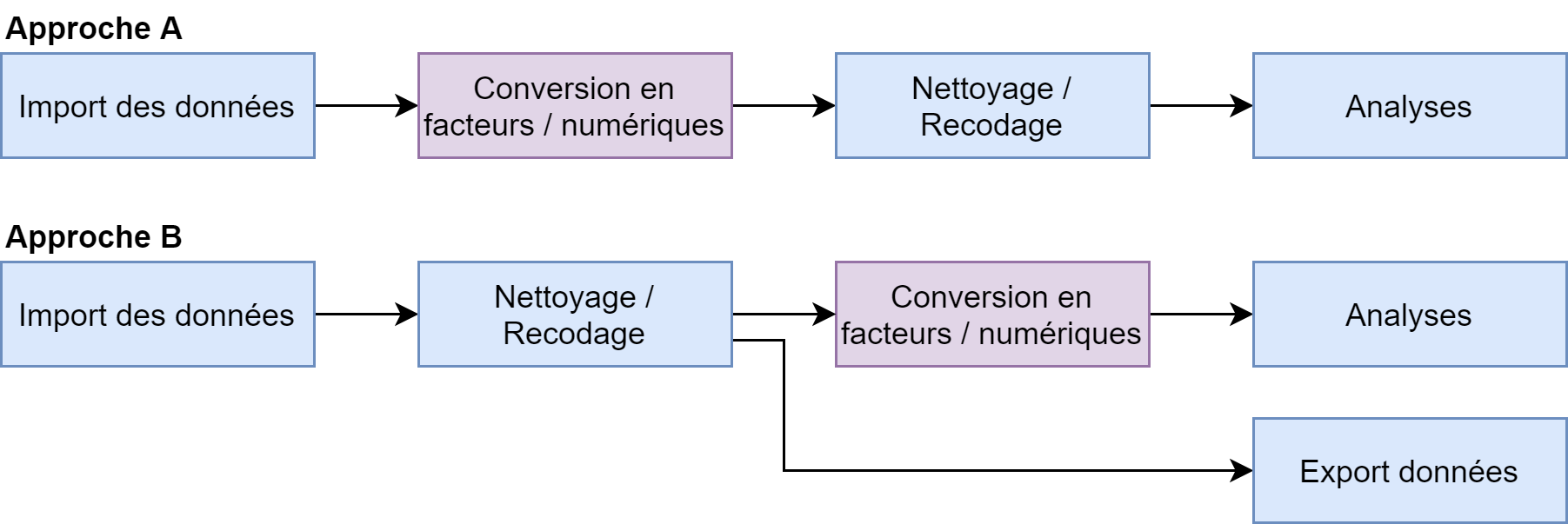
Dans l’approche A, les vecteurs labellisés sont convertis juste après l’import des données, en utilisant les fonctions labelled::unlabelled(), labelled::to_factor() ou base::unclass() qui sont présentées ci-après. Dès lors, toute la partie de nettoyage et de recodage des données se fera en utilisant les fonctions classiques de R. Si l’on n’a pas besoin de conserver le codage original, cette approche a l’avantage de s’inscrire dans le fonctionnement usuel de R.
Dans l’approche B, les vecteurs labellisés sont conservés pour l’étape de nettoyage et de recodage des données. Dans ce cas là, on pourra avoir recours aux fonctions de l’extension labelled qui facilitent la gestion des données labellisées. Cette approche est particulièrement intéressante quand (i) on veut pouvoir se référer au dictionnaire de codification fourni avec les données sources et donc on veut conserver le codage original et/ou (ii) quand les données devront faire l’objet d’un ré-export après transformation. Par contre, comme dans l’approche A, il faudra prévoir une conversion des variables labellisées au moment de l’analyse.
Dans tous les cas, il est recommandé d’adopter l’une ou l’autre approche, mais d’éviter de mélanger les différents types de vecteur. Une organisation rigoureuse de ses données et de son code est essentielle !
Il est très facile de convertir un vecteur labellisé en facteur à l’aide la fonction labelled::to_factor() du package labelled1.
1 On privilégiera la fonction labelled::to_factor() à la fonction haven::as_factor() de l’extension haven, la première ayant plus de possibilités et un comportement plus consistent.
<labelled<double>[7]>
[1] 1 2 9 3 3 2 NA
Labels:
value label
1 oui
2 peut-être
3 non
9 ne sait pas[1] oui peut-être ne sait pas non non peut-être
[7] <NA>
Levels: oui peut-être non ne sait pasIl possible d’indiquer si l’on souhaite, comme étiquettes du facteur, utiliser les étiquettes de valeur (par défaut), les valeurs elles-mêmes, ou bien les étiquettes de valeurs préfixées par la valeur d’origine indiquée entre crochets.
[1] oui peut-être ne sait pas non non peut-être
[7] <NA>
Levels: oui peut-être non ne sait pas[1] 1 2 9 3 3 2 <NA>
Levels: 1 2 3 9[1] [1] oui [2] peut-être [9] ne sait pas [3] non
[5] [3] non [2] peut-être <NA>
Levels: [1] oui [2] peut-être [3] non [9] ne sait pasPar défaut, les modalités du facteur seront triées selon l’ordre des étiquettes de valeur. Mais cela peut être modifié avec l’argument sort_levels si l’on préfère trier selon les valeurs ou selon l’ordre alphabétique des étiquettes.
Pour rappel, il existe deux types de vecteurs labellisés : des vecteurs numériques labellisés (x dans l’exemple ci-dessous) et des vecteurs textuels labellisés (y dans l’exemple ci-dessous).
Pour leur retirer leur caractère labellisé
et revenir à leur classe d’origine, on peut utiliser la fonction unclass().
[1] 1 2 9 3 3 2 NA
attr(,"labels")
oui peut-être non ne sait pas
1 2 3 9 [1] "f" "f" "h" "f"
attr(,"labels")
femme homme
"f" "h" À noter que dans ce cas-là, les étiquettes sont conservées comme attributs du vecteur.
Une alternative est d’utiliser labelled::remove_labels() qui supprimera toutes les étiquettes, y compris les étiquettes de variable. Pour conserver les étiquettes de variables et ne supprimer que les étiquettes de valeurs, on indiquera keep_var_label = TRUE.
[1] 1 2 9 3 3 2 NA[1] 1 2 9 3 3 2 NA
attr(,"label")
[1] "Etiquette de variable"[1] "f" "f" "h" "f"Dans le cas d’un vecteur numérique labellisé que l’on souhaiterait convertir en variable textuelle, on pourra utiliser labelled::to_character() à la place de labelled::to_factor() qui, comme sa grande sœur, utilisera les étiquettes de valeurs.
Il n’est pas toujours possible de déterminer la nature d’une variable (continue ou catégorielle) juste à partir de la présence ou l’absence d’étiquettes de valeur. En effet, on peut utiliser des étiquettes de valeur dans le cadre d’une variable continue pour indiquer certaines valeurs spécifiques.
Une bonne pratique est de vérifier chaque variable inclue dans une analyse, une à une.
Cependant, une règle qui fonctionne dans 90% des cas est de convertir un vecteur labellisé en facteur si et seulement si toutes les valeurs observées dans le vecteur disposent d’une étiquette de valeur correspondante. C’est ce que propose la fonction labelled::unlabelled() qui peut même être appliqué à tout un tableau de données. Par défaut, elle fonctionne ainsi :
base::unclass() (variables a, d et e).df <- dplyr::tibble(
a = c(1, 1, 2, 3),
b = c(1, 1, 2, 3),
c = c(1, 1, 2, 2),
d = c("a", "a", "b", "c"),
e = c(1, 9, 1, 2),
f = 1:4,
g = as.Date(c(
"2020-01-01", "2020-02-01",
"2020-03-01", "2020-04-01"
))
) |>
set_value_labels(
a = c(No = 1, Yes = 2),
b = c(No = 1, Yes = 2, DK = 3),
c = c(No = 1, Yes = 2, DK = 3),
d = c(No = "a", Yes = "b"),
e = c(No = 1, Yes = 2)
)
df |> look_for() pos variable label col_type missing values
1 a — dbl+lbl 0 [1] No
[2] Yes
2 b — dbl+lbl 0 [1] No
[2] Yes
[3] DK
3 c — dbl+lbl 0 [1] No
[2] Yes
[3] DK
4 d — chr+lbl 0 [a] No
[b] Yes
5 e — dbl+lbl 0 [1] No
[2] Yes
6 f — int 0
7 g — date 0 pos variable label col_type missing values
1 a — fct 0 No
Yes
3
2 b — fct 0 No
Yes
DK
3 c — fct 0 No
Yes
DK
4 d — fct 0 No
Yes
c
5 e — fct 0 No
Yes
9
6 f — int 0
7 g — date 0 pos variable label col_type missing values
1 a — dbl 0
2 b — fct 0 No
Yes
DK
3 c — fct 0 No
Yes
DK
4 d — chr 0
5 e — dbl 0
6 f — int 0
7 g — date 0 On peut indiquer certaines options, par exemple drop_unused_labels = TRUE pour supprimer des facteurs créés les niveaux non observées dans les données (voir la variable c).
pos variable label col_type missing values
1 a — dbl 0
2 b — fct 0 No
Yes
DK
3 c — fct 0 No
Yes
4 d — chr 0
5 e — dbl 0
6 f — int 0
7 g — date 0 pos variable label col_type missing values
1 a — dbl 0
2 b — fct 0 [1] No
[2] Yes
[3] DK
3 c — fct 0 [1] No
[2] Yes
[3] DK
4 d — chr 0
5 e — dbl 0
6 f — int 0
7 g — date 0