48 Modèles de comptage (Poisson & apparentés)
Une variable de type comptage
correspond à un outcome (variable à expliquer) entier positif. Le plus souvent, il s’agit du nombre d’occurrences de l’évènement d’intérêt. Pour expliquer une variable de ce type, les modèles linéaires ou les régressions logistiques ne sont pas adaptées. On aura alors recours à des modèles ou régressions de Poisson, c’est-à-dire de manière plus spécifique à un modèle linéaire généralisé (GLM en anglais), avec une fonction de lien logarithmique et une distribution statistique de Poisson.
Les modèles de Poisson font l’hypothèse que la variance est égale à la moyenne, ce qui ne s’observe pas toujours. Auquel cas on aura alors un problème de surdispersion. Dans ce cas-là, nous pourrons avoir recours à des modèles apparentés aux modèles de Poisson, à savoir les modèles quasi-Poisson, les modèles binomiaux négatifs.
Les modèles de comptage peuvent aussi être utiliser pour un outcome binaire, en lieu et place d’une régression logistique, afin d’estimer des prevalence ratios plutôt que des odds ratios.
Enfin, lorsqu’il y a un nombre important de 0 dans les données à expliquer, on peut avoir recours à des modèles zero-inflated ou des modèles hurdle qui, d’une certaine manière, combinent deux modèles en un (d’une part la probabilité de vivre l’évènement et d’autre part le nombre d’occurrences de l’évènement).
48.1 Modèle de Poisson
Nous allons nous intéresser à un premier exemple démographique en nous intéressant à la descendance atteinte par des femmes à l’âge de 30 ans.
48.1.1 Préparation des données du premier exemple
Pour cet exemple, nous allons considérer le jeu de données fecondite fourni par le package {questionr}. Ce jeu de données comprends trois tables de données (menages, femmes et enfants) simulant les résultats d’une enquête démographique et de santé (EDS). Chargeons les données et jetons y un œil avec labelled::look_for().
pos variable label col_type missing values
1 id_enfant Identifiant de l'enfant dbl 0
2 id_femme Identifiant de la mère dbl 0
3 date_naissance Date de naissance date 0
4 sexe Sexe de l'enfant dbl+lbl 0 [1] masculin
[2] féminin
5 survie L'enfant est-il toujours en~ dbl+lbl 0 [0] non
[1] oui
6 age_deces Age au décès (en mois) dbl 1442 Comme nous pouvons le voir, les variables catégorielles sont codées sous la forme de vecteurs numériques labellisés (cf. Chapitre 12), comme cela aurait été le cas si nous avions importé un fichier Stata ou SPSS avec {haven}. Première étape, nous allons convertir à la volée
ces variables catégorielles en facteurs avec labelled::unlabelled().
Pour notre analyse, nous allons devoir compter le nombre d’enfants que chaque femme a eu avant l’âge de 30 ans exacts. En premier lieu, nous devons calculer l’âge (cf. Section 35.4) de la mère à la naissance dans le tableau enfants, à l’aide de la fonction lubridate::time_length().
Comptons maintenant, par femme, le nombre d’enfants nés avant l’âge de 30 ans et ajoutons cette valeur à la table femmes. N’oublions, après la fusion, de recoder les valeurs manquantes NA en 0 avec tidyr::replace_na().
Il nous reste à calculer l’âge des femmes au moment de l’enquête. Nous allons en profiter pour recoder (cf. Section 9.3) la variable éducation en regroupant les modalités secondaire
et supérieur
.
Enfin, pour l’analyse, nous n’allons garder que les femmes âgées d’au moins 30 ans au moment de l’enquête. En effet, les femmes plus jeunes n’ayant pas encore atteint 30 ans, nous ne connaissons pas leur descendance atteinte à cet âge.
48.1.2 Statistiques descriptives
Avant de réaliser un modèle multivariable, il est toujours bon de réaliser au préalable des analyses bivariées. Notre outcome étant numérique, nous pouvons comparer sa moyenne selon nos différentes variables catégorielles.
Pour cela, nous aurons recours à gtsummary::tbl_continuous() (une variante de gtsummary::tbl_summary().
Setting theme "language: fr"| Caractéristique | N = 8041 |
|---|---|
| Niveau d'éducation | |
| aucun | 0,25 (0,61) |
| primaire | 0,30 (0,62) |
| secondaire/supérieur | 0,11 (0,32) |
| Milieu de résidence | |
| urbain | 0,18 (0,49) |
| rural | 0,28 (0,63) |
| Région de résidence | |
| Nord | 0,22 (0,51) |
| Est | 0,31 (0,65) |
| Sud | 0,28 (0,74) |
| Ouest | 0,20 (0,49) |
| 1 Nombre d’enfants nés avant 30 ans exact: Moyenne (ET) | |
Le nombre d’observations par ligne n’est pas directement accessible peut s’ajouter aisément en utilisant {length}. De même, il n’y a pas de méthode add_ci() pour les objets tbl_continuous mais nous pouvons définir nos propres fonctions pour calculer, à l’aide de t.test() (cf. Section 18.4.2). Enfin, calculons des p-valeurs avec gtsummary::add_p() et en utilisant une ANOVA à un facteur (qui permet de prendre en compte des variables explicatives à plus de deux modalités).
ci_low <- function(x, conf.level = 0.95) {
t.test(x, conf.level = conf.level)$conf.int[1]
}
ci_high <- function(x, conf.level = 0.95) {
t.test(x, conf.level = conf.level)$conf.int[2]
}
femmes30p |>
tbl_continuous(
variable = enfants_avt_30,
include = c(educ2, milieu, region),
statistic = ~ "{mean} [{ci_low} - {ci_high}] ({sd}) [n={length}]",
digits = ~ c(2, 2, 2, 2, 0)
) |>
add_p(test = ~ "oneway.test") |>
bold_labels()| Caractéristique | N = 8041 | p-valeur2 |
|---|---|---|
| Niveau d'éducation | <0,001 | |
| aucun | 0,25 [0,20 - 0,30] (0,61) [n=534] | |
| primaire | 0,30 [0,20 - 0,39] (0,62) [n=171] | |
| secondaire/supérieur | 0,11 [0,05 - 0,17] (0,32) [n=99] | |
| Milieu de résidence | 0,012 | |
| urbain | 0,18 [0,12 - 0,23] (0,49) [n=307] | |
| rural | 0,28 [0,22 - 0,34] (0,63) [n=497] | |
| Région de résidence | 0,3 | |
| Nord | 0,22 [0,16 - 0,28] (0,51) [n=300] | |
| Est | 0,31 [0,20 - 0,43] (0,65) [n=118] | |
| Sud | 0,28 [0,17 - 0,39] (0,74) [n=178] | |
| Ouest | 0,20 [0,13 - 0,26] (0,49) [n=208] | |
| 1 Nombre d’enfants nés avant 30 ans exact: Moyenne [ci_low - ci_high] (ET) [n=length] | ||
| 2 One-way analysis of means (not assuming equal variances) | ||
48.1.3 Calcul & Interprétation du modèle de Poisson
Les modèles de Poisson font partie de la famille des modèles linéaires généralisés (GLM en anglais) et se calculent dont avec la fonction stats::glm() en précisant family = poisson.
L’ensemble des fonctions et méthodes applicables aux modèles GLM, que nous avons déjà abordé dans le chapitre sur la régression logistique (cf. Chapitre 23), peuvent s’appliquer également aux modèles de Poisson. Nous pouvons par exemple réduire notre modèle par minimisation de l’AIC avec stats::step().
Start: AIC=1013.81
enfants_avt_30 ~ educ2 + milieu + region
Df Deviance AIC
- region 3 686.46 1010.6
<none> 683.62 1013.8
- milieu 1 686.84 1015.0
- educ2 2 691.10 1017.3
Step: AIC=1010.65
enfants_avt_30 ~ educ2 + milieu
Df Deviance AIC
<none> 686.46 1010.6
- milieu 1 691.30 1013.5
- educ2 2 693.94 1014.1Par défaut, les modèles de Poisson utilisent une fonction de lien logarithmique (log). Dès lors, il est fréquent de ne pas présenter directement les coefficients du modèle, mais plutôt l’exponentielle de leurs valeurs qui peut s’interpréter comme des risques relatifs
(relative risks ou RR)1. L’exponentielle des coefficients peut aussi être appelée incidence rate ratio (IRR) car la régression de Poisson peut également être utilisée pour des modèles d’incidence, qui seront abordés dans le prochain chapitre (cf. Chapitre 49).
1 À ne pas confondre avec les odds ratio ou OR de la régression logistique.
Pour un tableau mis en forme des coefficients, on aura tout simplement recours à {gtsummary} et sa fonction gtsummary::tbl_regression().
| Caractéristique | IRR | 95% IC | p-valeur |
|---|---|---|---|
| Niveau d'éducation | |||
| aucun | — | — | |
| primaire | 1,25 | 0,90 – 1,72 | 0,2 |
| secondaire/supérieur | 0,53 | 0,27 – 0,96 | 0,052 |
| Milieu de résidence | |||
| urbain | — | — | |
| rural | 1,42 | 1,04 – 1,98 | 0,032 |
| Abréviations: IC = intervalle de confiance, IRR = rapport de taux d’incidence | |||
Pour une représentation graphique, on pourra avoir recours à ggstats::ggcoef_model() ou ggstats::ggcoef_table().
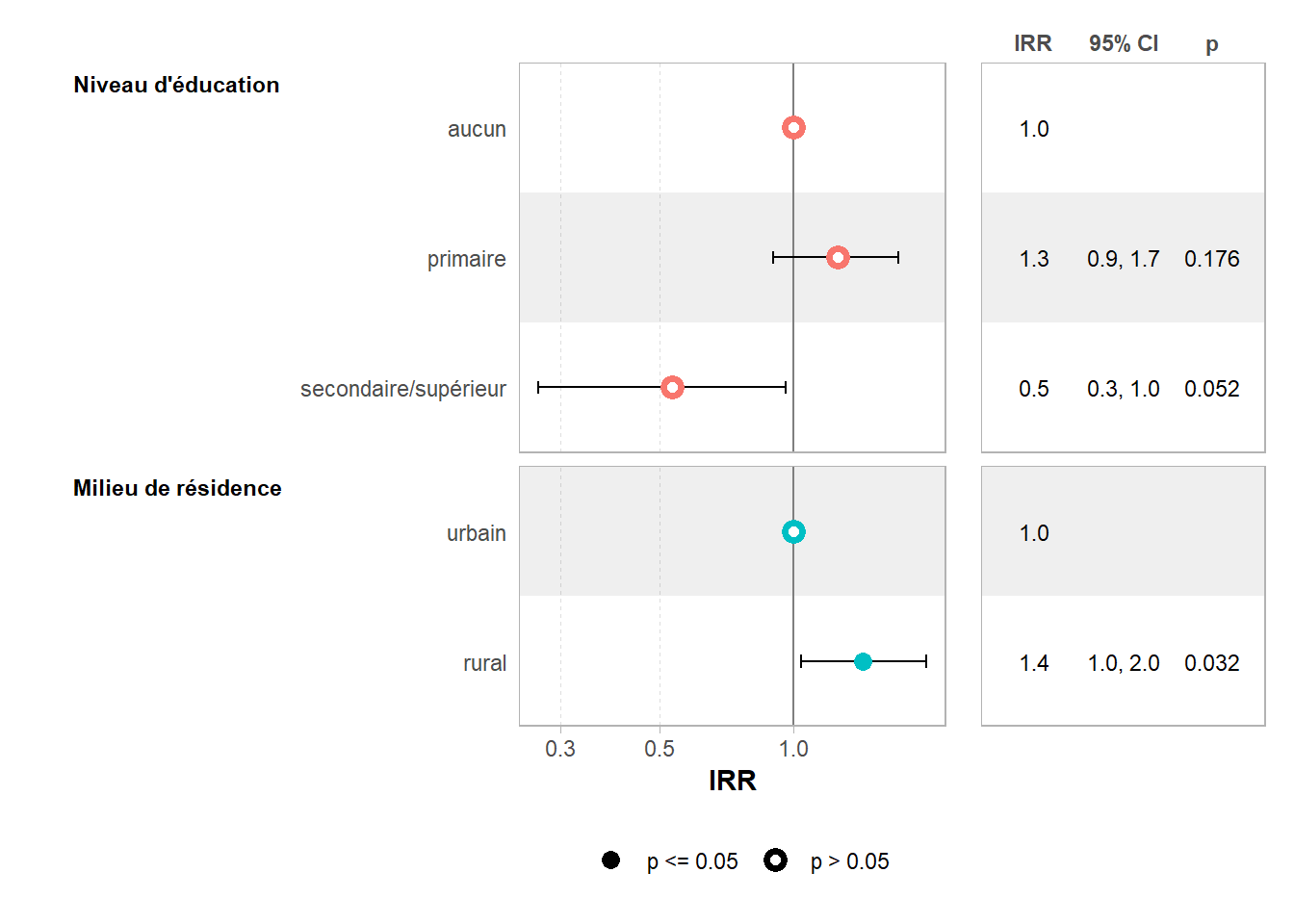
Pour interpréter les coefficients, il faut se rappeler que ce qui est modélisé dans le modèle de Poisson est le nombre moyen d’évènements. Le RR pour la modalité secondaire/supérieur
est de 0,5 : cela signifie donc que, indépendamment des autres variables du modèle, la descendance atteinte à 30 ans moyenne des femmes de niveau secondaire ou supérieure est moitié moindre que celle des femmes sans niveau d’éducation (modalité de référence).
Nous pouvons vérifier visuellement ce résultat en réalisant un graphique des prédictions marginales moyennes avec broom.helpers::plot_marginal_predictions() (cf. Section 25.3).
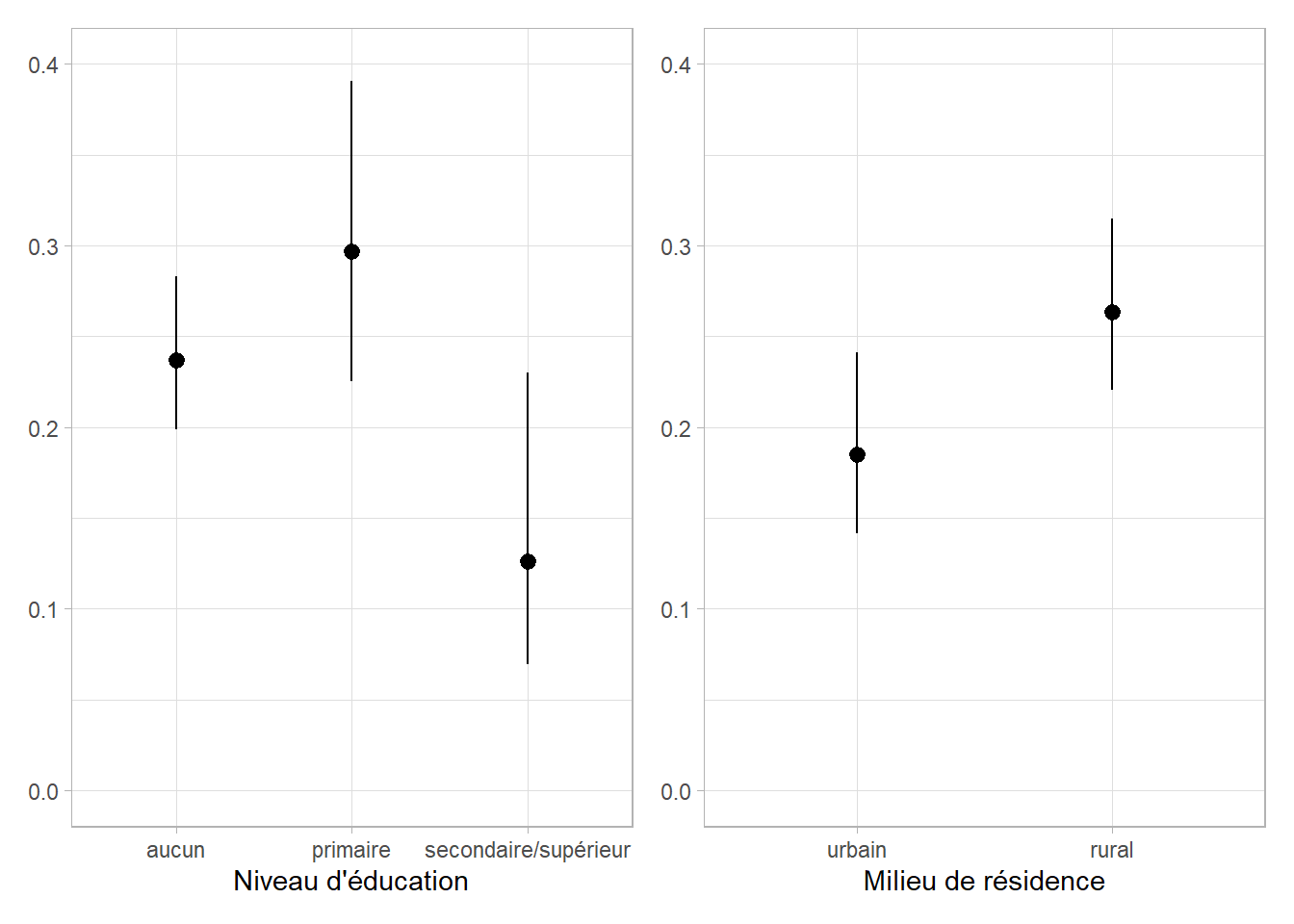
48.1.4 Évaluation de la surdispersion
Comme tous les modèles GLM, le modèle de Poisson présuppose que les observations sont indépendantes les unes des autres2. Surtout, la distribution de Poisson présuppose que la variance est égale à la moyenne. Or, il arrive fréquemment que la variance soit supérieure à la moyenne, auquel cas on parle alors de surdispersion. Si c’est le cas, le modèle de Poisson va sous-estimer la variance et produire des intervalles de confiance trop petit et des p-valeurs trop petites.
2 Si ce n’était pas le cas, par exemple s’il y a plusieurs observations pour un même individu, il faudrait adopter un autre type de modèle, par exemple un modèle mixte ou un modèle GEE, pour lesquels il est possible d’utiliser une distribution de Poisson.
En premier lieu, nous pouvons vérifier si la distribution observée des données correspond peu ou prou à la distribution théorique de Poisson pour une moyenne correspondant à la moyenne observée.
Le package {guideR}, compagnon de guide-R, propose une fonction guideR::observed_vs_theoretical() qui permet justement de comparer la distribution observée avec la distribution théorique d’un modèle.
Appliquons cette fonction à notre modèle de Poisson.
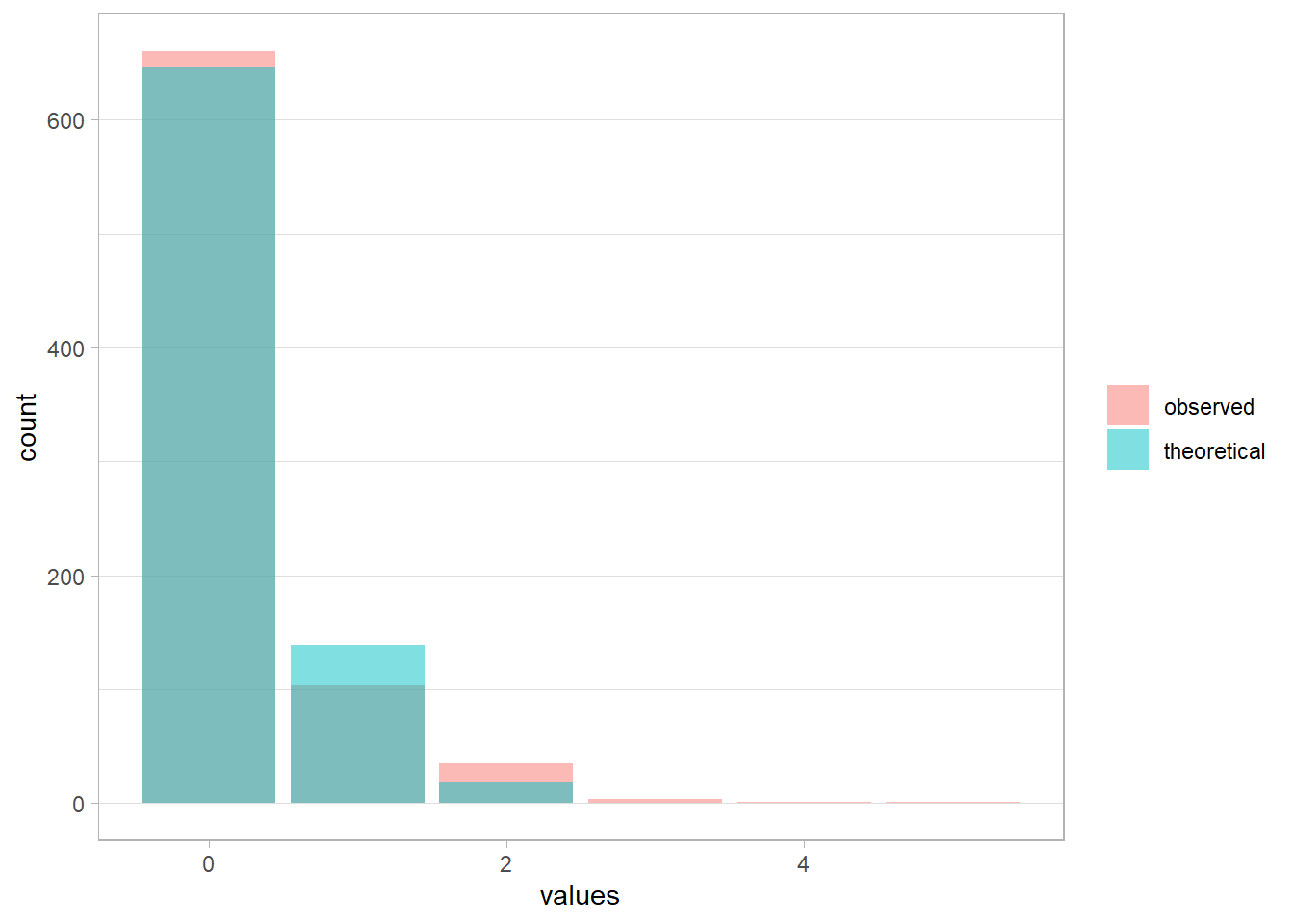
Les deux distributions restent assez proches même si la distribution observée est légèrement décalée vers la droite.
La fonction performance::check_predictions() propose une visualisation un peu plus avancée3.
Le chargement a nécessité le package : seeIgnoring unknown labels:
• size : ""
• alpha : ""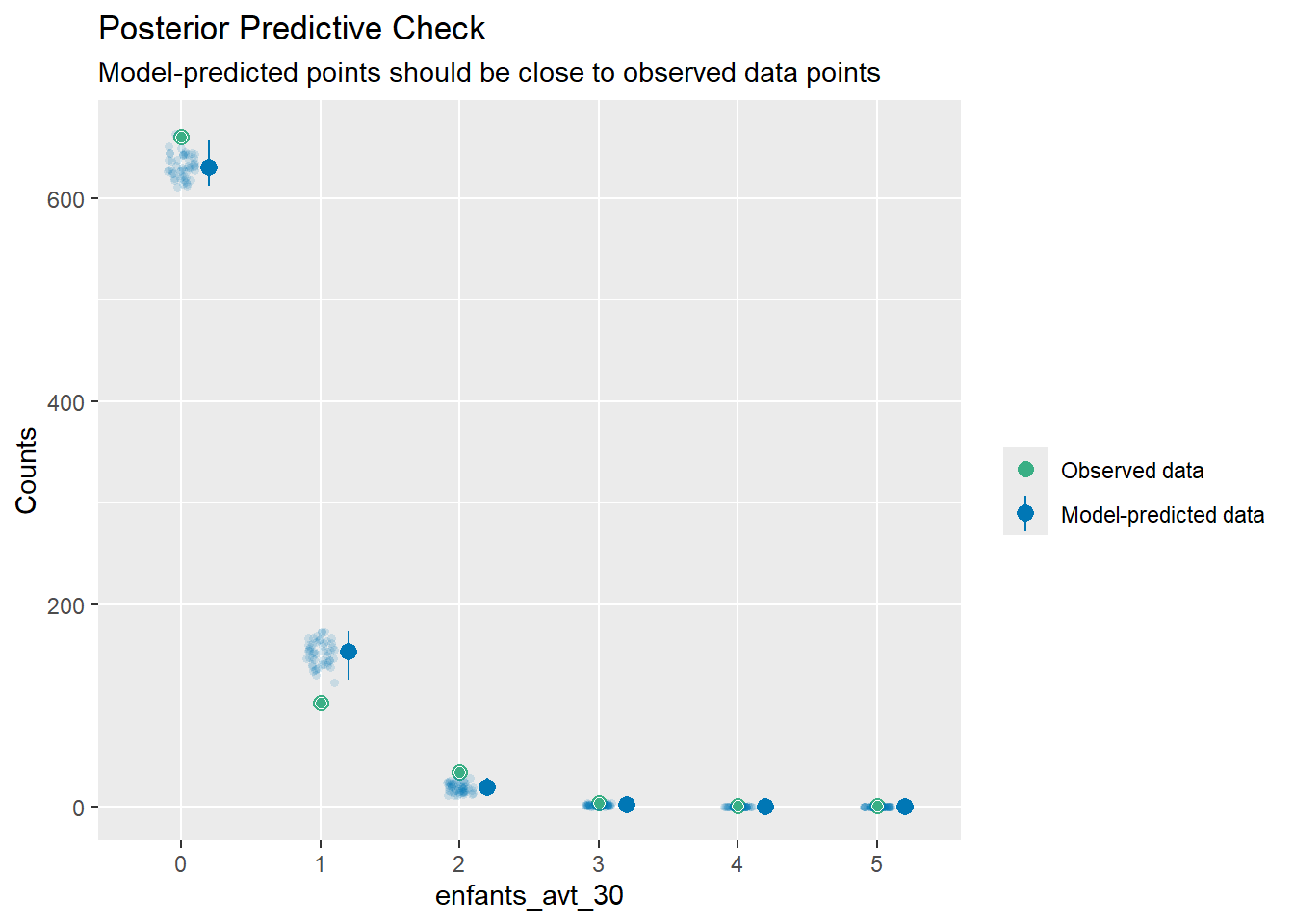
Les points verts correspondent au nombre d’individus observés (sur l’axe vertical) pour chaque valeur de notre variable à expliquer (sur l’axe horizontal). La fonction simule ensuite une cinquantaine de jeu de données par réplication et affiche les prédictions du modèle pour ces jeux de données (points bleus avec effet de transparence), ainsi que les prédictions médianes (point bleu sans transparence) et l’intervalle des prédictions (barres verticales).
Dans notre exemple, on voit notamment que le modèle a du mal à prédire correctement le nombre d’individus avec 0, 1 ou 2 enfants.
3 Il est nécessaire d’installer le package {see} pour pouvoir afficher le graphique produit.
Le paramètre φ (phi) qui correspond au ratio entre la variance observée et la variance théorique peut être estimée, en pratique, selon certains auteurs, comme le ratio de la déviance résiduelle sur le nombre de degrés de libertés du modèle. Il s’obtient ainsi :
Si ce ratio s’écarte de 1, alors il y a un problème de surdispersion. Cependant, en pratique, il n’y a pas de seuil précis à partir duquel nous pourrions conclure qu’il faut rejeter le modèle.
La package {AER} propose un test, AER::dispersiontest(), pour tester s’il y a un problème de surdispersion. Ce test ne peut s’appliquer qu’à un modèle de Poisson.
Overdispersion test
data: mod1_poisson
z = 3.3367, p-value = 0.0004238
alternative hypothesis: true dispersion is greater than 1
sample estimates:
dispersion
1.361364 Le package {performance} propose, quant à lui, un test plus générale de surdispersion via la fonction performance::check_overdispersion().
# Overdispersion test
dispersion ratio = 1.371
Pearson's Chi-Squared = 1096.575
p-value = < 0.001Overdispersion detected.Dans les deux cas, nous obtenons une p-valeur inférieure à 0,001, indiquant que le modèle de Poisson n’est peut-être pas approprié ici.
48.2 Modèle de quasi-Poisson
Le modèle de quasi-Poisson est similaire au modèle de Poisson mais autorise plus de souplesse pour la modélisation de la variance qui est alors modélisée comme une relation linéaire de la moyenne. Il se calcule également avec stats::glm(), mais en indiquant family = quasipoisson. Comme avec le modèle de Poisson, la fonction de lien par défaut est la fonction logarithmique (log).
L’AIC (Akaike information criterion) n’est pas défini pour ce type de modèle. Il n’est donc pas possible d’utiliser stats::step() avec un modèle de quasi-Poisson. Si l’on veut procéder à une sélection pas à pas descendante, on procédera donc en amont avec un modèle de Poisson classique.
Regardons les résultats obtenus :
| Caractéristique | IRR | 95% IC | p-valeur |
|---|---|---|---|
| Niveau d'éducation | |||
| aucun | — | — | |
| primaire | 1,25 | 0,85 – 1,81 | 0,2 |
| secondaire/supérieur | 0,53 | 0,23 – 1,05 | 0,10 |
| Milieu de résidence | |||
| urbain | — | — | |
| rural | 1,42 | 0,99 – 2,10 | 0,067 |
| Abréviations: IC = intervalle de confiance, IRR = rapport de taux d’incidence | |||
Les coefficients sont identiques à ceux obtenus avec le modèle de Poisson (cf. Table 48.3), mais les intervalles de confiance sont plus larges et les p-valeurs plus élevées, traduisant la prise en compte d’une variance plus importante. Cela se voit aisément si l’on compare les coefficients avec ggstats::ggcoef_compare().4
4 Techniquement, si on l’applique à un modèle de quasi-Poisson, elle ne provoquera pas d’erreur mais renverra le même résultat qu’avec un modèle de Poisson classique. Voir https://github.com/easystats/performance/issues/734.
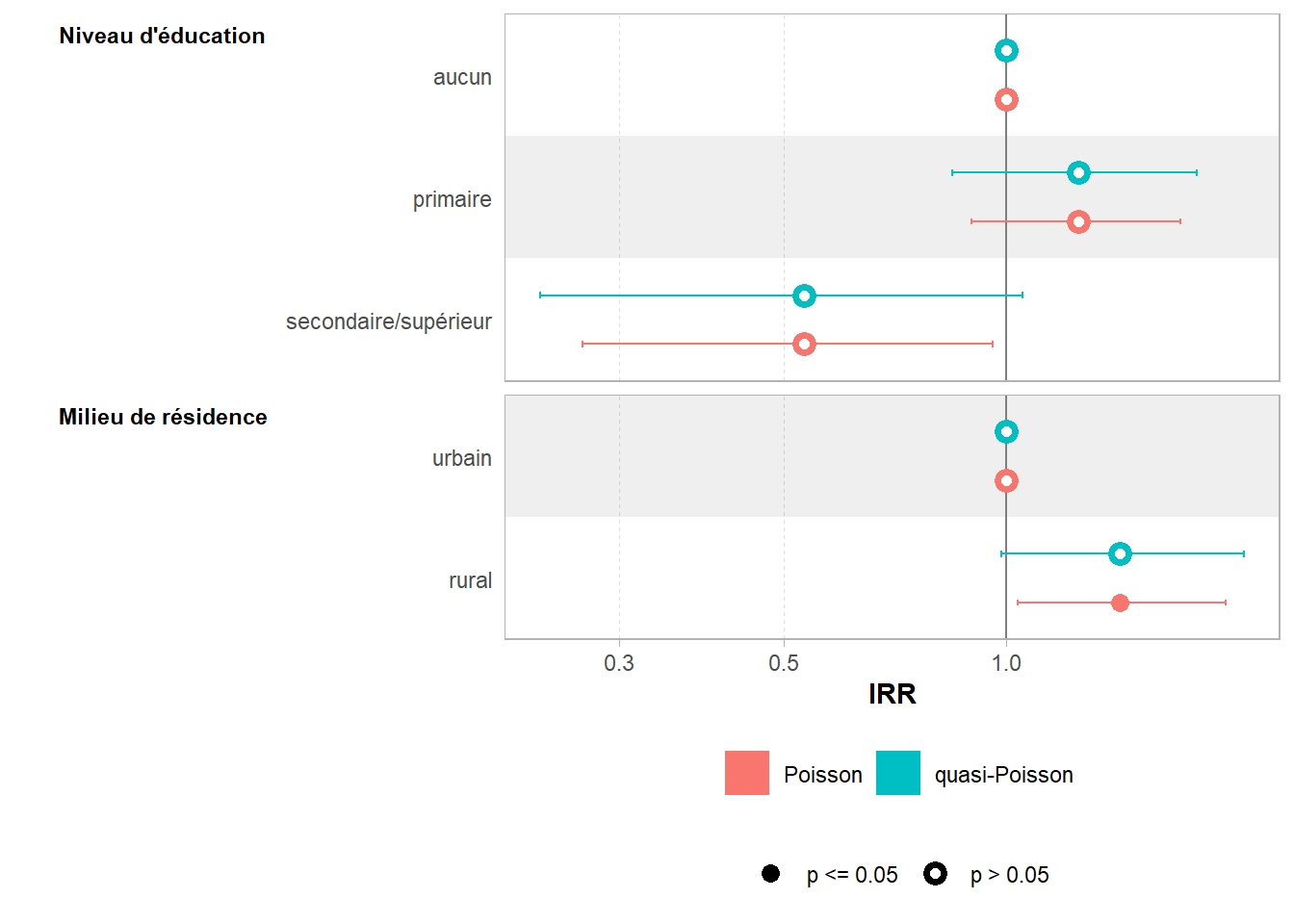
Le passage à un modèle de quasi-Poisson aura-t-il été suffisant pour régler notre problème de surdispersion ? La fonction performance::check_overdispersion() n’est pas adaptée aux modèles de quasi-Poisson. De plus, les fonctions performance::check_predictions() ou encore guideR::observed_vs_theoretical() ne fonctionnent pas avec les modèles de quasi-Poisson.
Il est de fait difficile de savoir le modèle de quasi-Poisson est suffisant pour corriger notre problème de surdispersion. En pratique, il est préférable de passer directement au modèle binomial négatif.
48.3 Modèle binomial négatif
Le modèle binomial négatif (negative binomial en anglais) modélise la variance selon une spécification quadratique (i.e. selon le carré de la moyenne). Il est implémenté dans le package {MASS} via la fonction MASS::glm.nb(). Les autres paramètres sont identiques à ceux de stats::glm().
L’AIC étant défini pour pour ce type de modèle, nous pouvons procéder à une sélection pas à pas avec stats::step().
Start: AIC=979.1
enfants_avt_30 ~ educ2 + milieu + region
Df Deviance AIC
- region 3 462.89 975.01
<none> 460.98 979.10
- milieu 1 463.29 979.41
- educ2 2 466.11 980.22
Step: AIC=975
enfants_avt_30 ~ educ2 + milieu
Df Deviance AIC
<none> 460.14 975.00
- milieu 1 463.37 976.24
- educ2 2 465.54 976.40La fonction de lien étant toujours logarithmique, nous pouvons donc afficher plutôt l’exponentielle des coefficients qui s’interprètent comme pour un modèle de Poisson.
| Caractéristique | IRR | 95% IC | p-valeur |
|---|---|---|---|
| Niveau d'éducation | |||
| aucun | — | — | |
| primaire | 1,23 | 0,82 – 1,82 | 0,3 |
| secondaire/supérieur | 0,53 | 0,25 – 1,03 | 0,074 |
| Milieu de résidence | |||
| urbain | — | — | |
| rural | 1,41 | 0,97 – 2,06 | 0,076 |
| Abréviations: IC = intervalle de confiance, IRR = rapport de taux d’incidence | |||
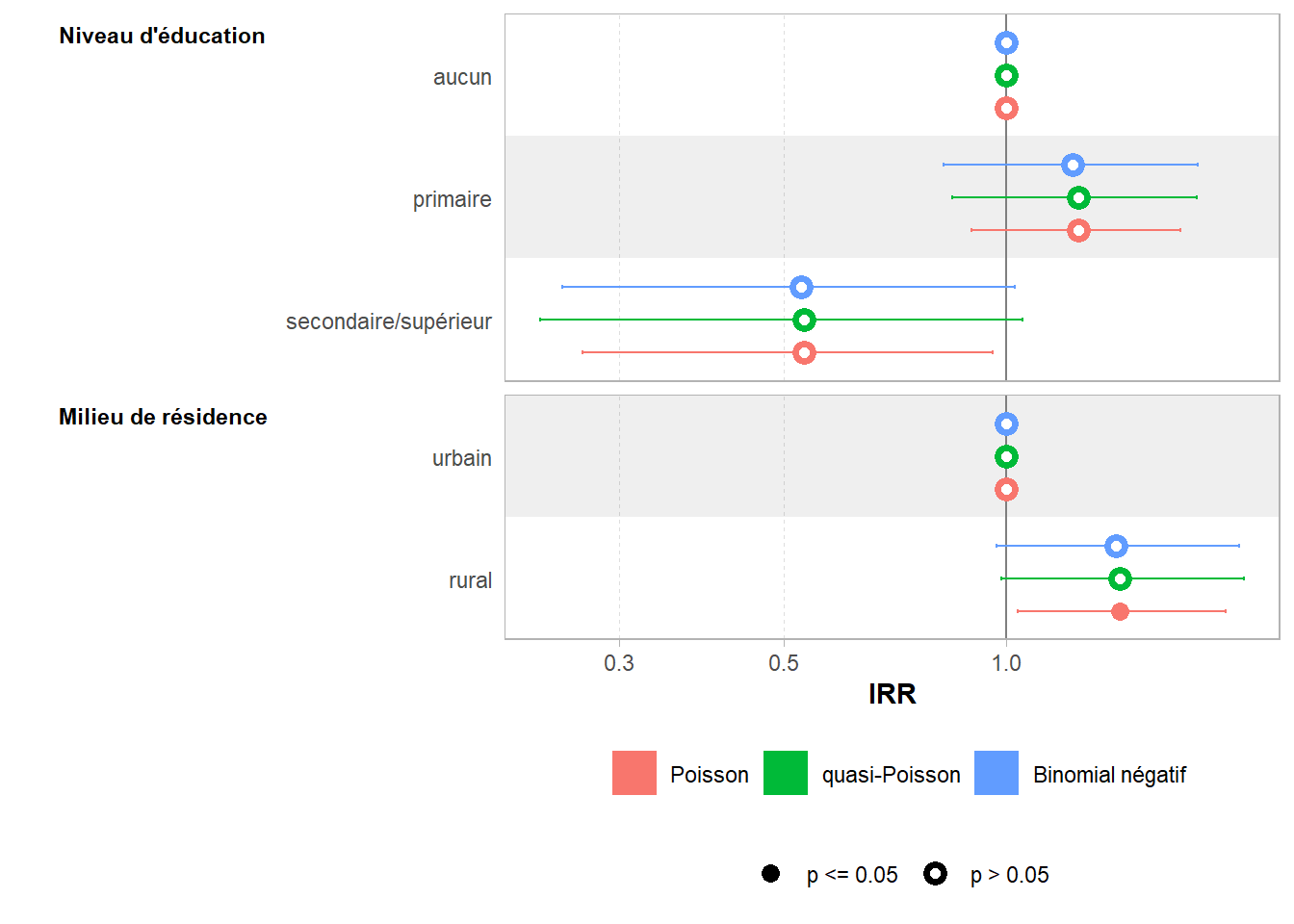
Cette fois-ci, les coefficients sont légèrement différents par rapport au modèle de Poisson, ce qui se voit aisément si l’on compare les trois modèles.
Nous pouvons comparer la distribution observée et la distribution théorique et constater que les prédictions sont plus proches des données observées.
Ignoring unknown labels:
• size : ""
• alpha : ""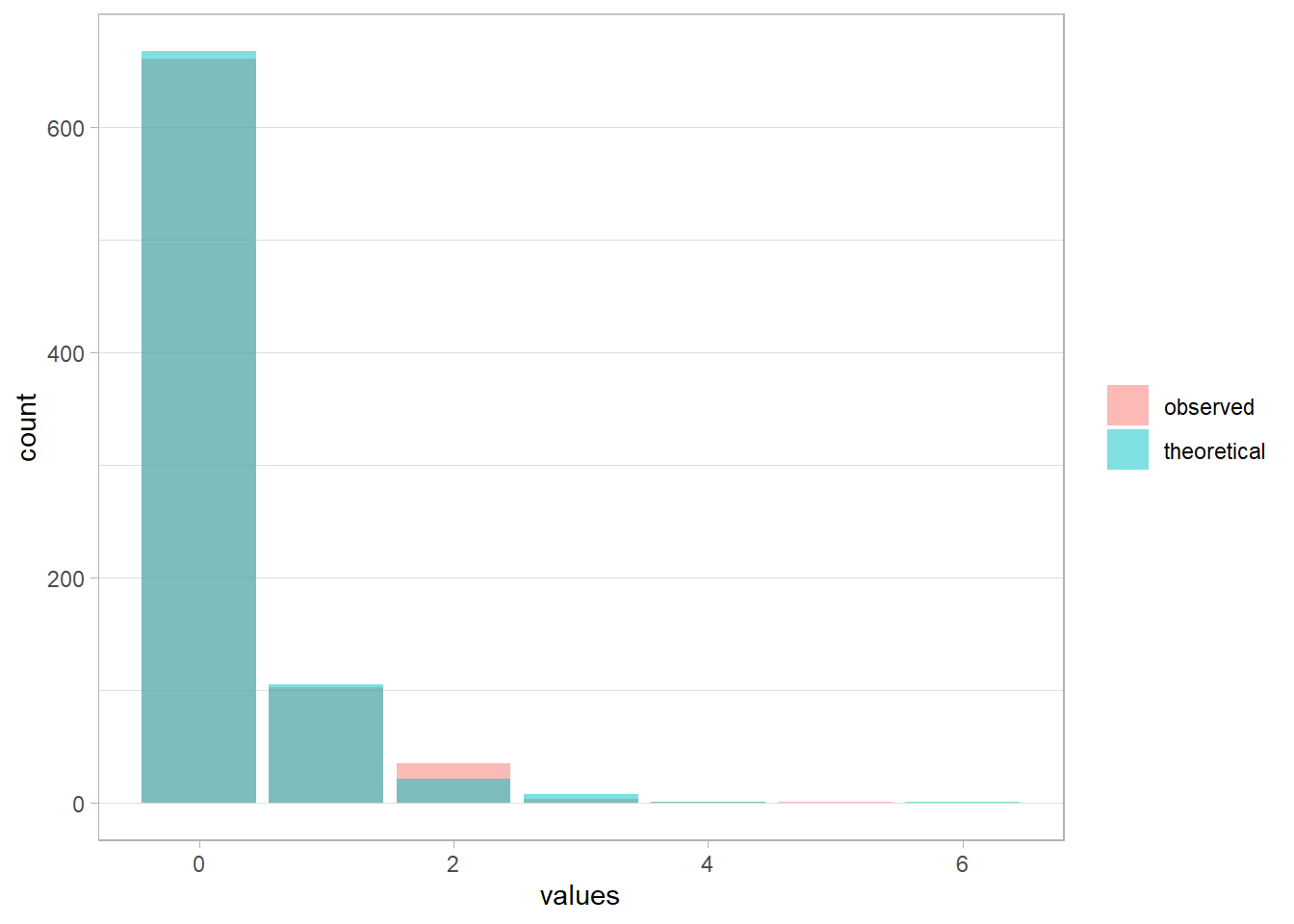
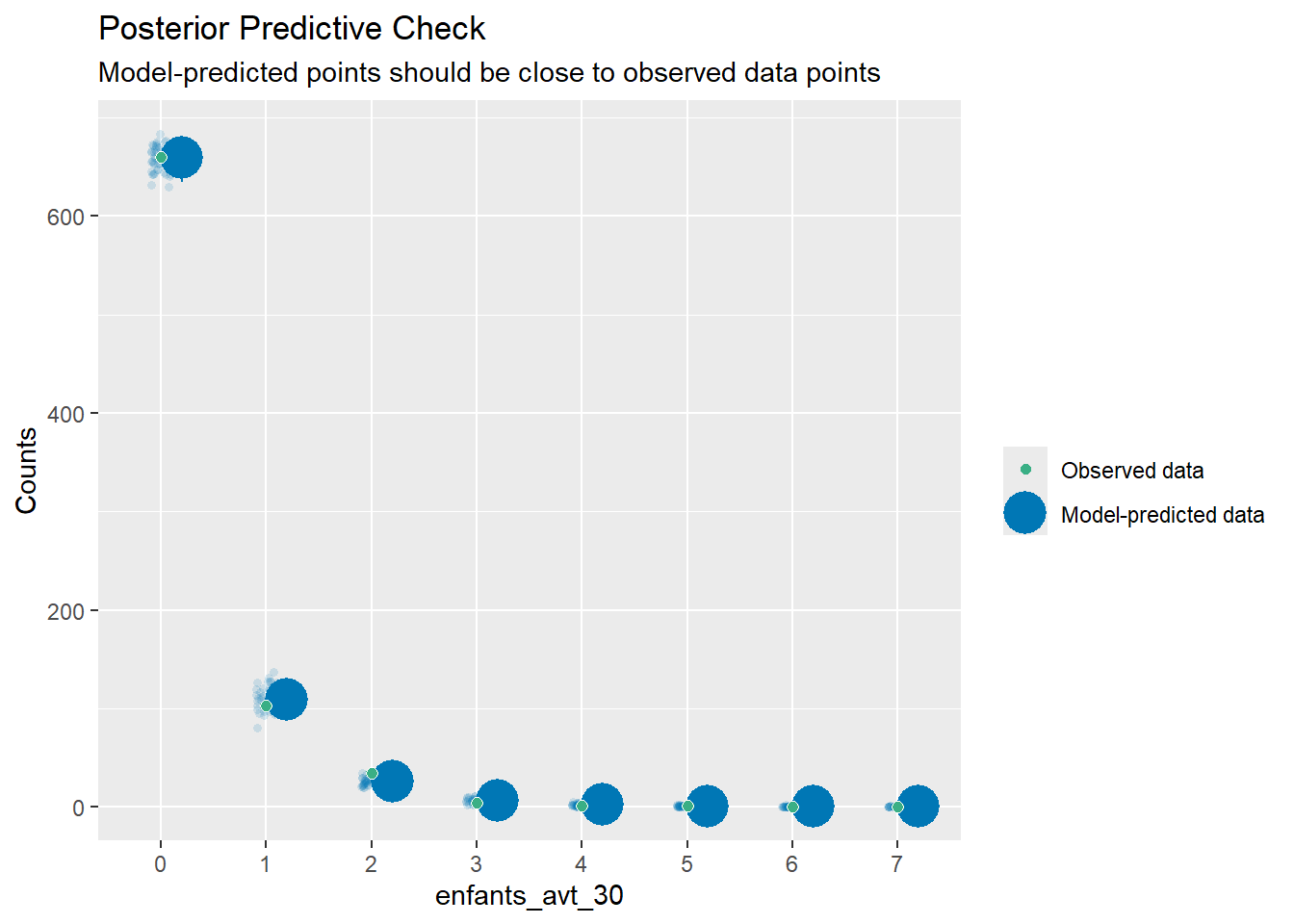
Nous pouvons vérifier la surdispersion.
# Overdispersion test
dispersion ratio = 0.975
p-value = 0.856No overdispersion detected.Ouf ! Nous n’avons plus de problème de surdispersion.
Pour celles et ceux intéressé·es, il est possible de comparer la performance des modèles avec la fonction performance::compare_performance().
# Comparison of Model Performance Indices
Name | Model | AIC (weights) | BIC (weights) | Nagelkerke's R2 | RMSE
---------------------------------------------------------------------------------
mod1_poisson | glm | 1010.7 (<.001) | 1029.4 (<.001) | 0.033 | 0.579
mod1_nb | negbin | 977.0 (>.999) | 1000.5 (>.999) | 0.032 | 0.57948.4 Exemple avec une plus grande surdispersion
Pour ce second exemple, nous allons considérer le jeu de données MASS::quine qui contient les données de 146 enfants scolarisés en Australie, notamment le nombre de jours d’absence à l’école au cours de l’année passée, le sexe l’enfant et leur vitesse d’apprentissage (dans la moyenne ou lentement).
Préparons les données en francisant les facteurs et en ajoutant des étiquettes de variable.
d <- MASS::quine |>
mutate(
jours = Days,
sexe = Sex |>
fct_recode(
"fille" = "F",
"garçon" = "M"
),
apprentissage = Lrn |>
fct_recode(
"dans la moyenne" = "AL",
"lentement" = "SL"
)
) |>
set_variable_labels(
jours = "Nombre de jours d'absence à l'école",
sexe = "Sexe de l'enfant",
apprentissage = "Vitesse d'apprentissage"
)Calculons notre modèle de Poisson.
Comparons les données observées avec les données prédites.
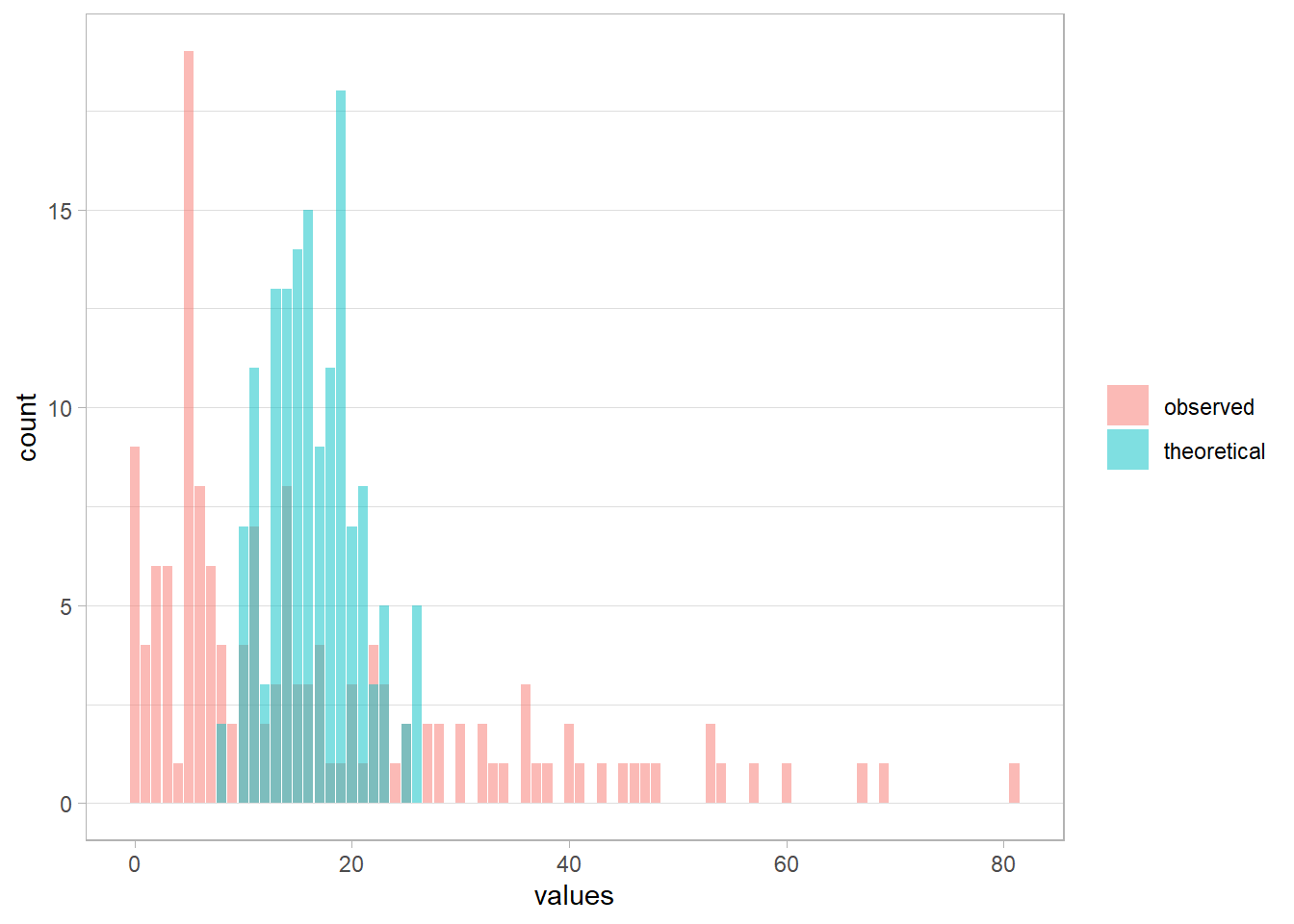
Nous voyons très clairement un décalage des deux distributions. Notre modèle de Poisson n’arrive pas à capturer la variabilité des observations. Faisons le test de surdispersion pour vérifier5.
5 Il est possible que l’installation du package {DHARMa} soit requise pour la bonne réalisation du test.
# Overdispersion test
dispersion ratio = 15.895
Pearson's Chi-Squared = 2273.046
p-value = < 0.001Overdispersion detected.Calculons un modèle binomial négatif et voyons si cela améliore la situation.
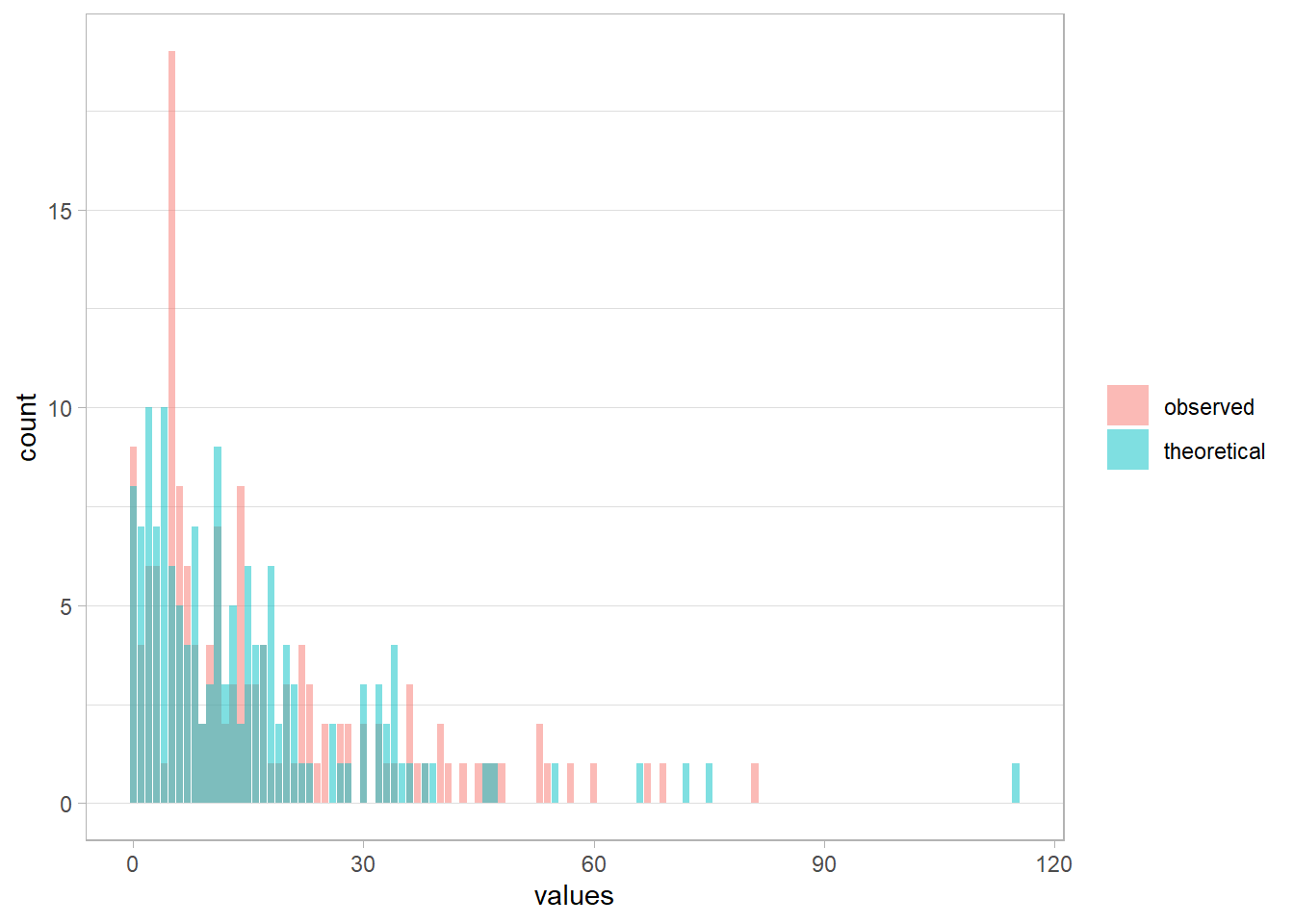
Les deux distributions sont bien plus proches maintenant. Vérifions la surdispersion.
# Overdispersion test
dispersion ratio = 0.978
p-value = 0.992No overdispersion detected.Voilà !
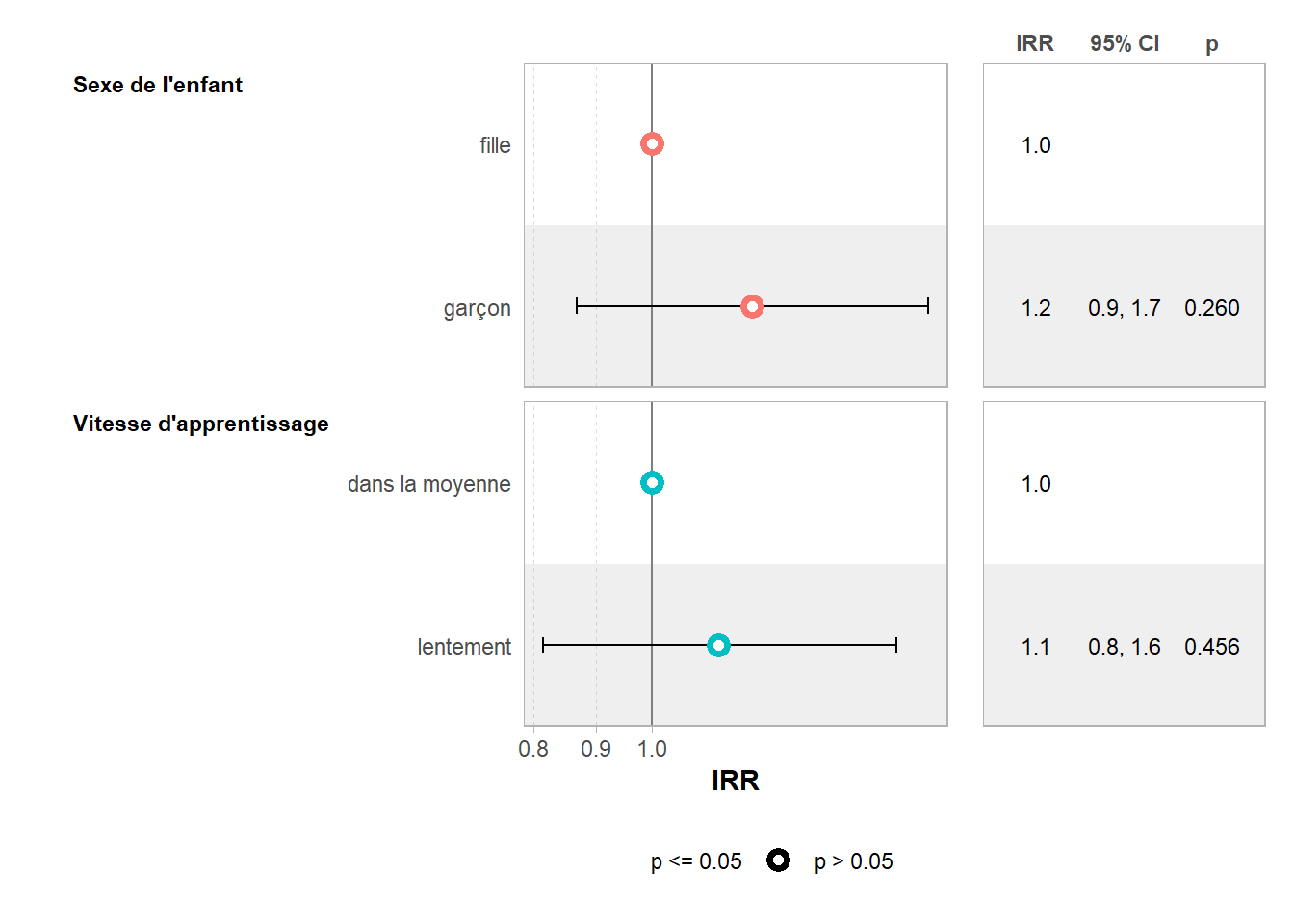
Pour finir, visualisons les coefficients du modèle.
48.5 Modèles de comptage avec une variable binaire
Pour l’analyse d’une variable binaire, les modèles de comptage représentent une alternative à la régression logistique binaire (cf. Chapitre 23). L’intérêt est de pouvoir interpréter les coefficients comme des prevalence ratio plutôt que des odds ratio.
Reprenons un exemple, que nous avons déjà utilisé à plusieurs reprises, concernant la probabilité de faire du sport, à partir de l’enquête histoires de vie 2003. Commençons par charger et recoder les données.
data(hdv2003, package = "questionr")
d <-
hdv2003 |>
mutate(
groupe_ages = age |>
cut(
c(18, 25, 45, 65, 99),
right = FALSE,
include.lowest = TRUE,
labels = c("18-24 ans", "25-44 ans",
"45-64 ans", "65 ans et plus")
)
) |>
set_variable_labels(
sport = "Pratique un sport ?",
sexe = "Sexe",
groupe_ages = "Groupe d'âges",
heures.tv = "Heures de télévision / jour"
)Pour la variable sexe, nous allons définir la modalité Femme
comme modalité de référence. Pour cela, nous allons utiliser un contraste personnalisé (cf. Chapitre 26).
Calculons le modèle de régression logistique binaire classique.
Nous allons maintenant calculer un modèle de Poisson. Nous devons déjà ré-exprimer notre variable à expliquer sous la forme d’une variable numérique égale à 0 si l’on ne pratique pas de sport et à 1 si l’on pratique un sport.
[1] "Non" "Oui"Vérifions si nous avons un problème de surdispersion.
# Overdispersion test
dispersion ratio = 0.635
Pearson's Chi-Squared = 1263.552
p-value = 1No overdispersion detected.Regardons maintenant les résultats de nos deux modèles.
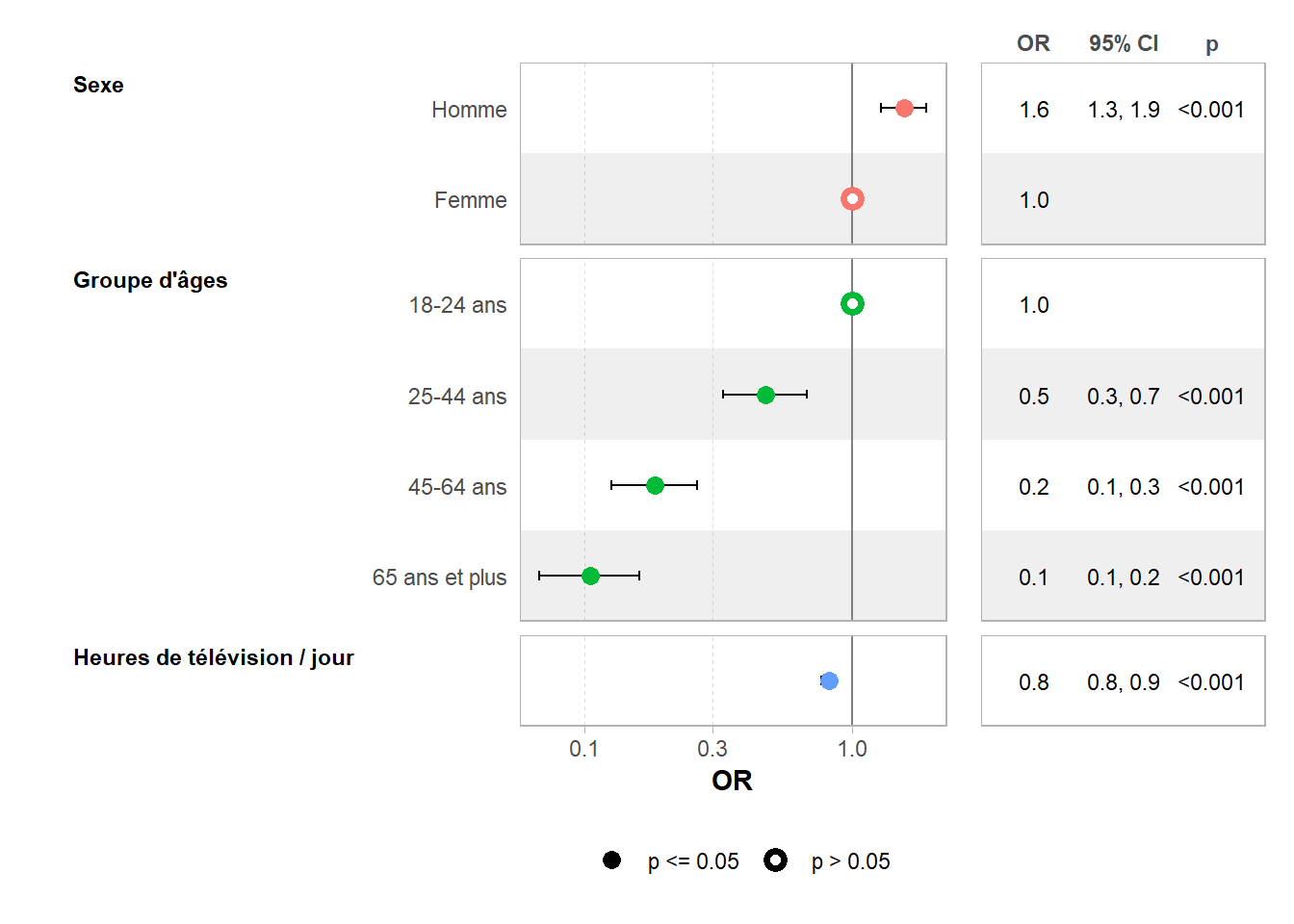
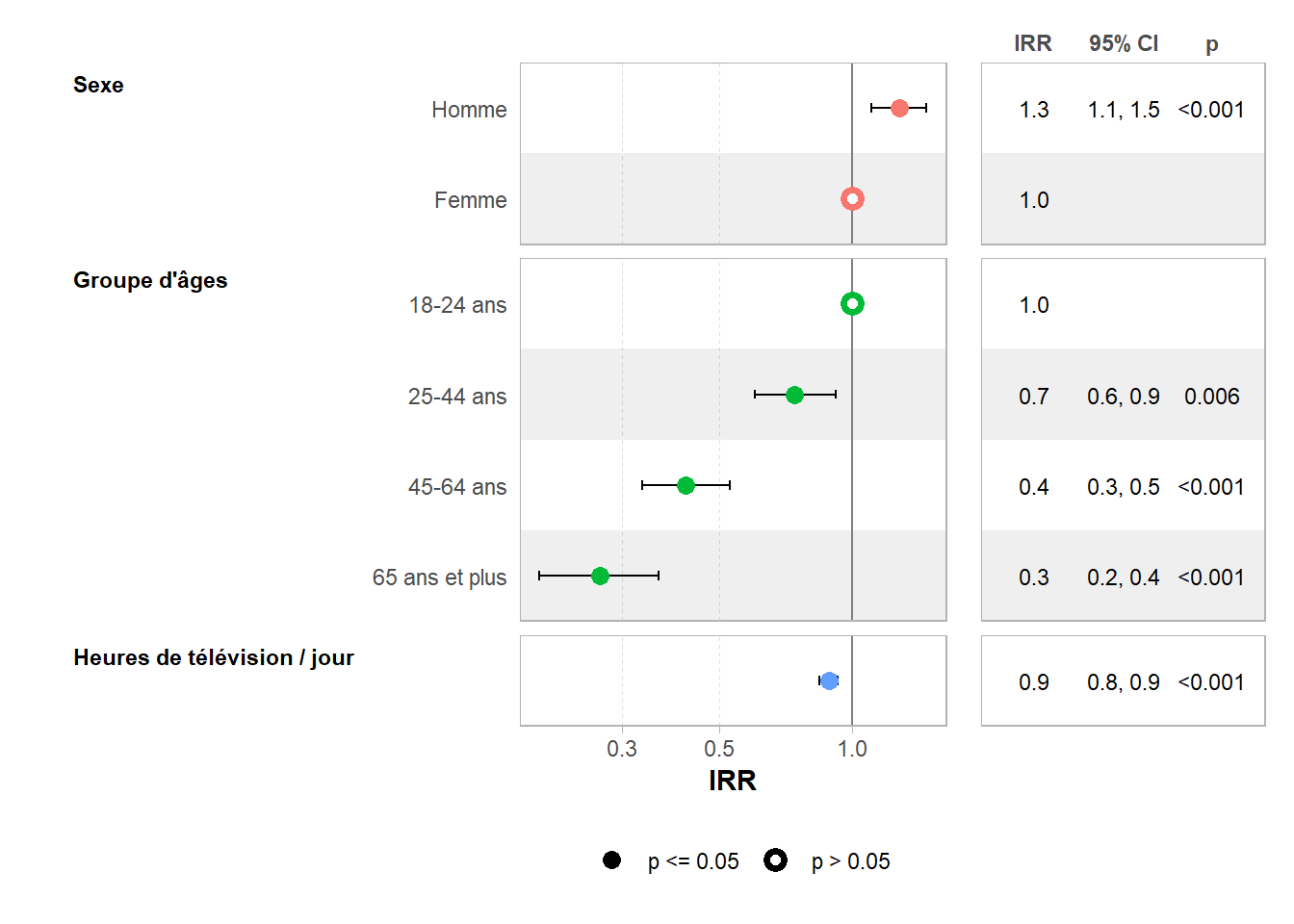
Nous pouvons voir ici que les deux modèles fournissent des résultats assez proches. Par contre, les coefficients ne s’interprètent pas de la même manière. Dans le cadre de la régression logistique, il s’agit d’odds ratios (ou rapports des côtes) définis comme \(OR_{A/B}=(\frac{p_A}{1-p_A})/(\frac{p_B}{1-p_B})\) où \(p_A\) correspond à la probabilité de faire du sport pour la modalité \(A\). Pour la régression de Poisson, il s’agit de prevalence ratios (rapports des prévalences) définis comme \(PR_{A/B}=p_A/p_B\). Avec un rapport des prévalences de 1,3, nous pouvons donc dire que, selon le modèle, les hommes ont 30% de chance en plus de pratiquer un sport.
Pour mieux comparer les deux modèles, nous pouvons présenter les résultats sous la forme de contrastes marginaux moyens (cf. Section 25.4) qui, pour rappel, sont exprimés dans l’échelle de la variable d’intérêt, soit ici sous la forme d’une différence de probabilité.
Scale for x is already present.
Adding another scale for x, which will replace the existing scale.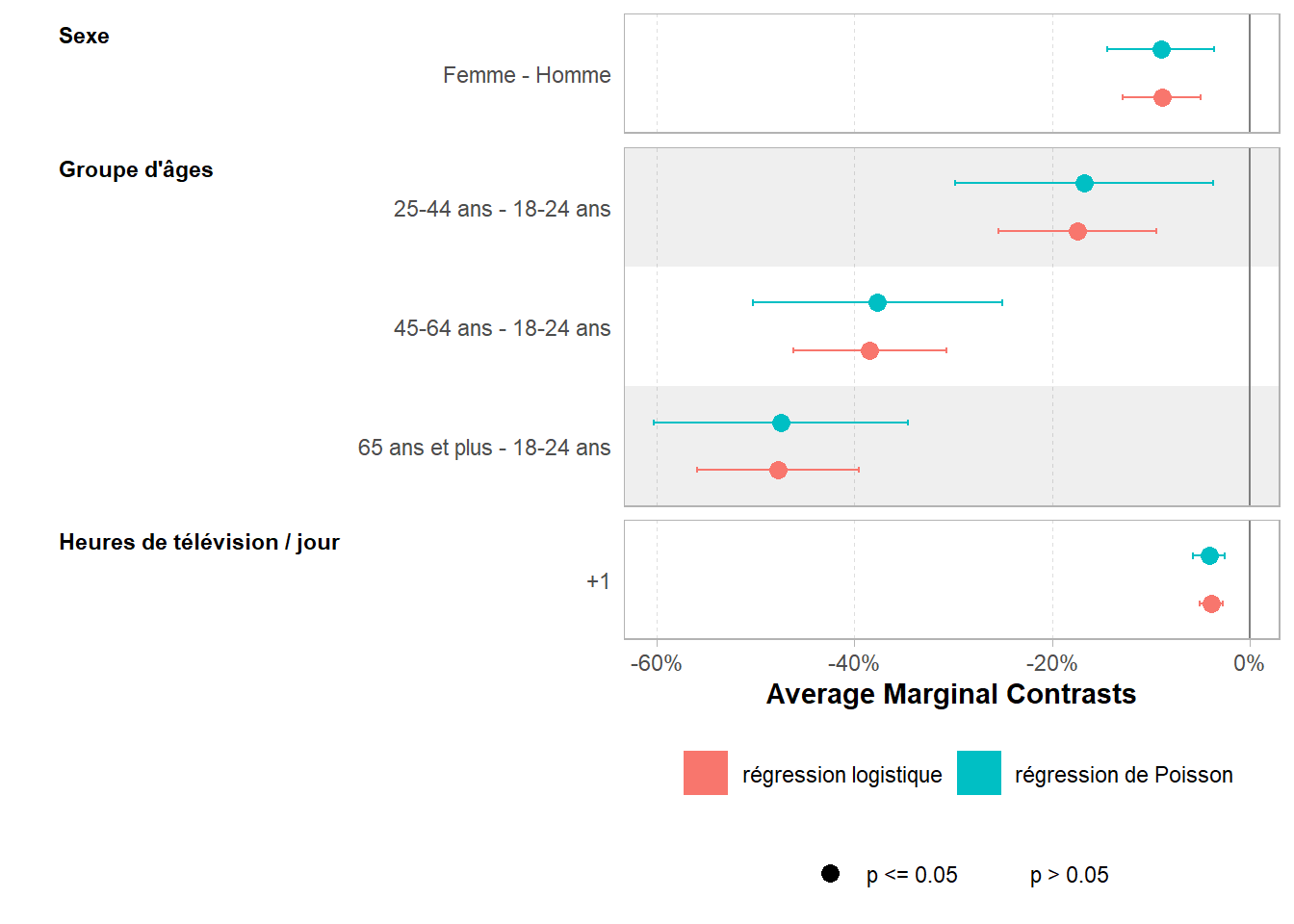
Les résultats sont ici très proches. Nous pouvons néanmoins constater que les intervalles de confiance pour la régression de Poisson sont un peu plus large. Nous pouvons comparer les deux modèles avec performance::compare_performance() pour constater que, dans notre exemple, la régression de Poisson est un peu moins bien ajustée aux données que la régression logistique binaire. Cependant, en pratique, cela n’est pas ici problématique : le choix entre les deux modèles peut donc se faire en fonction de la manière dont on souhaite présenter et narrer les résultats.
Warning: contrasts dropped from factor sexe
Warning: contrasts dropped from factor sexe
Warning: contrasts dropped from factor sexe
Warning: contrasts dropped from factor sexe# Comparison of Model Performance Indices
Name | Model | AIC (weights) | BIC (weights) | RMSE | Tjur's R2 | Nagelkerke's R2
---------------------------------------------------------------------------------------------
mod3_binomial | glm | 2346.3 (>.999) | 2379.8 (>.999) | 0.447 | 0.132 |
mod3_poisson | glm | 2748.8 (<.001) | 2782.4 (<.001) | 0.447 | | 0.158Lorsque l’on a une variable binaire à expliquer et que l’on souhaite calculer des risques relatifs (RR) ou prevalence ratio (PR), une alternative au modèle de Poisson est le modèle log-binomial. Il s’agit d’un modèle binomial avec une fonction de lien logarithme.
Il faut noter que ce type de modèles a parfois du mal à converger.
Error:
! impossible de trouver un jeu de coefficients correct : prière de fournir des valeurs initialesC’est le cas ici ! Nous allons donc initier le modèle avec les coefficients du modèle de Poisson.
Regardons les résultats.
Warning: le pas a été tronqué à cause de la divergence
Warning: le pas a été tronqué à cause de la divergenceWarning: glm.fit : l'algorithme n'a pas convergé
Warning: glm.fit : l'algorithme n'a pas convergéWarning: le pas a été tronqué à cause de la divergenceWarning: glm.fit : l'algorithme n'a pas convergé
Nous obtenons des résultats assez proches de ceux du modèle de Poisson. Notons cependant les différents avis affichés qui nous indiquent que le modèle a eu des difficultés à converger6.
Le package {logbin} propose, via logbin::logbin(), une implémentation de la régression log-binomiale en proposant des algorithmes de convergence plus stables.
Les résultats sont très proches.
Warning: The `tidy()` method for objects of class `logbin` is not maintained by the broom team, and is only supported through the `glm` tidier method. Please be cautious in interpreting and reporting broom output.
This warning is displayed once per session.
6 Sur ce sujet, on pourra consulter l’article Log-binomial models: exploring failed convergence par Tyler Williamson, Misha Eliasziw et Gordon Hilton Fick, DOI: 10.1186/1742-7622-10-14. On pourra également consulter cet échange sur StackExchange.
48.6 Données pondérées et plan d’échantillonnage
Lorsque l’on a des données pondérées avec prise en compte d’un plan d’échantillonnage (cf. Chapitre 29), on ne peut utiliser directement stats::glm() avec un objet {survey}. On aura alors recours à survey::svyglm() qui est très similaire.
Il est tout à fait possible d’appliquer stats::step() à ces modèles7.
7 Y compris, dans le cas présent, au modèle de quasi-Poisson.
Concernant la régression binomiale négative, il n’y a pas d’implémentation fournie directement par {survey}. Cependant, le package {sjstats} en propose une via la fonction sjstats::svyglm.nb().
Warning in theta.ml(Y, mu, sum(w), w, limit = control$maxit, trace =
control$trace > : nombre limite d'iterations atteint
Warning in theta.ml(Y, mu, sum(w), w, limit = control$maxit, trace =
control$trace > : nombre limite d'iterations atteintUne alternative possible consiste à utiliser des poids de réplication selon une approche du type bootsrap. Il faudra déjà définir des poids de réplication avec srvyr::as_survey_rep() puis avoir recours à survey::withReplicates(). Pour faciliter cette deuxième étape, on pourra se faciliter la vie avec le package {svrepmisc} et sa fonction svrepmisc::svynb(). Ce package n’étant pas disponible sur CRAN, on devra l’installer avec la commande pak::pkg_install("carlganz/svrepmisc").
Attention : le temps de calcul du modèle avec les poids de réplication est de plusieurs minutes.
48.7 Tuto@Mate
Les modèles de comptage sont présentés sur YouTube dans le Tuto@Mate#62.
48.8 Lectures complémentaires
Tutoriel : GLM sur données de comptage (régression de Poisson) avec R par Claire Della Vedova
Tutorial: Poisson Regression in R (en anglais) par Hafsa Jabeen
Quasi-Poisson vs. negative binomial regression: how should we model overdispersed count data? par Jay M Ver Hoef et Peter L Boveng, Ecology. 2007 Nov; 88(11):2766-72. doi: 10.1890/07-0043.1. PMID: 18051645