Il existe plusieurs techniques d’analyse factorielle dont les plus courantes sont l’analyse en composante principale (ACP) portant sur des variables quantitatives, l’analyse factorielle des correspondances (AFC) portant sur deux variables qualitatives et l’analyse des correspondances multiples (ACM) portant sur plusieurs variables qualitatives (il s’agit d’une extension de l’AFC). Pour combiner des variables à la fois quantitatives et qualitatives, on pourra avoir recours à l’analyse factorielle avec données mixtes.
Bien que ces techniques soient disponibles dans les extensions standards de R, il est souvent préférable d’avoir recours à deux autres packages plus complets, {ade4} et {FactoMineR}, chacun ayant ses avantages et des possibilités différentes1. Voici les fonctions à retenir :
1 Ces deux packages sont très complets et il est difficile de privilégier l’un par rapport à l’autre. Tous deux sont activement maintenus et bénéficient d’une documentation complète. À titre personnel, j’aurai peut être une petite préférence pour {ade4}. En effet, {FactoMineR} a une tendance à réaliser toutes les étapes de l’analyse en un seul appel de fonction, là où {ade4} nécessitera quelques étapes supplémentaires. Or, ce qui pourrait être vu comme un inconvénient permet à l’inverse d’avoir une meilleure conscience de ce que l’on fait. À l’inverse, les options graphiques offertes par {factoextra} sont plus nombreuses quand l’analyse factorielle a été réalisée avec {FactoMineR}. Enfin, nous le verrons plus loin, la gestion de variables additionnelles est bien plus facile avec {FactoMineR}.
Analyse
Variables
Fonction standard
Fonction {ade4}
Fonctions {FactoMineR}
ACP
plusieurs variables quantitatives
stats::princomp()
ade4::dudi.pca()
FactoMineR::PCA()
AFC
deux variables qualitatives
MASS::corresp()
ade4::dudi.coa()
FactoMineR::CA()
ACM
plusieurs variables qualitatives
MASS::mca()
ade4::dudi.acm()
FactoMineR::MCA()
Analyse mixte
plusieurs variables quantitatives et/ou qualitatives
—
ade4::dudi.mix()
FactoMineR::FAMD()
Notons que l’extension {GDATools} propose une variation de l’ACM permettant de neutraliser tout en conservant les valeurs manquantes : on parle alors d’Analyse des correspondances multiples spécifique qui se calcule avec la fonction GDAtools::speMCA().
Le package {FactoMineR} propose également deux variantes avancées : l’analyse factorielle multiple permettant d’organiser les variables en groupes (fonction FactoMineR::MFA()) et l’analyse factorielle multiple hiérarchique (fonction FactoMineR::MFA()).
Deux autres packages nous seront particulièrement utiles dans ce chapitre : {explor} pour une exploration visuelle interactive des résultats et {factoextra} pour diverses représentations graphiques.
42.1 Principe général
L’analyse des correspondances multiples est une technique descriptive visant à résumer l’information contenu dans un grand nombre de variables afin de faciliter l’interprétation des corrélations existantes entre ces différentes variables. On cherche à savoir quelles sont les modalités corrélées entre elles.
L’idée générale est la suivante. L’ensemble des individus peut être représenté dans un espace à plusieurs dimensions où chaque axe représente les différentes variables utilisées pour décrire chaque individu. Plus précisément, pour chaque variable qualitative, il y a autant d’axes que de modalités moins un. Ainsi il faut trois axes pour décrire une variable à quatre modalités. Un tel nuage de points est aussi difficile à interpréter que de lire directement le fichier de données. On ne voit pas les corrélations qu’il peut y avoir entre modalités, par exemple qu’aller au cinéma est plus fréquent chez les personnes habitant en milieu urbain. Afin de mieux représenter ce nuage de points, on va procéder à un changement de systèmes de coordonnées. Les individus seront dès lors projetés et représentés sur un nouveau système d’axe. Ce nouveau système d’axes est choisis de telle manière que la majorité des variations soit concentrées sur les premiers axes. Les deux-trois premiers axes permettront d’expliquer la majorité des différences observées dans l’échantillon, les autres axes n’apportant qu’une faible part additionnelle d’information. Dès lors, l’analyse pourra se concentrer sur ses premiers axes qui constitueront un bon résumé des variations observables dans l’échantillon.
Important
Avant toute analyse factorielle, il est indispensable de réaliser une analyse préliminaire de chaque variable, afin de voir si toutes les classes sont aussi bien représentées ou s’il existe un déséquilibre. L’analyse factorielle est sensible aux petits effectifs. Aussi il peut être préférable de regrouper les classes peu représentées le cas échéant.
De même, il peut être tentant de mettre toutes les variables disponibles dans son jeu de données directement dans une analyse factorielle pour voir ce que ça donne. Il est préférable de réfléchir en amont aux questions que l’on veut poser et de choisir ensuite un jeu de variables en fonction.
42.2 Première illustration : ACM sur les loisirs
Pour ce premier exemple, nous allons considérer le jeu de données hdv2003 fourni dans le package {questionr} et correspondant à un extrait de l’enquête Histoire de Vie réalisée par l’Insee en 2003.
Nous allons considérer 7 variables binaires (oui/non) portant sur la pratique de différents loisirs (écouter du hard rock, lire des bandes dessinées, pratiquer la pêche ou la chasse, cuisiner, bricoler ou pratiquer un sport). Pour le moment, nous n’allons pas intégrer à l’analyse de variable socio-démographique, car nous souhaitons explorer comment ces activités se corrèlent entre elles, indépendamment de toute autre considération.
Notons, avec questionr::freq.na() ou avec labelled::look_for(), qu’il n’y a pas de valeurs manquantes dans nos données.
pos variable label col_type missing values
1 hard.rock — fct 0 Non
Oui
2 lecture.bd — fct 0 Non
Oui
3 peche.chasse — fct 0 Non
Oui
4 cuisine — fct 0 Non
Oui
5 bricol — fct 0 Non
Oui
6 cinema — fct 0 Non
Oui
7 sport — fct 0 Non
Oui
Comme l’ensemble de nos variables sont catégorielles nous allons réaliser une analyse des correspondances multiples (ACM).
42.2.1 Calcul de l’ACM
Avec {ade4}, l’ACM s’obtient à l’aide la fonction ade4::dudi.acm(). Par défaut, si l’on exécute seulement ade4::dudi.acm(d), la fonction va afficher un graphique indiquant la variance expliquée par chaque axe et une invite dans la console va demander le nombre d’axes à conserver pour l’analyse. Une invite de commande n’est pas vraiment adaptée dans le cadre d’un script que l’on souhaite pouvoir exécuter car cela implique une intervention manuelle. On pourra désactiver cette invitation avec scannf = FALSE et indiquer le nombre d’axes à conserver avec l’argument nf (nf = Inf permet de conserver l’ensemble des axes).
acm1_ad <- d |> ade4::dudi.acm(scannf =FALSE, nf =Inf)
Avec {FactoMineR}, l’ACM s’obtient avec FactoMineR::MCA(). Par défaut, seuls les 5 premiers axes sont conservés, ce qui est modifiable avec l’argument ncp. De plus, la fonction affiche par défaut un graphique des résultats avant de renvoyer les résultats de l’ACM. Ce graphique peut être désactivé avec graph = FALSE.
acm1_fm <- d |> FactoMineR::MCA(ncp =Inf, graph =FALSE)
Les deux ACM sont ici identiques. Par contre, les deux objets renvoyés ne sont pas structurés de la même manière.
42.2.2 Exploration graphique interactive
Le package {explor} permets d’explorer les résultats de manière interactive. Il fonctionne à la fois avec les analyses factorielles produites avec {FactoMineR} et celles réalisées avec {ade4}.
Pour lancer l’exploration interactive, il suffit de passer les résultats de l’ACM à la fonction explor::explor().
acm1_ad |> explor::explor()
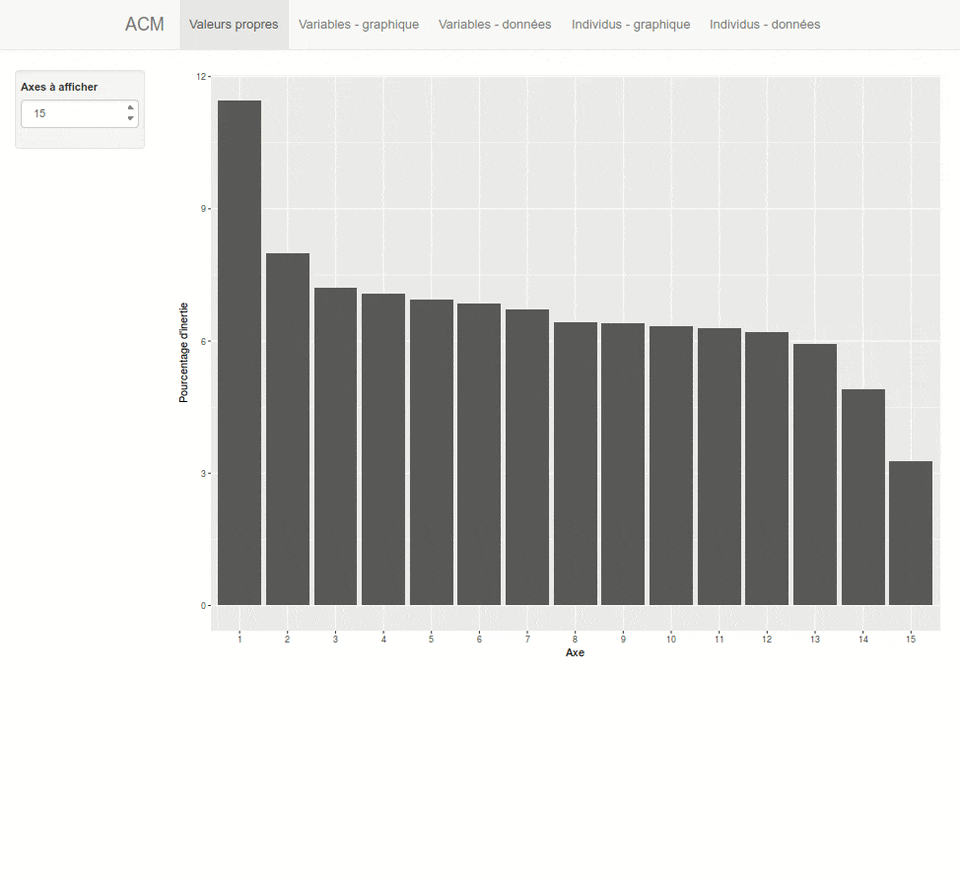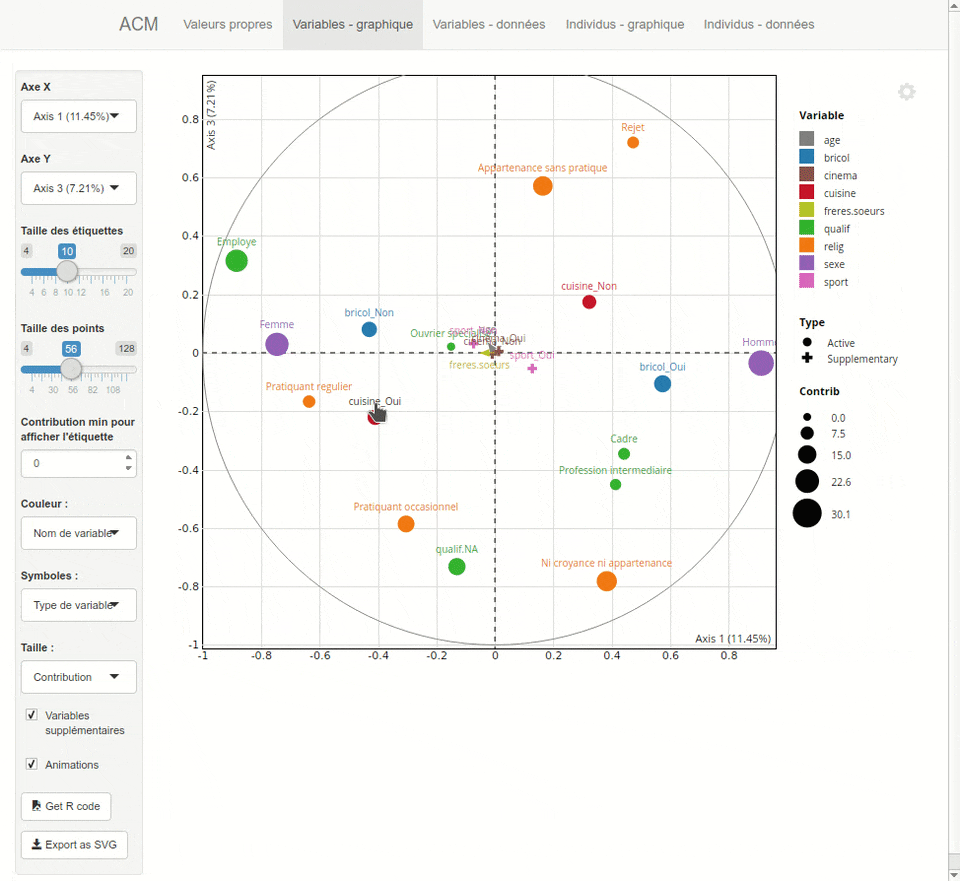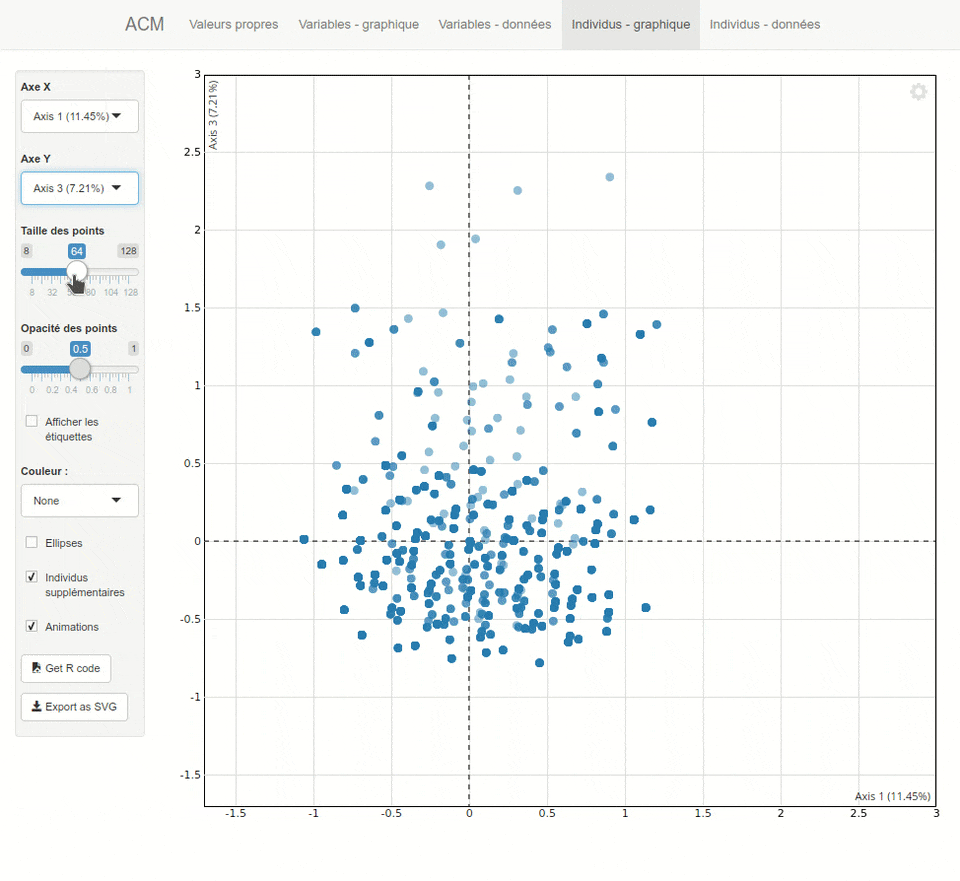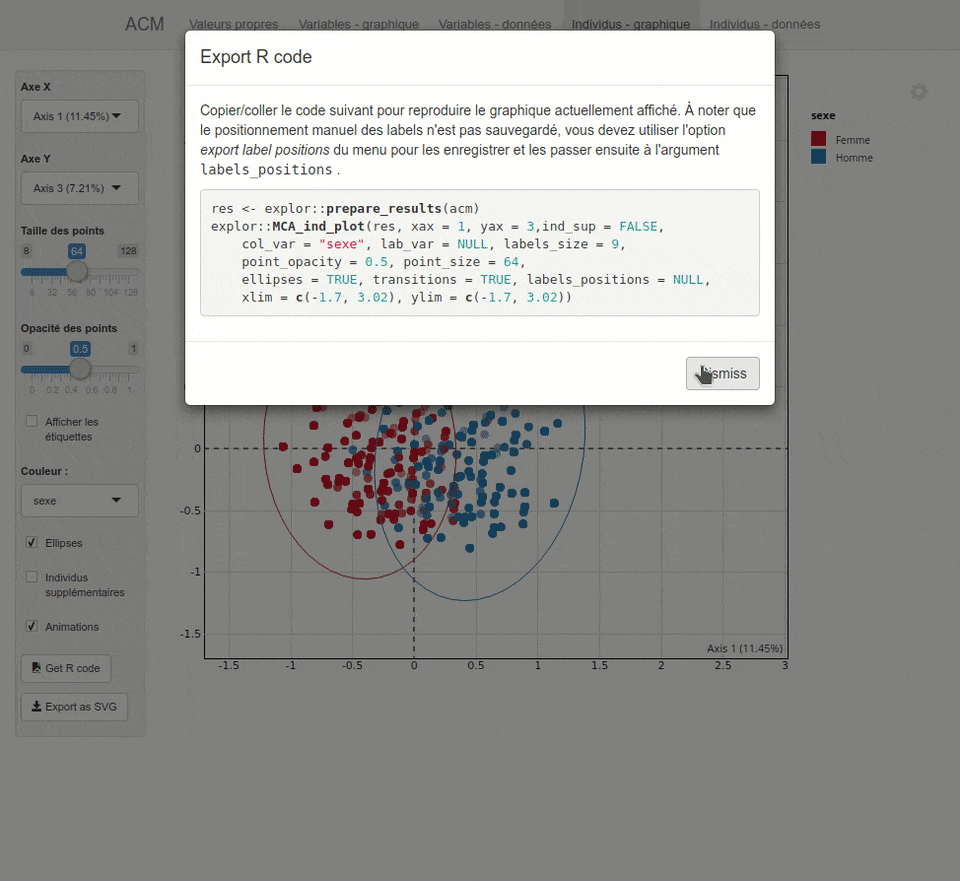
Figure 42.1: Capture d’écran de l’interface d’explor
Les graphiques réalisés avec explor::explor() peuvent être exportés en fichier image SVG (via le bouton dédié en bas à gauche dans l’interface). De même, il est possible d’obtenir un code R que l’on pourra copier dans un script pour reproduire le graphique (ATTENTION : le graphique produit est interactif et donc utilisable uniquement dans document web).
À la fois {ade4} et {FactoMineR} disposent de leurs propres fonctions graphiques dédiées. Elles sont cependant spécifiques à chaque package. Les fonctions graphiques de {ade4} ne peuvent pas être utilisées avec un objet {FactoMineR} et inversement.
Le package {factoextra} permet de palier à ce problème. Ces fonctions graphiques sont en effet compatibles avec les deux packages et reposent sur {ggplot2}, ce qui permet facilement de personnaliser les graphiques obtenus.
42.2.4 Variance expliquée et valeurs propres
Les valeurs propres (eigen values en anglais) correspondent à la quantité de variance capturée par chaque axe (on parle également d’inertie). On peut les obtenir aisément avec la fonction factoextra::get_eigenvalue().
On notera que les axes sont ordonnées en fonction de la quantité de variation qu’ils capturent. Le premier axe est toujours celui qui capture le plus de variance, suivi du deuxième, etc.
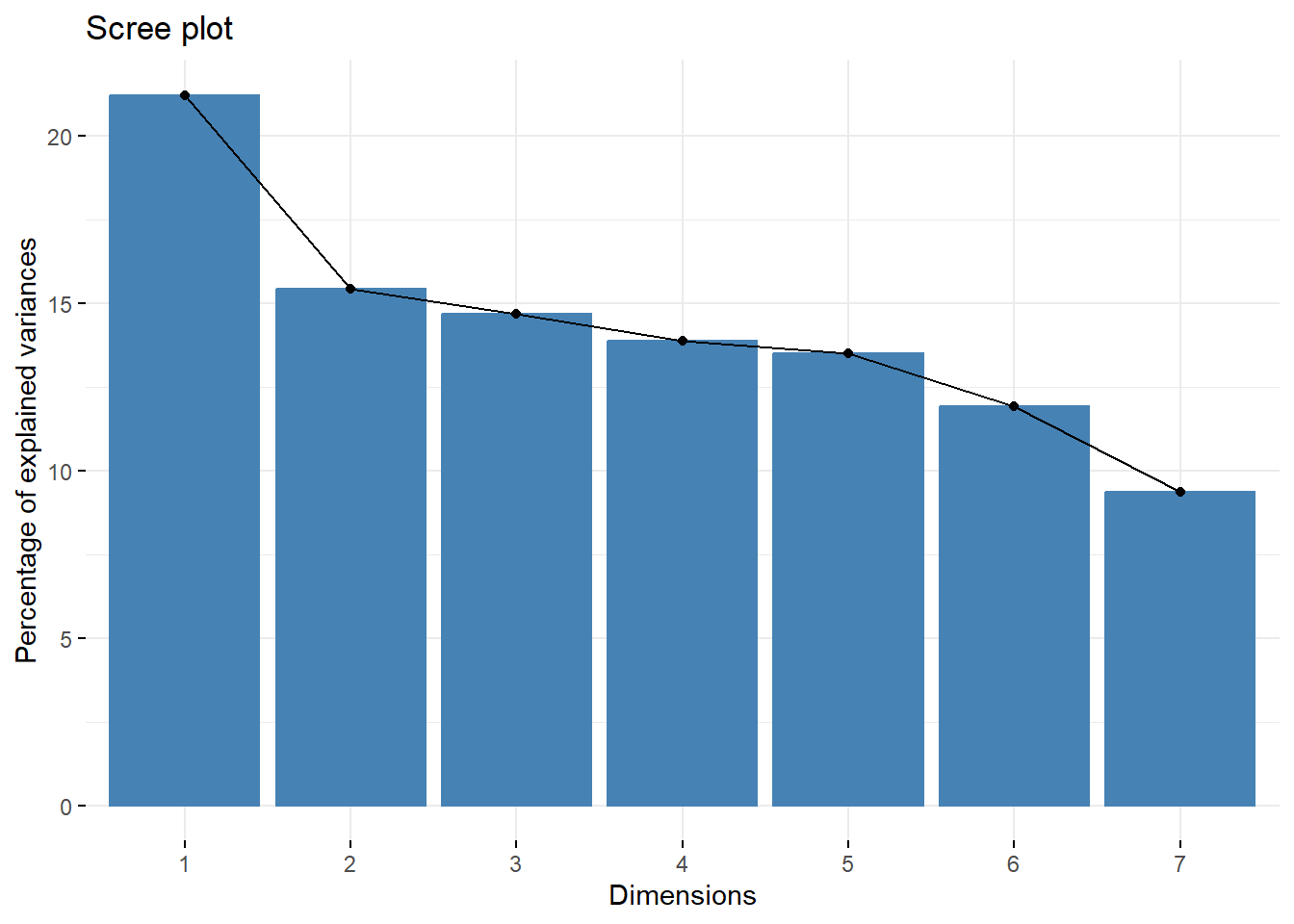
La somme totale des valeurs propres indique la variation totale des données. Souvent, les valeurs propres sont exprimées en pourcentage du total. Dans notre exemple, l’axe 1 capture 21,2 % de la variance et l’axe 2 en capture 15,4 %. Ainsi, le plan factoriel composé des deux premiers axes permet de capturer à lui seul plus du tiers (36,6 %) de la variance totale.
Une représentation graphique des valeurs propres s’obtient avec factoextra::fviz_screeplot().
acm1_ad |> factoextra::fviz_screeplot()
Warning in geom_bar(stat = "identity", fill = barfill, color = barcolor, :
Ignoring empty aesthetic: `width`.
Figure 42.2: Représentation graphique de la variance expliquée par les différents axes de l’ACM
Il n’y a pas de règle absolue concernant le nombre d’axes à explorer pour l’analyse et l’interprétation des résultats. L’objectif d’une analyse factorielle étant justement de réduire le nombre de dimension considérée pour ce concentrer sur les principales associations entre modalités, il est fréquent de se limiter aux deux premiers ou aux trois premiers axes.
Une approche fréquente consiste à regarder s’il y a un coude, un saut plus marqué qu’un autre dans le graphique des valeurs propres. Dans notre exemple, qui ne comporte qu’un petit nombre de variable, on voit un saut marqué entre le premier axe et les autres, suggérant de se focaliser en particulier sur ce premier axe.
42.2.5 Contribution aux axes
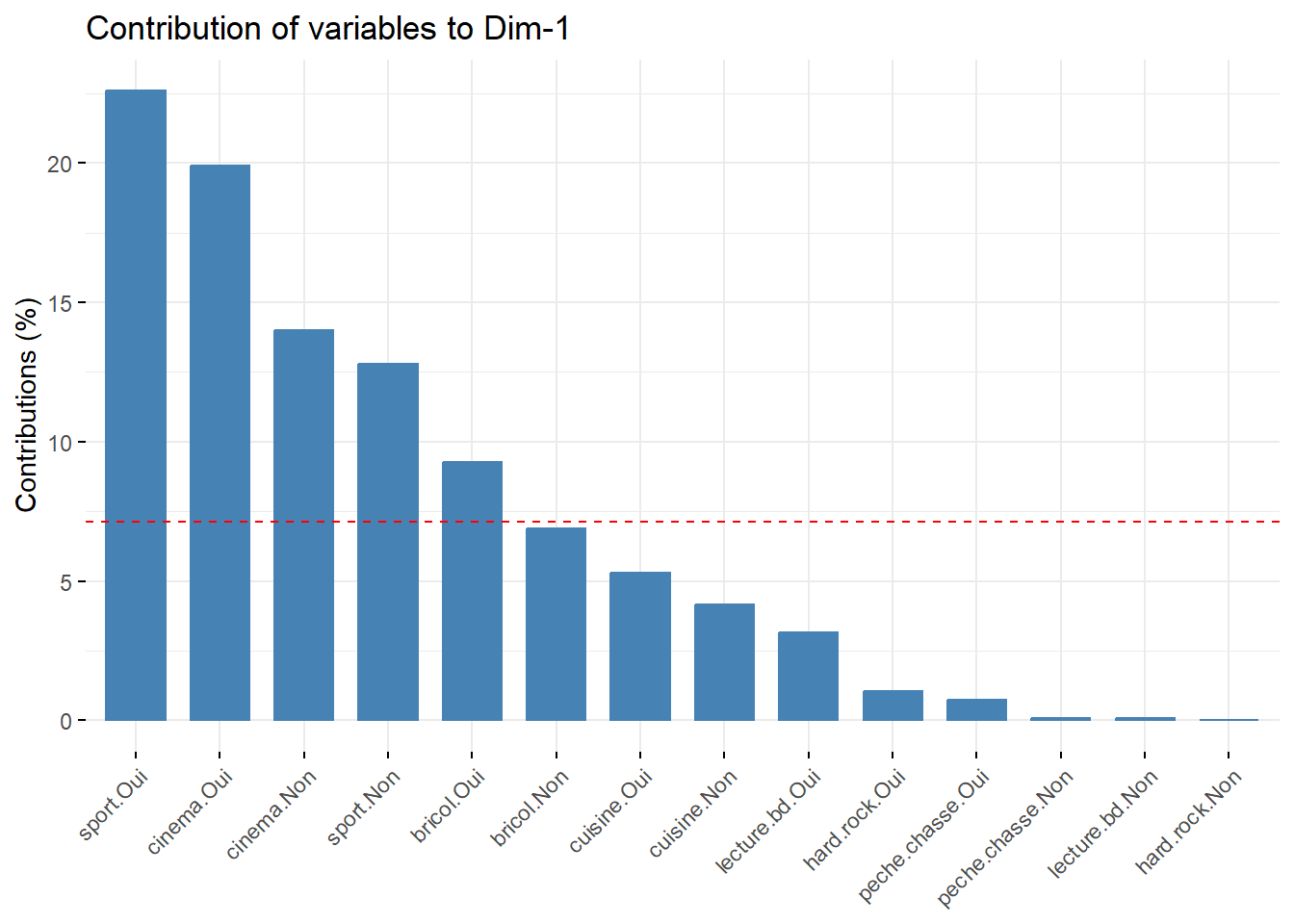
La fonction factoextra::fviz_contrib() permet de visualiser la contribution des différentes modalités à un axe donnée. Regardons le premier axe.
Figure 42.3: Contribution des modalités au premier axe
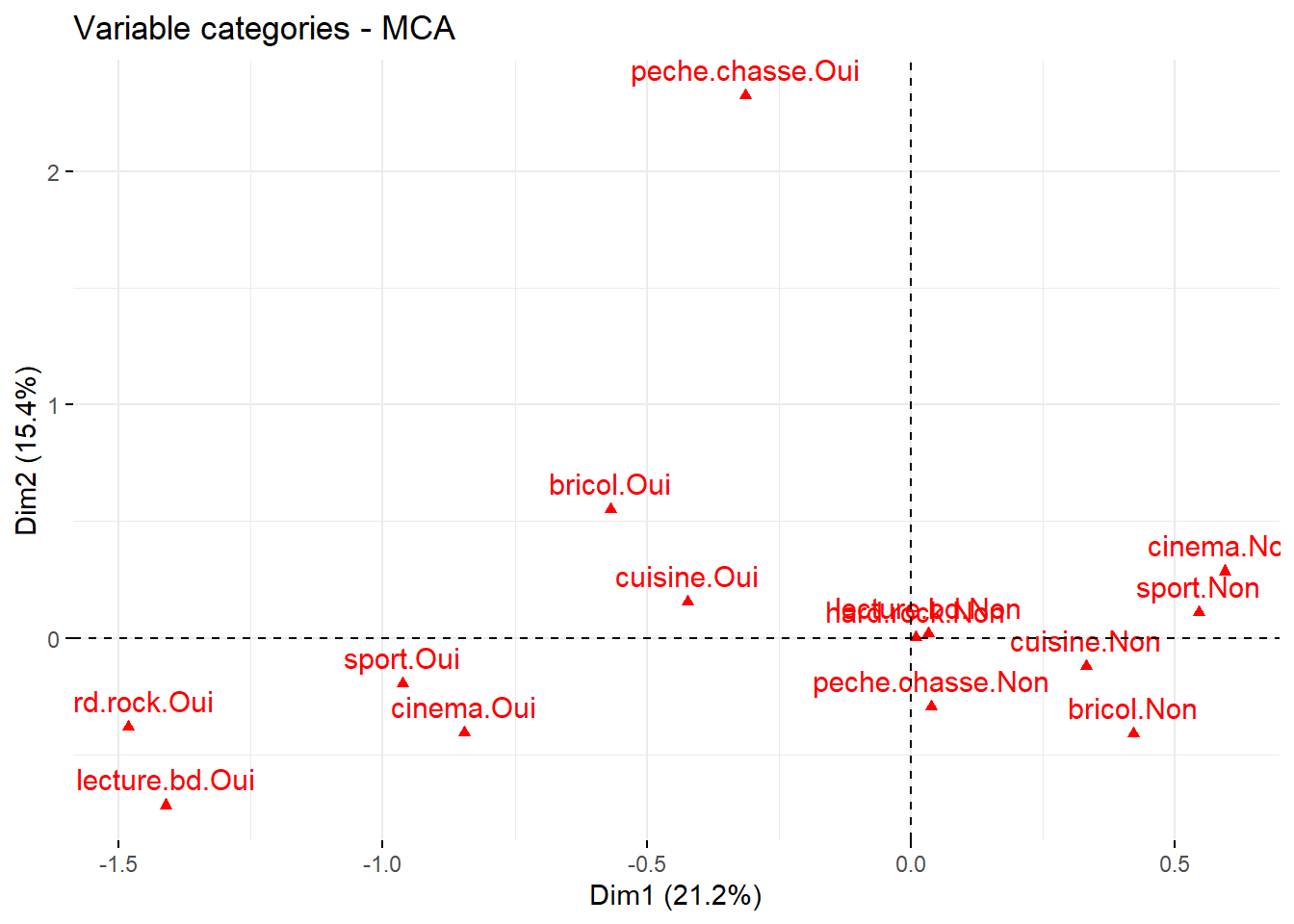
La ligne en pointillés rouges indique la contribution attendue de chaque modalité si la répartition était uniforme. Nous constatons ici que le premier axe est surtout déterminé par la pratique d’une activité sportive et le fait d’aller au cinéma.
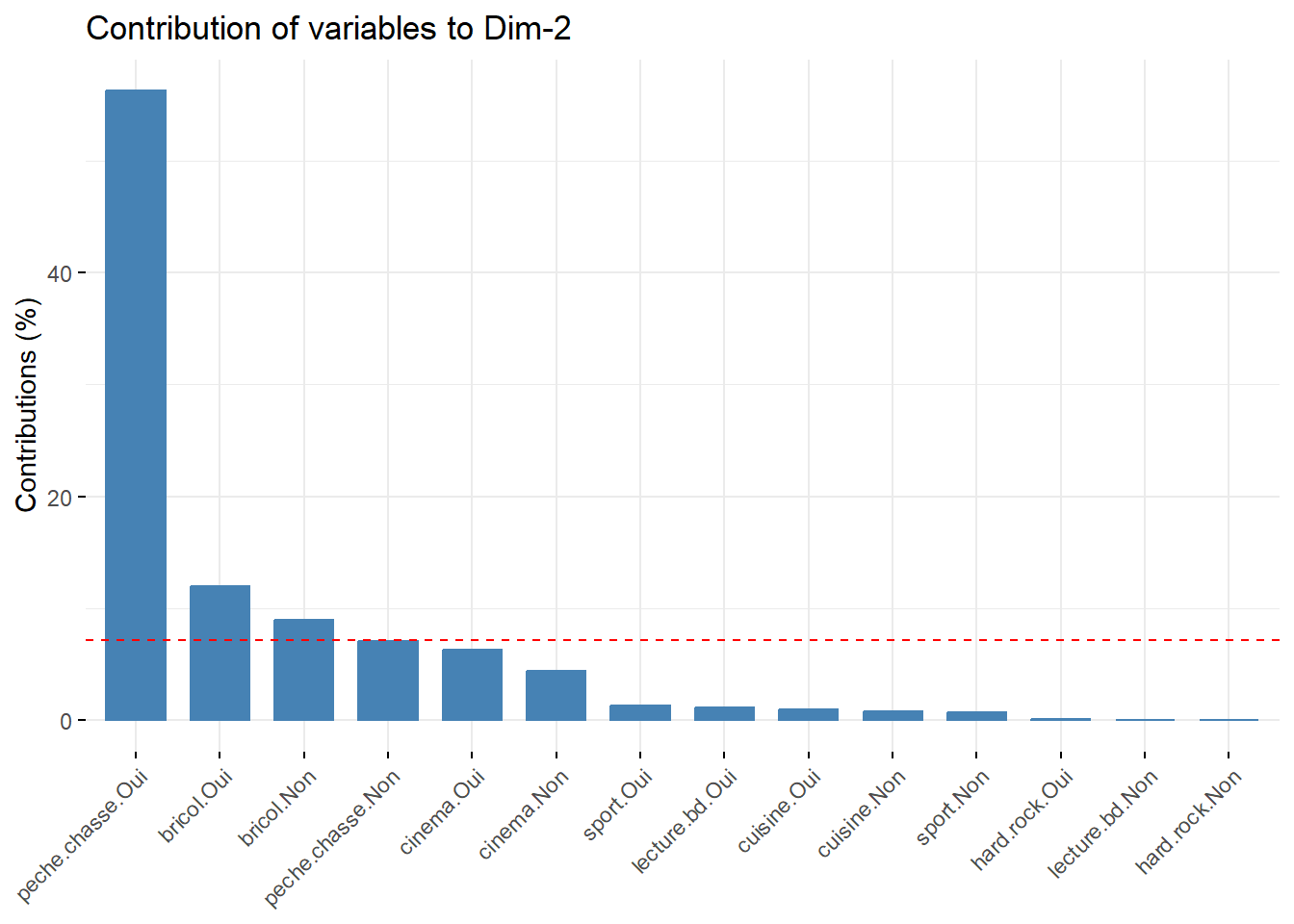
Figure 42.4: Contribution des modalités au deuxième axe
Le deuxième axe, quant à lui, est surtout marqué par la pratique de la pêche ou de la chasse et, dans une moindre mesure, par le fait de bricoler.
42.2.6 Représentation des modalités dans le plan factoriel
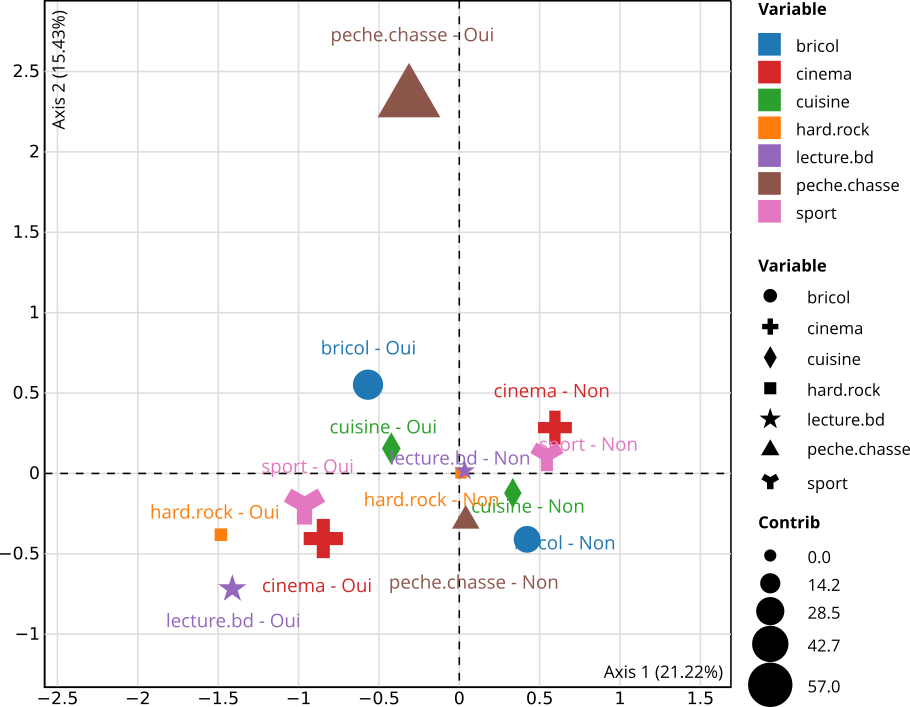
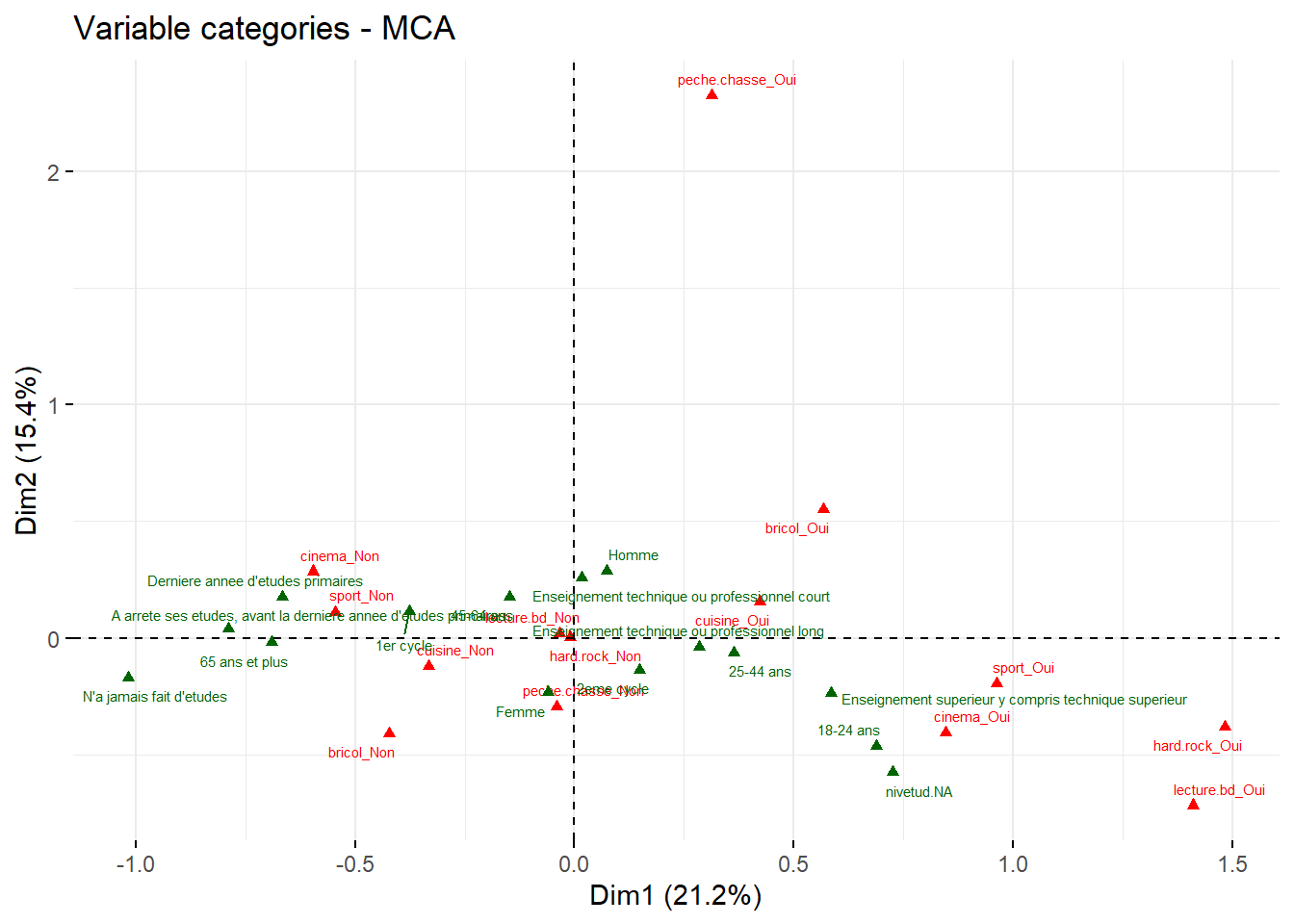
Pour représenter les modalités dans le plan factoriel, on aura recours à factoextra::fviz_mca_var(). En termes de visualisation, c’est moins ergonomique que ce que propose {explor}. On aura donc tout intérêt à profiter de ce dernier. Si l’on a réalisé un autre type d’analyse factorielle, il faudra choisir la fonction correspondante, par exemple factoextra::fviz_famd_var() pour une analyse sur données mixtes. La liste complète est visible sur le site de documentation du package.
acm1_ad |> factoextra::fviz_mca_var()
Figure 42.5: Projection des modalités dans le plan factoriel
Note
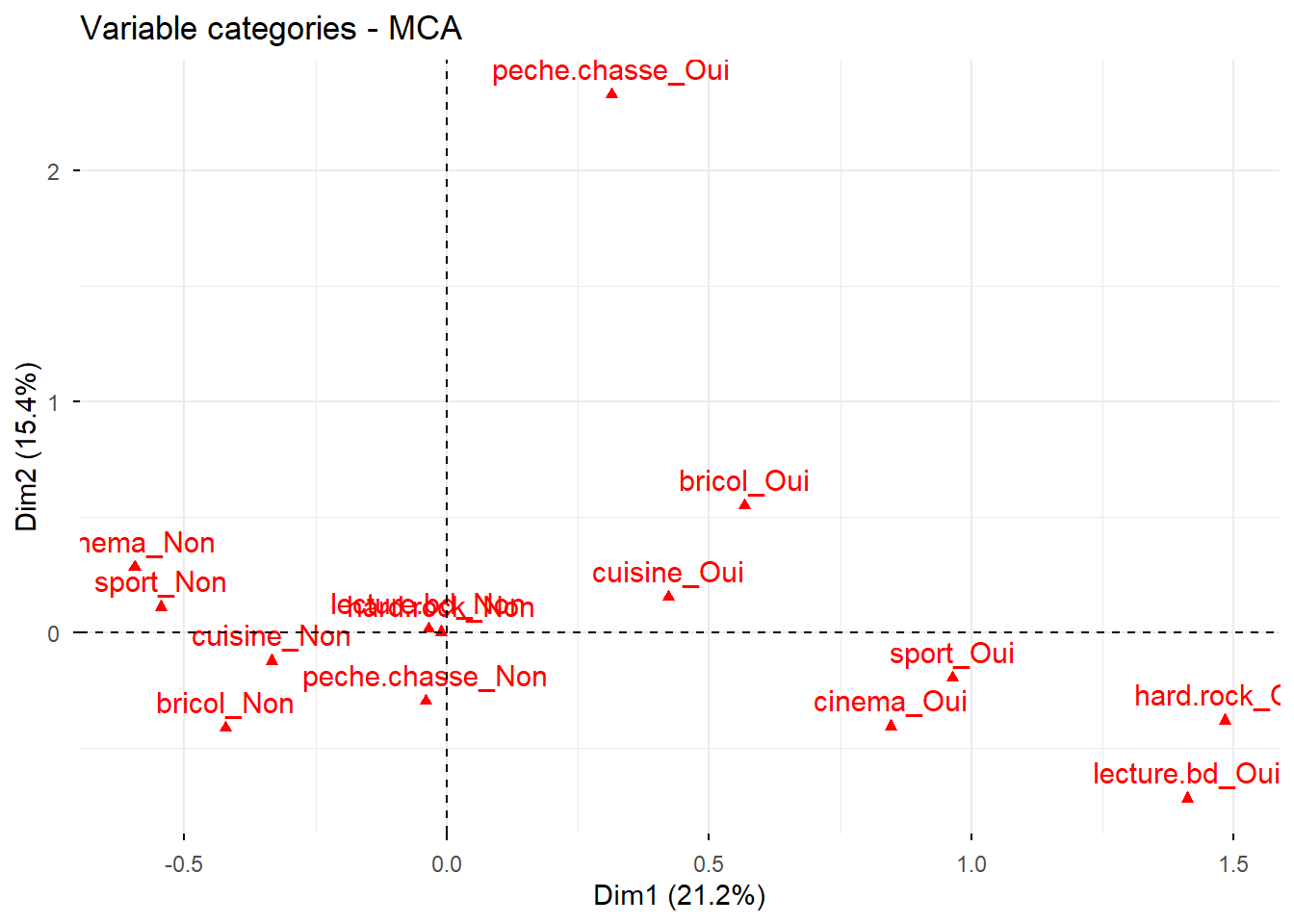
Si l’on réalise le même graphique à partir de l’ACM réalisée avec {FactoMineR}, nous aurons à première vue un résultat différent.
acm1_fm |> factoextra::fviz_mca_var()
Si l’on regarde plus attentivement, les valeurs sont inversées sur l’axe 1 : les valeurs positives sont devenues négatives et inversement. Ceci est du à de légères différences dans les algorithmes de calcul des deux packages. Pour autant, les résultats sont bien strictement équivalents, le sens des axes n’ayant pas de signification en soi.
42.2.7 Représentation des individus dans le plan factoriel
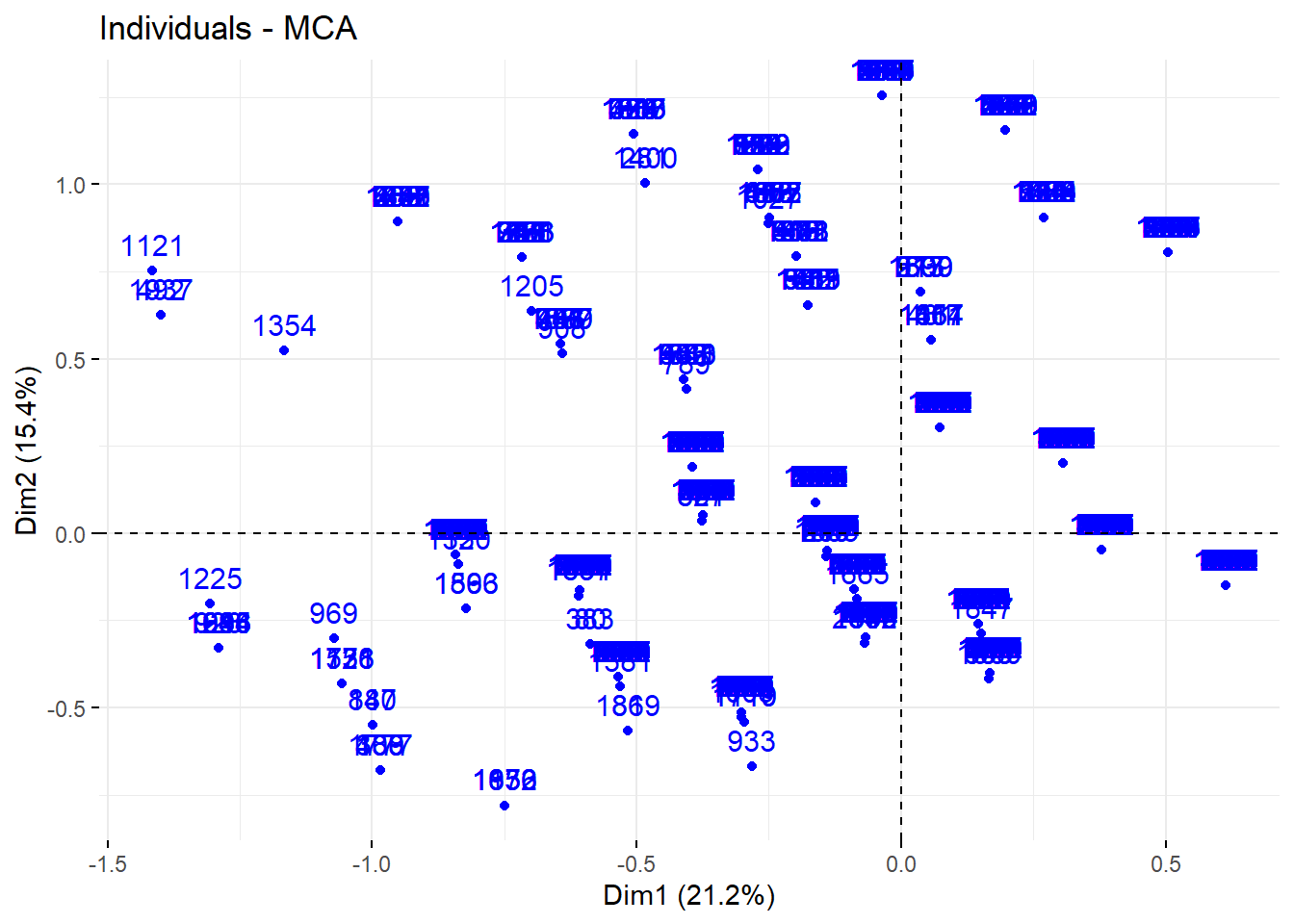
Pour projeter les individus (i.e. les observations) dans le plan factoriel, nous aurons recours à factoextra::fviz_mca_ind().
acm1_ad |> factoextra::fviz_mca_ind()
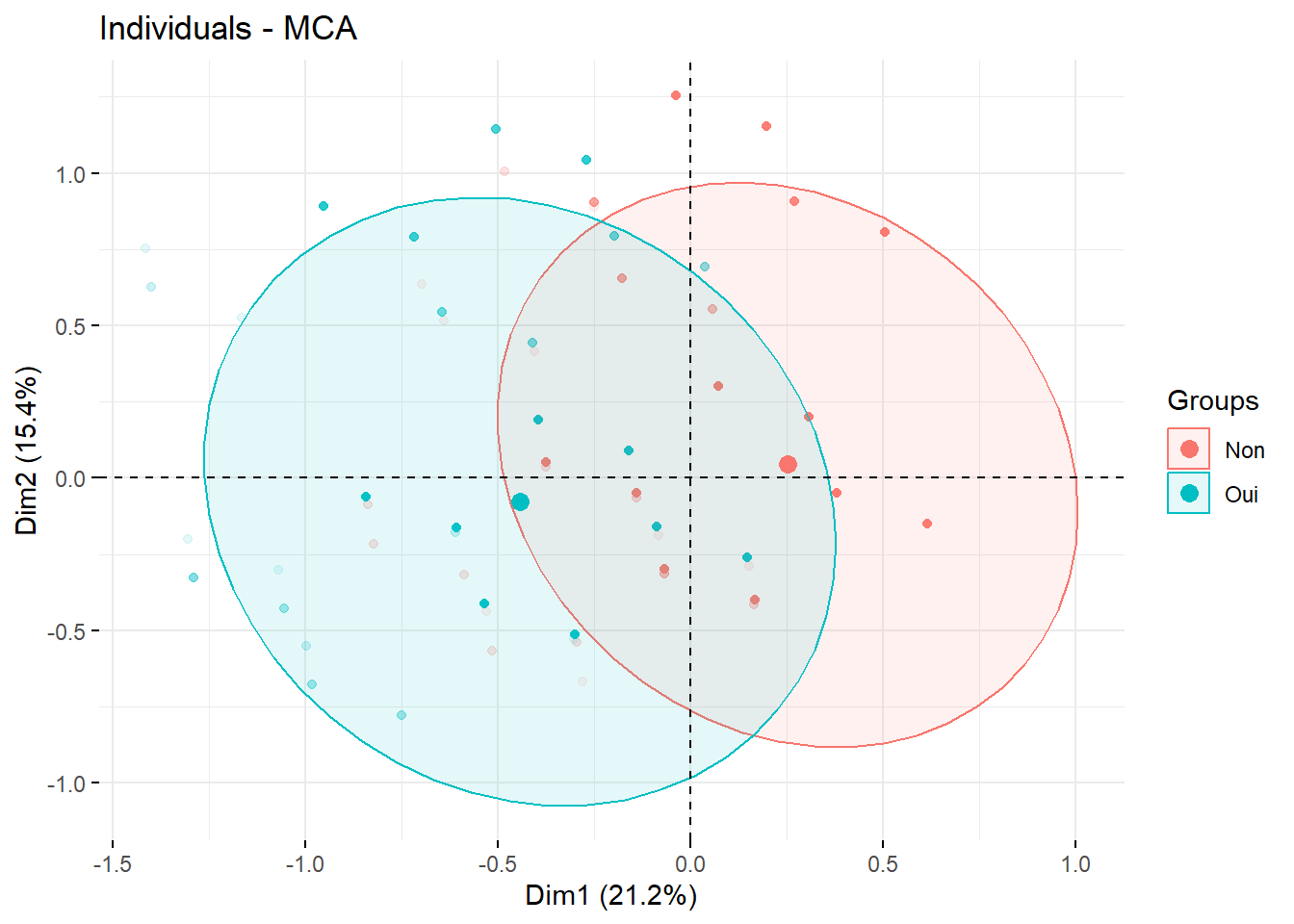
Figure 42.6: Projection des individus dans le plan factoriel
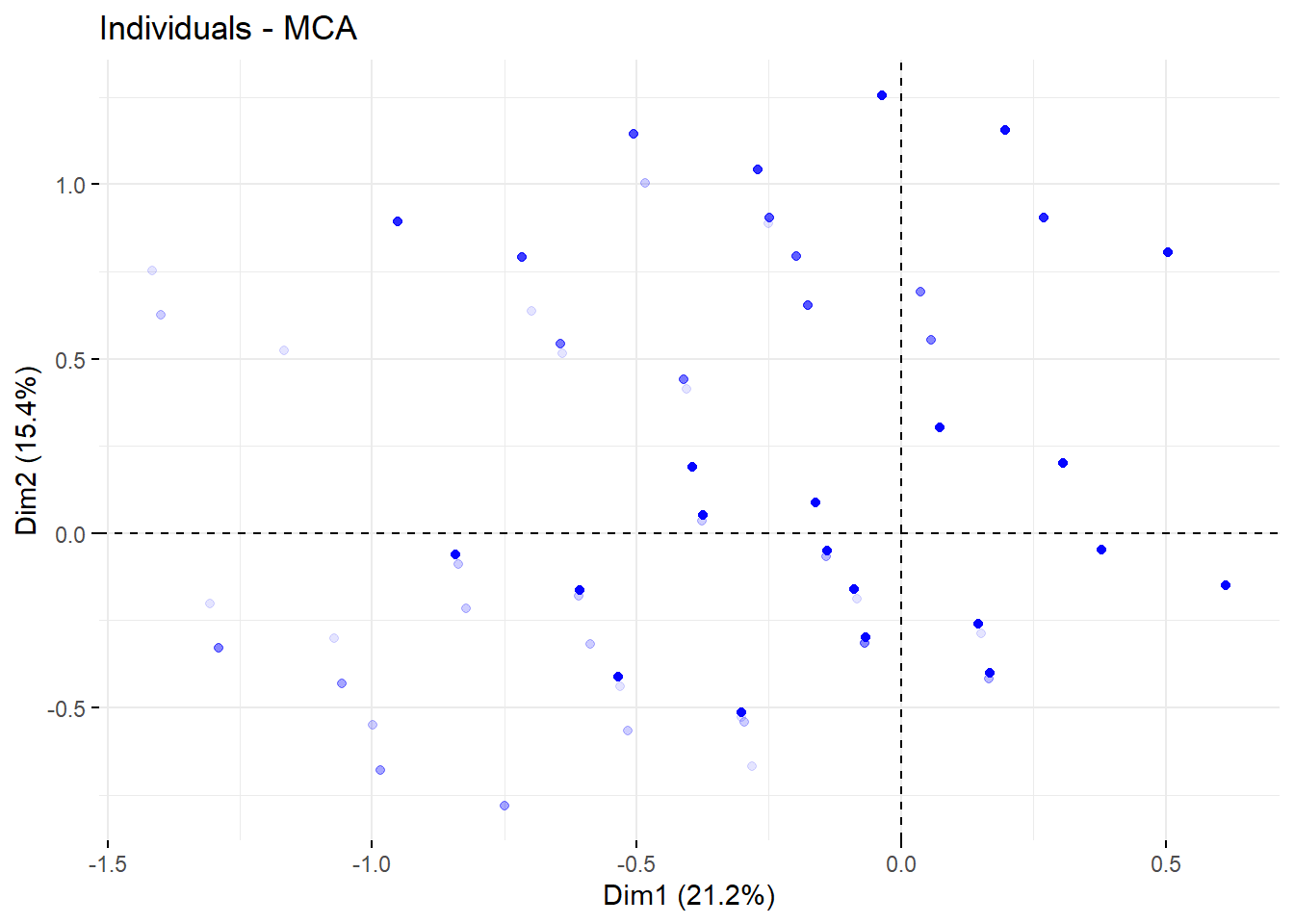
Le graphique sera un peu plus lisible en n’affichant que les points avec un effet de transparence (pour les points superposés).
Figure 42.7: Projection des individus dans le plan factoriel
Il est souvent intéressant de colorier les individus selon une variable catégorielle tierce, que ce soit une des variables ayant contribué ou non à l’ACM. Par exemple, nous allons regarder la répartition des individus dans le plan factoriel selon leur pratique d’un sport, puisque cette variable contribuait fortement au premier axe.
Nous indiquerons la variable considérée à factoextra::fviz_mca_in() via l’argument habillage. L’option addEllipses = TRUE permet de dessiner des ellipses autour des observations.
Figure 42.8: Projection des individus dans le plan factoriel selon la pratique d’un sport
Astuce
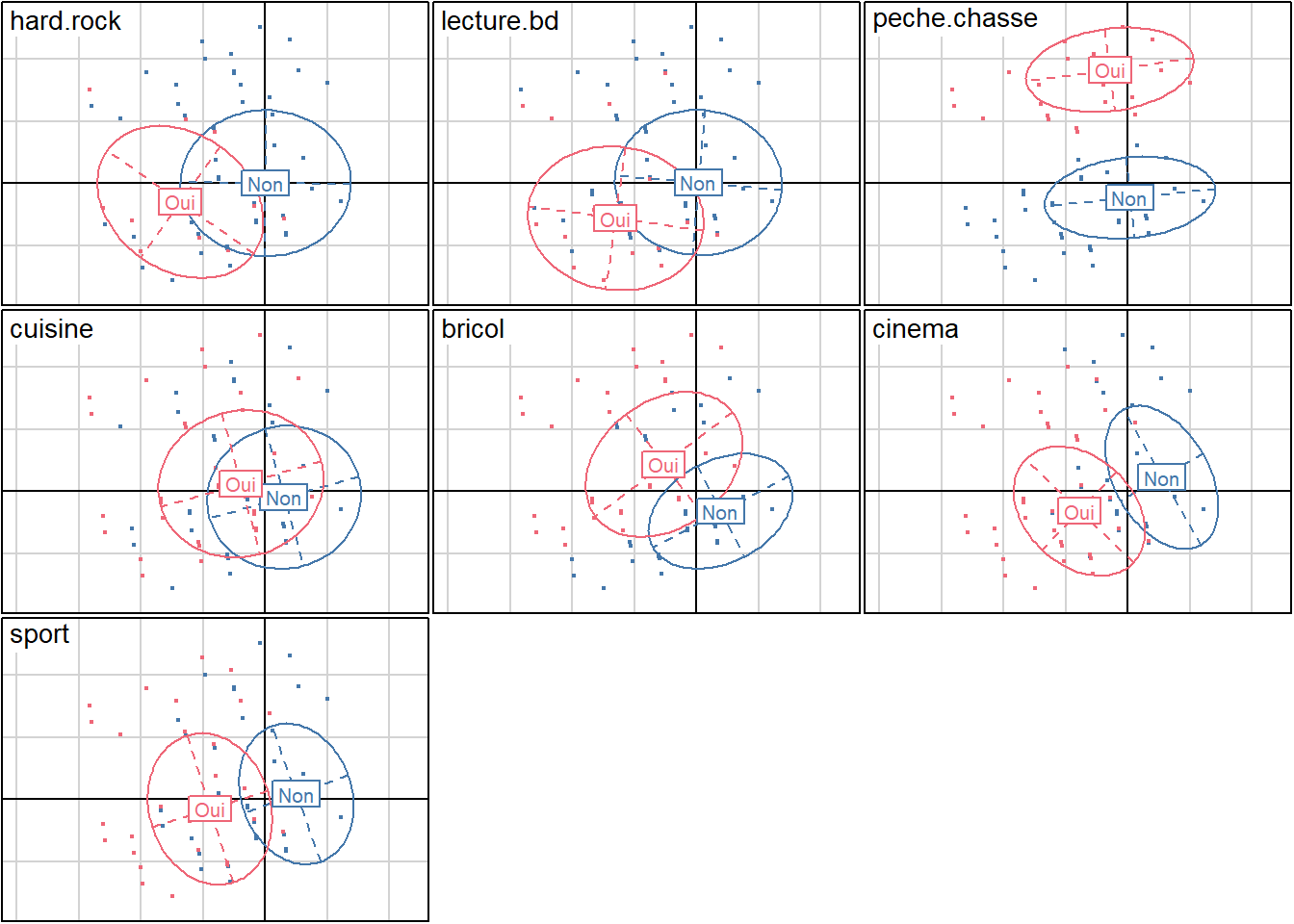
Si l’on a réalisé l’ACM avec {ade4}, nous pouvons utiliser la fonction ade4::scatter() pour réaliser ce même type de graphique avec l’ensemble des variables inclues dans l’ACM. Afin de rendre le graphique plus lisible, nous passons à la fonction une palette de couleur obtenue avec khroma::colour() (cf. Section 16.3.2).
42.2.8 Récupérer les coordonnées des individus / des variables
Dans certaines situations (par exemple pour créer un score à partir de la position sur le premier axe), on peut avoir besoin de récupérer les données brutes de l’analyse factorielle.
On pourra utiliser les fonctions get_*() de {factoextra}. Par exemple, pour les individus dans le cadre d’une ACM, on utilisera factoextra::get_mca_ind().
res <- acm1_ad |> factoextra::get_mca_ind()print(res)
Multiple Correspondence Analysis Results for individuals
===================================================
Name Description
1 "$coord" "Coordinates for the individuals"
2 "$cos2" "Cos2 for the individuals"
3 "$contrib" "contributions of the individuals"
Le résultat obtenu est une liste avec trois tableaux de données. Pour accéder aux coordonnées des individus, il suffit donc d’exécuter la commande ci-dessous.
42.3 Ajout de variables / d’observations additionnelles
Dans le cadre d’une analyse factorielle, on peut souhaiter ajouter des variables ou des observations additionnelles, qui ne participeront donc pas au calcul de l’analyse factorielle (et seront donc sans effet sur les axes de l’analyse). Ces variables / observations additionnelles seront simplement projetées dans le nouvel espace factoriel.
Reprenons notre exemple et calculons des groupes d’âges.
hdv2003 <- hdv2003 |>mutate(groupe_ages = age |>cut(c(18, 25, 45, 65, 99),right =FALSE,include.lowest =TRUE,labels =c("18-24 ans", "25-44 ans","45-64 ans", "65 ans et plus") ) )
Ajoutons maintenant le sexe, le groupe d’âges et le niveau d’étude comme variables additionnelles.
Avec {FactoMineR}, cela se fait directement au moment du calcul de l’ACM, en indiquant l’index (ordre de la colonne dans le tableau) des variables supplémentaires à quali.sup pour les variables catégorielles et à quanti.sup pour les variables continues. De même, ind.sup peut-être utilisé pour indiquer les observations additionnelles.
Avec {ade4}, la manipulation est légèrement différente. Le calcul de l’ACM se fait comme précédemment, uniquement avec les variables et les observations inclues dans l’analyse, puis on pourra projeter dans l’espace factoriel les variables / observations additionnelles à l’aide de ade4::supcol() et ade4::suprow(). Si pour ajouter des observations additionnelles il suffit de passer l’ACM de base et un tableau de données des observations additionnelles à ade4::suprow(), c’est un peu plus compliqué pour des variables additionnelles. Il faut déjà réaliser une ACM sur ces variables additionnelles, en extraire le sous objet $tab et passer ce dernier à ade4::supcol().
Si l’on veut pouvoir utiliser explor::explor() avec ces variables additionnelles, il faudra enregistrer le résultat de ade4::supcol() dans un sous-objet $supv de l’ACM principale.
acm2_ad <- acm1_adacm2_ad$supv <- acm_supp
Pour des représentations graphiques avec {factoextra}, on privilégiera ici le calcul avec {FactoMineR} (les variables additionnelles calculées avec {ade4} n’étant pas gérées par {factoextra}). En effet, si l’ACM a été calculée avec {FactoMineR}, factoextra::fviz_mca_var() affiche par défaut les variables ad
Figure 42.9: Projection des modalités dans le plan factoriel (incluant les variables additionnelles)
42.4 Gestion des valeurs manquantes
Pour ce troisième exemple, nous allons maintenant inclure les variables sexe, groupe d’âges et niveau d’étude dans l’ACM, non pas comme variables additionnelles mais comme variables de l’ACM (qui vont donc contribuer au calcul des axes).
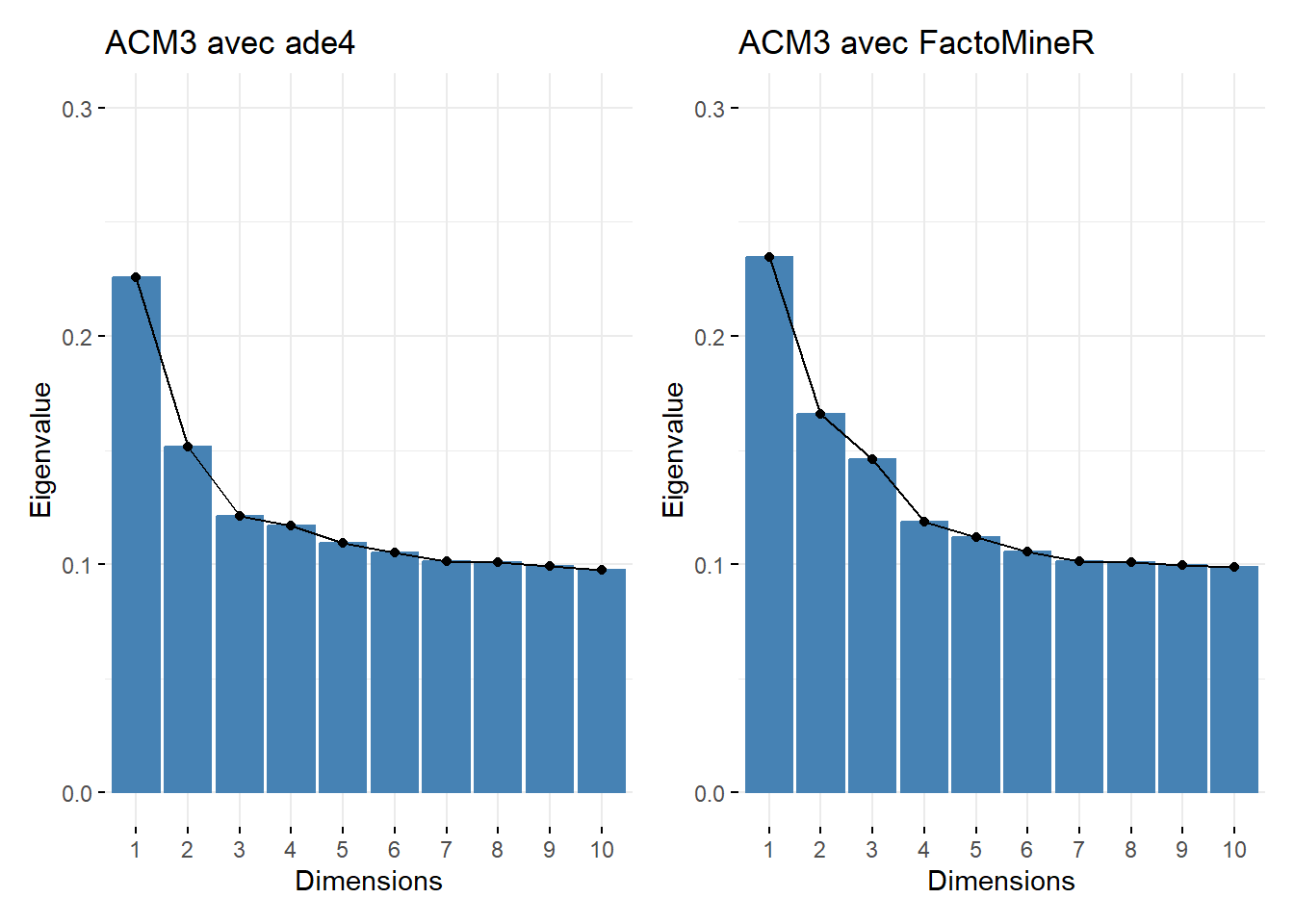
Regardons les valeurs propres et l’inertie expliquée et positionnons les deux graphiques côte à côte (cf. Section 17.6 sur la combinaison de graphiques).
p_ad <- acm3_ad |> factoextra::fviz_screeplot(choice ="eigenvalue") + ggplot2::ggtitle("ACM3 avec ade4")
Warning in geom_bar(stat = "identity", fill = barfill, color = barcolor, :
Ignoring empty aesthetic: `width`.
p_fm<- acm3_fm |> factoextra::fviz_screeplot(choice ="eigenvalue") + ggplot2::ggtitle("ACM3 avec FactoMineR")
Warning in geom_bar(stat = "identity", fill = barfill, color = barcolor, :
Ignoring empty aesthetic: `width`.
Figure 42.10: Inertie expliquée par axe (comparaison des ACM réalisées avec ade4 et FactoMineR)
Comme nous pouvons le voir, cette fois-ci, l’inertie expliquée par axe diffère entre les deux ACM. Cela est du à la présence de valeurs manquantes pour la variable nivetud.
Or, les deux packages ne traitent pas les valeurs manquantes de la même manière : {ade4} exclue les valeurs manquantes tandis que {FactoMineR} les considère comme une modalité additionnelle.
Pour éviter toute ambiguïté, il est préférable de traiter soi-même les valeurs manquantes (NA) en amont des deux fonctions.
Pour convertir les valeurs manquantes d’un facteur en une modalité en soi, on utilisera forcats::fct_na_value_to_level(). Il est possible d’appliquer cette fonction à tous les facteurs d’un tableau de données avec dplyr::across() (cf. Chapitre 40).
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `across(where(is.factor), fct_na_value_to_level, level =
"(manquant)")`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))
Une alternative est offerte par le package {GDAtools} qui implémente une ACM spécifique permettant de neutraliser certaines modalités dans la construction de l’espace factoriel, tout en conservant l’ensemble des individus. Les valeurs manquantes sont automatiquement considérées comme des modalités à ne pas tenir compte. Mais il est également possible d’indiquer d’autres modalités à ignorer (voir le tutoriel du package).
acm3_spe <- GDAtools::speMCA(d3)
Si les fonctions de {factorextra} ne sont pas compatibles avec {GDAtools}, on peut tout à fait utiliser {explor}. De plus, {GDAtools} fournit directement plusieurs outils de visualisation avancée et d’aide à l’interprétation des résultats.
42.5 webin-R
L’analyse factorielle est présentée sur YouTube dans le webin-R #11 (Analyse des Correspondances Multiples (ACM)).