46 Régression logistique multinomiale
La régression logistique multinomiale est une extension de la régression logistique binaire (cf. Chapitre 23) aux variables qualitatives à trois modalités ou plus. Dans ce cas de figure, chaque modalité de la variable d’intérêt sera comparée à une modalité de référence. Les odds ratio seront donc exprimés par rapport à cette dernière.
46.1 Données d’illustration
Pour illustrer la régression logistique multinomiale, nous allons reprendre le jeu de données hdv2003 du package questionr et portant sur l’enquête histoires de vie 2003 de l’Insee.
Nous allons considérer comme variable d’intérêt la variable trav.satisf, à savoir la satisfaction ou l’insatisfaction au travail.
# A tibble: 4 × 4
trav.satisf n N prop
<fct> <int> <int> <dbl>
1 Satisfaction 480 2000 24
2 Insatisfaction 117 2000 5.85
3 Equilibre 451 2000 22.6
4 <NA> 952 2000 47.6 Nous allons choisir comme modalité de référence la position intermédiaire, à savoir l’« équilibre », que nous allons donc définir comme la première modalité du facteur.
Nous allons aussi en profiter pour raccourcir les étiquettes de la variable trav.imp :
Enfin, procédons à quelques recodages additionnels :
d <- d |>
mutate(
sexe = sexe |> fct_relevel("Femme"),
groupe_ages = age |>
cut(
c(18, 25, 45, 99),
right = FALSE,
include.lowest = TRUE,
labels = c("18-24 ans", "25-44 ans",
"45 et plus")
),
etudes = nivetud |>
fct_recode(
"Primaire" = "N'a jamais fait d'etudes",
"Primaire" = "A arrete ses etudes, avant la derniere annee d'etudes primaires",
"Primaire" = "Derniere annee d'etudes primaires",
"Secondaire" = "1er cycle",
"Secondaire" = "2eme cycle",
"Technique / Professionnel" = "Enseignement technique ou professionnel court",
"Technique / Professionnel" = "Enseignement technique ou professionnel long",
"Supérieur" = "Enseignement superieur y compris technique superieur"
) |>
fct_na_value_to_level("Non documenté")
) |>
set_variable_labels(
trav.satisf = "Satisfaction dans le travail",
sexe = "Sexe",
groupe_ages = "Groupe d'âges",
etudes = "Niveau d'études",
trav.imp = "Importance accordée au travail"
)46.2 Calcul du modèle multinomial
Pour calculer un modèle logistique multinomial, nous allons utiliser la fonction nnet::multinom() de l’extension nnet1. La syntaxe de nnet::multinom() est similaire à celle de glm(), le paramètre family en moins.
1 Il existe plusieurs alternatives possibles : la fonction VGAM::vglm() avec family = VGAM::multinomial ou encore mlogit::mlogit(). Ces deux fonctions sont un peu plus complexes à mettre en œuvre. On se référera à la documentation de chaque package. Le support des modèles mlogit() et vglm() est aussi plus limité dans d’autres packages tels que broom.helpers, gtsummary, ggstats ou encore marginaleffects.
# weights: 36 (22 variable)
initial value 1151.345679
iter 10 value 977.985279
iter 20 value 971.187398
final value 971.113280
convergedComme pour la régression logistique binaire, il est possible de réaliser une sélection pas à pas descendante (cf. Chapitre 24) :
trying - sexe
trying - etudes
trying - groupe_ages
trying - trav.imp
trying - sexe
trying - etudes
trying - trav.imp
trying - etudes
trying - trav.imp 46.3 Affichage des résultats du modèle
Une des particularités de la régression logistique multinomiale est qu’elle produit une série de coefficients pour chaque modalité de la variable d’intérêt (sauf la modalité de référence). Ici, nous aurons donc une série de coefficients pour celles et ceux qui sont satisfaits au travail (comparés à la modalité Équilibre
) et une série de coefficients pour celles et ceux qui sont insatisfaits (comparés aux aussi à la modalité Équilibre
).
La fonction gtsummary::tbl_regression() peut gérer ce type de modèles, et va afficher les deux séries de coefficients l’une au-dessus de l’autre. Nous allons indiquer exponentiate = TRUE car, comme pour la régression logistique binaire, l’exponentielle des coefficients peut s’interpréter comme des odds ratios.
Dans le cas présent, le tableau retourné est un tableau groupé
, c’est-à-dire que sa structure est légèrement différente, avec les coefficients groupés par niveau de la variable à expliquer. De fait, les fonctions comme gtsummary::bold_labels() ne fonctionneront pas forcément et il n’y pas de fonction native pour la mise en forme des étiquettes des groupes. On pourra alors avoir recours à la fonction guideR::style_grouped_tbl() de guideR, le package compagnon de guide-R. Attention : le tableau sera converti au format gt afin de mettre en forme les étiquettes des groupes. On appellera donc guideR::style_grouped_tbl() en tout dernier. En cas de conversion dans un autre format (data frame, flextable, …), on évitera donc cette fonction.
ℹ Multinomial models, multi-component models and other groups models have a
different underlying structure than the models gtsummary was designed for.
• Functions designed to work with `tbl_regression()` objects may yield
unexpected results.
ℹ Suppress this message with `?suppressMessages()`.| Caractéristique | OR | 95% IC | p-valeur |
|---|---|---|---|
| Satisfaction | |||
| Niveau d'études | |||
| Primaire | — | — | |
| Secondaire | 1,05 | 0,63 – 1,76 | 0,9 |
| Technique / Professionnel | 1,08 | 0,67 – 1,73 | 0,7 |
| Supérieur | 2,01 | 1,24 – 3,27 | 0,005 |
| Non documenté | 0,58 | 0,18 – 1,86 | 0,4 |
| Importance accordée au travail | |||
| Le plus | — | — | |
| Aussi | 1,29 | 0,56 – 2,98 | 0,5 |
| Moins | 0,84 | 0,37 – 1,88 | 0,7 |
| Peu | 0,55 | 0,18 – 1,64 | 0,3 |
| Insatisfaction | |||
| Niveau d'études | |||
| Primaire | — | — | |
| Secondaire | 0,91 | 0,41 – 1,99 | 0,8 |
| Technique / Professionnel | 1,09 | 0,54 – 2,19 | 0,8 |
| Supérieur | 1,08 | 0,51 – 2,29 | 0,8 |
| Non documenté | 0,96 | 0,18 – 4,97 | >0,9 |
| Importance accordée au travail | |||
| Le plus | — | — | |
| Aussi | 0,80 | 0,24 – 2,69 | 0,7 |
| Moins | 0,59 | 0,18 – 1,88 | 0,4 |
| Peu | 3,82 | 1,05 – 13,9 | 0,042 |
| Abréviations: IC = intervalle de confiance, OR = rapport de cotes | |||
L’odds ratio du niveau d’étude supérieur pour la modalité satisfaction est de 2,01, indiquant que les personnes ayant un niveau d’étude supérieur ont plus de chances d’être satisfait au travail que d’être à l’équilibre que les personnes de niveau primaire. Par contre, l’OR est de seulement 1,08 (et non significatif) pour la modalité Insatisfait indiquant que ces personnes n’ont ni plus ni moins de chance d’être insatisfaite que d’être à l’équilibre.
On notera au passage un message d’avertissement de gtsummary sur le fait que les modèles multinomiaux n’ont pas la même structure que d’autres modèles.
La fonction gtsummary::tbl_regression() affiche le tableau des coefficients dans un format long. Or, il est souvent plus lisible de présenter les coefficients dans un format large, avec les coefficients pour chaque modalité côte à côte.
Cela n’est pas possible nativement avec gtsummary mais on pourra éventuellement utiliser la fonction guideR::grouped_tbl_pivot_wider()2 fournie par guideR, le package compagnon de guide-R.
| Caractéristique |
Satisfaction
|
Insatisfaction
|
||||
|---|---|---|---|---|---|---|
| OR | 95% IC | p-valeur | OR | 95% IC | p-valeur | |
| Niveau d'études | ||||||
| Primaire | — | — | — | — | ||
| Secondaire | 1,05 | 0,63 – 1,76 | 0,9 | 0,91 | 0,41 – 1,99 | 0,8 |
| Technique / Professionnel | 1,08 | 0,67 – 1,73 | 0,7 | 1,09 | 0,54 – 2,19 | 0,8 |
| Supérieur | 2,01 | 1,24 – 3,27 | 0,005 | 1,08 | 0,51 – 2,29 | 0,8 |
| Non documenté | 0,58 | 0,18 – 1,86 | 0,4 | 0,96 | 0,18 – 4,97 | >0,9 |
| Importance accordée au travail | ||||||
| Le plus | — | — | — | — | ||
| Aussi | 1,29 | 0,56 – 2,98 | 0,5 | 0,80 | 0,24 – 2,69 | 0,7 |
| Moins | 0,84 | 0,37 – 1,88 | 0,7 | 0,59 | 0,18 – 1,88 | 0,4 |
| Peu | 0,55 | 0,18 – 1,64 | 0,3 | 3,82 | 1,05 – 13,9 | 0,042 |
| Abréviations: IC = intervalle de confiance, OR = rapport de cotes | ||||||
2 Il s’agit d’une adaptation de la fonction multinom_pivot_wider() proposée sur GitHub Gist.
Pour tester l’effet globale d’une variable dans le modèle, on aura directement recours à car::Anova().
Analysis of Deviance Table (Type II tests)
Response: trav.satisf
LR Chisq Df Pr(>Chisq)
etudes 24.211 8 0.002112 **
trav.imp 48.934 6 7.687e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Si l’on applique gtsummary::add_global_p() au résultat de gtsummary::tbl_regression(), les p-valeurs seront recopiées pour chaque série de coefficients.
| Caractéristique | OR | 95% IC | p-valeur |
|---|---|---|---|
| Satisfaction | |||
| Niveau d'études | 0,002 | ||
| Primaire | — | — | |
| Secondaire | 1,05 | 0,63 – 1,76 | |
| Technique / Professionnel | 1,08 | 0,67 – 1,73 | |
| Supérieur | 2,01 | 1,24 – 3,27 | |
| Non documenté | 0,58 | 0,18 – 1,86 | |
| Importance accordée au travail | <0,001 | ||
| Le plus | — | — | |
| Aussi | 1,29 | 0,56 – 2,98 | |
| Moins | 0,84 | 0,37 – 1,88 | |
| Peu | 0,55 | 0,18 – 1,64 | |
| Insatisfaction | |||
| Niveau d'études | 0,002 | ||
| Primaire | — | — | |
| Secondaire | 0,91 | 0,41 – 1,99 | |
| Technique / Professionnel | 1,09 | 0,54 – 2,19 | |
| Supérieur | 1,08 | 0,51 – 2,29 | |
| Non documenté | 0,96 | 0,18 – 4,97 | |
| Importance accordée au travail | <0,001 | ||
| Le plus | — | — | |
| Aussi | 0,80 | 0,24 – 2,69 | |
| Moins | 0,59 | 0,18 – 1,88 | |
| Peu | 3,82 | 1,05 – 13,9 | |
| Abréviations: IC = intervalle de confiance, OR = rapport de cotes | |||
Une astuce consiste à cacher toutes ces colonnes de p-valeurs, n’afficher que la dernière et changer son titre de colonne. Pour cela, on pourra profiter de la fonction guideR::multinom_add_global_p_pivot_wider().
| Caractéristique |
Satisfaction
|
Insatisfaction
|
Likelihood-ratio test
|
||
|---|---|---|---|---|---|
| OR | 95% IC | OR | 95% IC | p-valeur | |
| Niveau d'études | 0,002 | ||||
| Primaire | — | — | — | — | |
| Secondaire | 1,05 | 0,63 – 1,76 | 0,91 | 0,41 – 1,99 | |
| Technique / Professionnel | 1,08 | 0,67 – 1,73 | 1,09 | 0,54 – 2,19 | |
| Supérieur | 2,01 | 1,24 – 3,27 | 1,08 | 0,51 – 2,29 | |
| Non documenté | 0,58 | 0,18 – 1,86 | 0,96 | 0,18 – 4,97 | |
| Importance accordée au travail | <0,001 | ||||
| Le plus | — | — | — | — | |
| Aussi | 1,29 | 0,56 – 2,98 | 0,80 | 0,24 – 2,69 | |
| Moins | 0,84 | 0,37 – 1,88 | 0,59 | 0,18 – 1,88 | |
| Peu | 0,55 | 0,18 – 1,64 | 3,82 | 1,05 – 13,9 | |
| Abréviations: IC = intervalle de confiance, OR = rapport de cotes | |||||
Pour un graphique des coefficients, on peut appeler directement ggstats::gcoef_model() ou encore ggstats::coef_table()3. De plus, ggstats propose également les variantes ggstats::gcoef_dodged() et ggstats::ggcoef_faceted().
3 Attention : pour que cela fonctionne avec un modèle multinomial, il est nécessaire d’utiliser la version 0.9.0 (ou une version plus récente) de ggstats.
`height` was translated to `width`.
`height` was translated to `width`.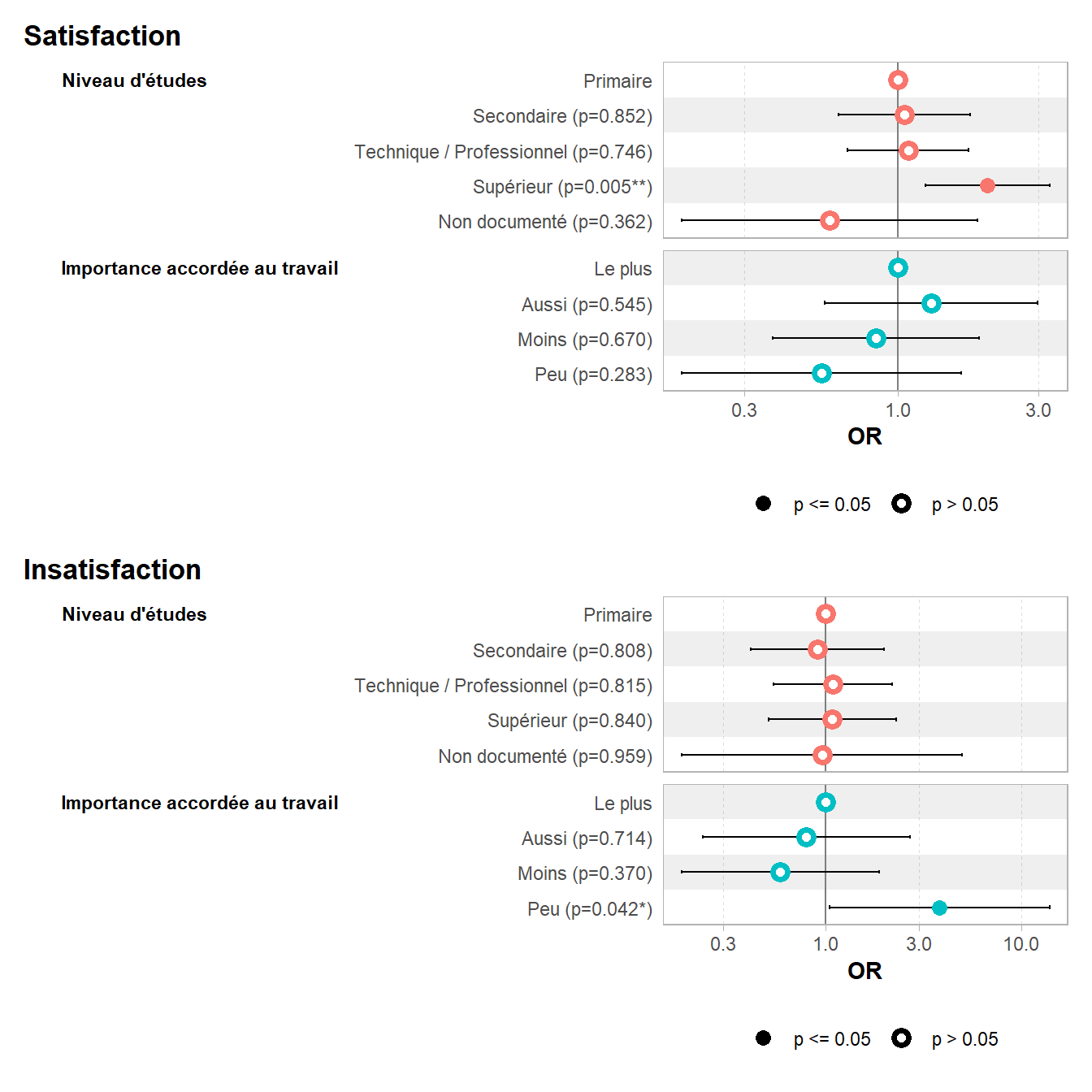
`height` was translated to `width`.
`height` was translated to `width`.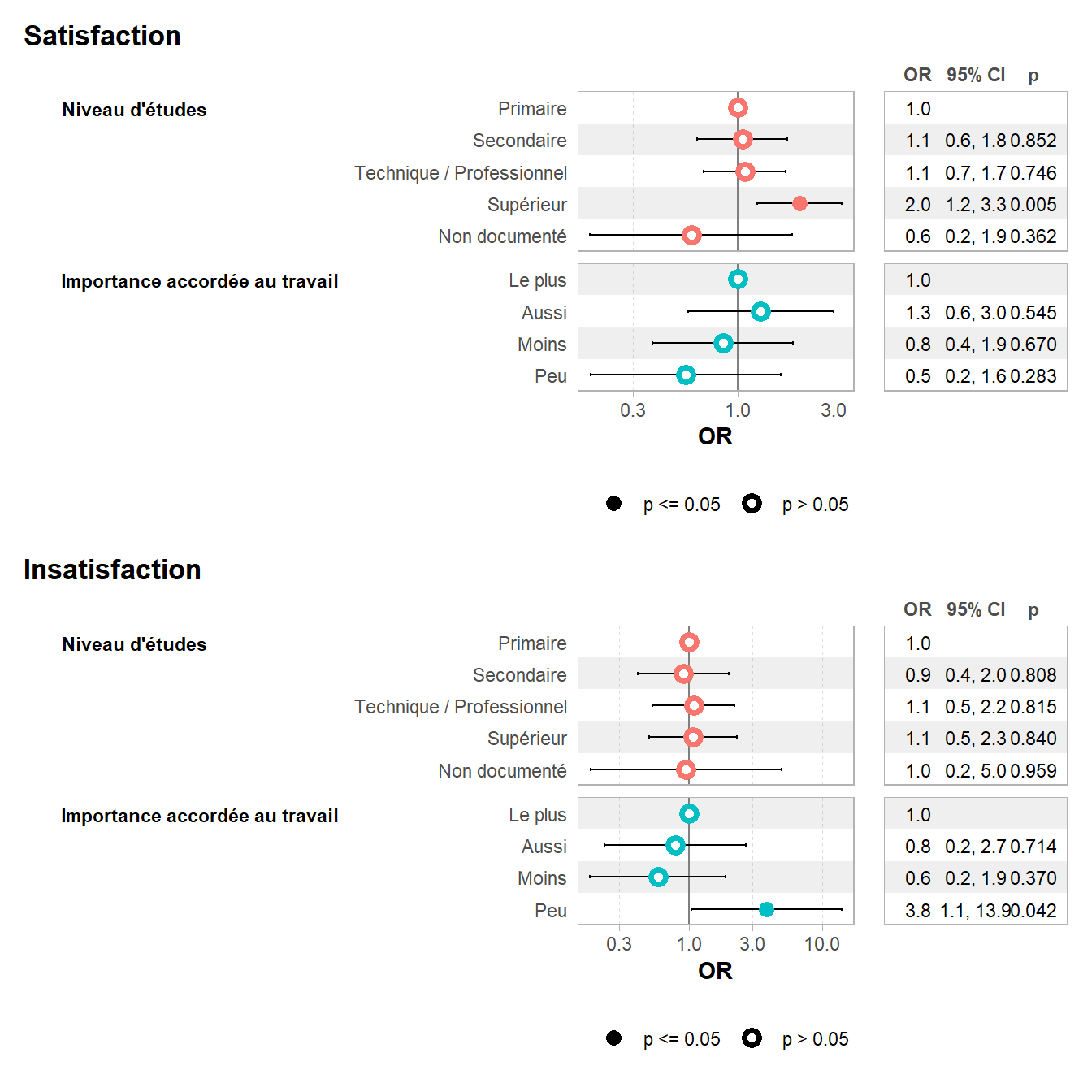
`height` was translated to `width`.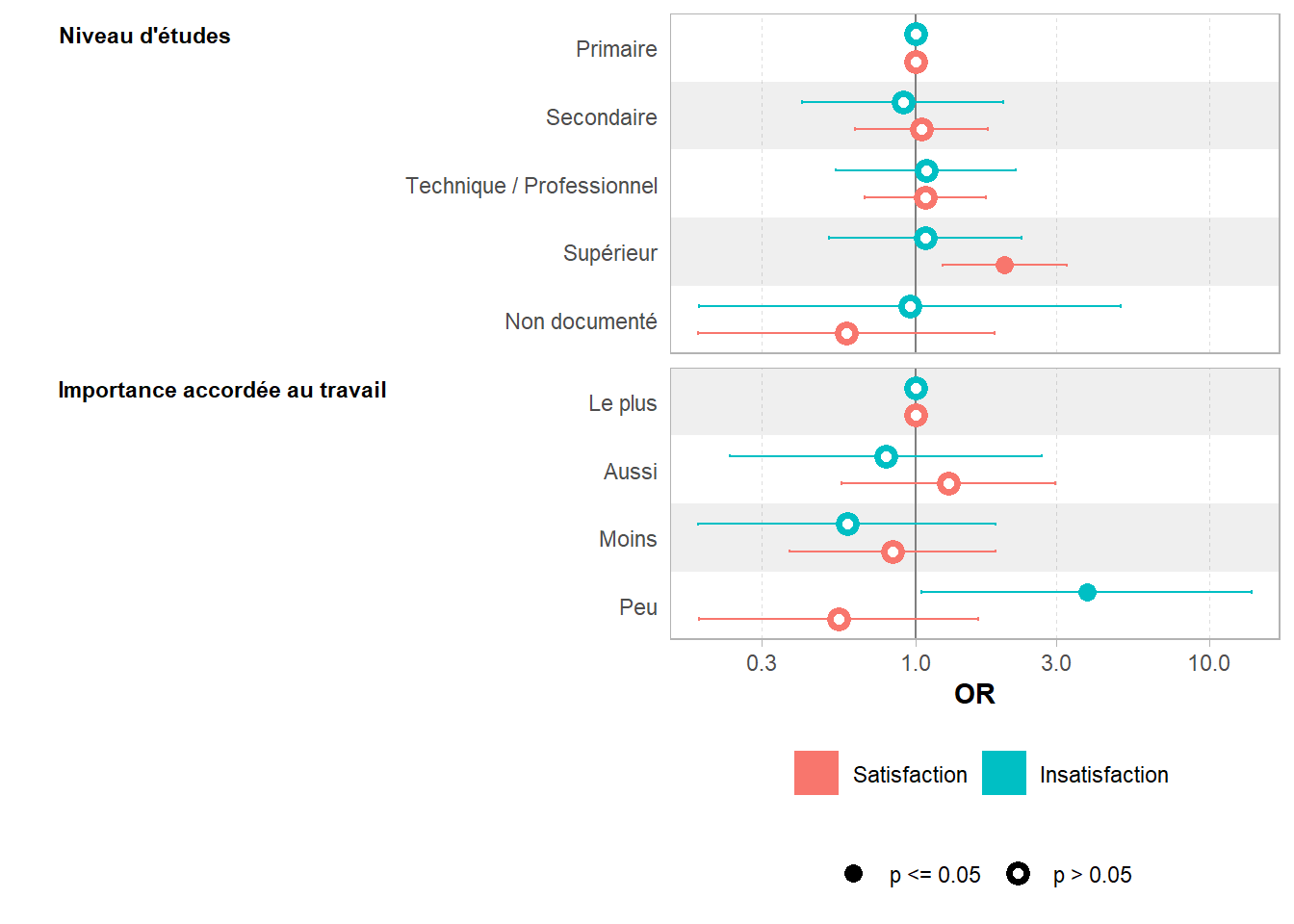
`height` was translated to `width`.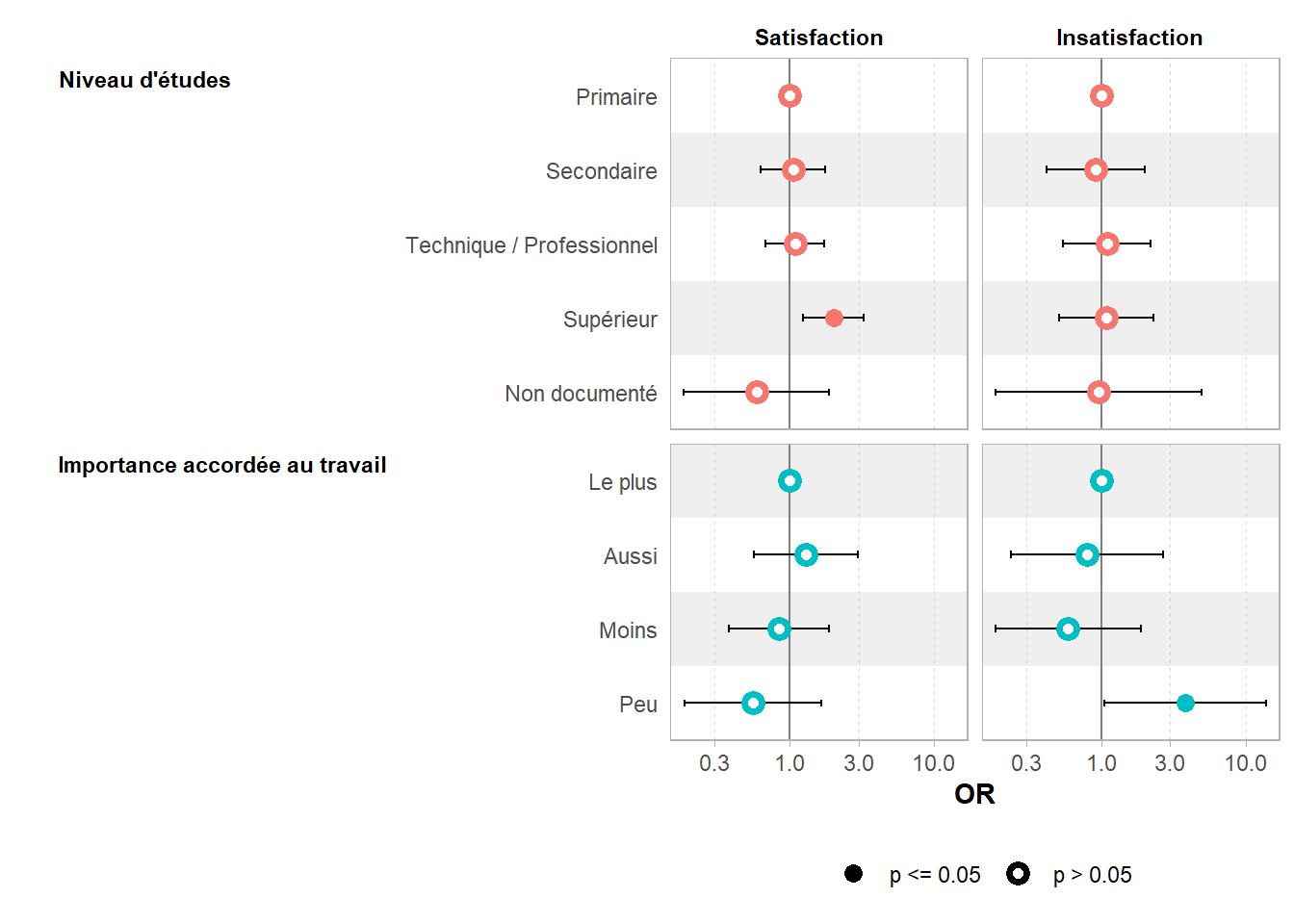
Pour faciliter l’interprétation, on pourra représenter les prédictions marginales du modèle (cf. Chapitre 25) avec broom.helpers::plot_marginal_predictions().
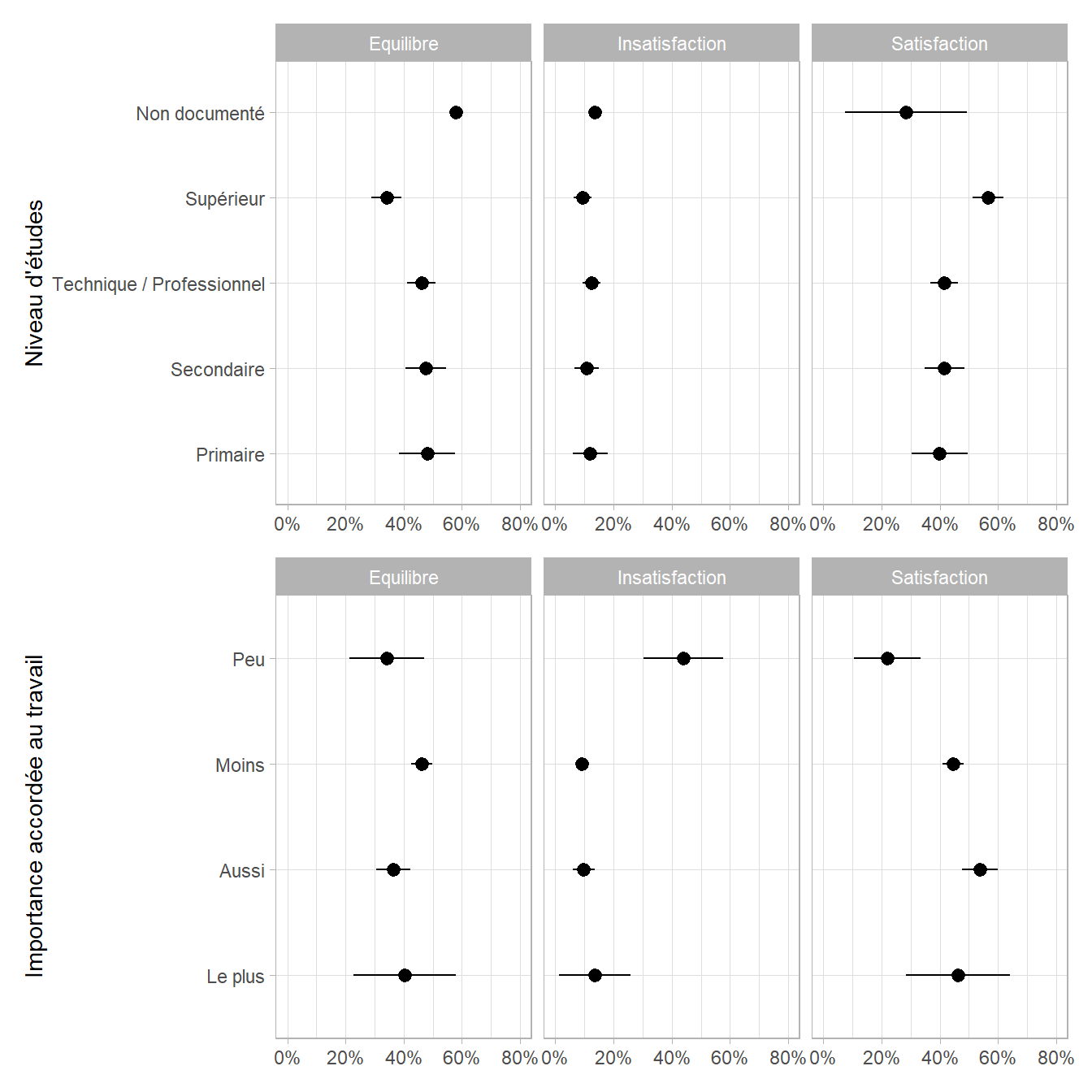
Dans certaines situations, il peut être plus simple de réaliser plusieurs modèles logistiques binaires séparés plutôt qu’une régression multinomiale. Si la variable à expliquer a trois niveaux (A, B et C), on pourra réaliser un modèle binaire B vs A, et un modèle binaire C vs A. Cette approche est appelée approximation de Begg et Gray
. On trouvera, en anglais, plus d’explications et des références bibliographiques sur StackOverflow.
46.4 Données pondérées
L’extension survey (cf. Chapitre 29) ne fournit pas de fonction adaptée aux régressions multinomiales. Cependant, il est possible d’en réaliser une en ayant recours à des poids de réplication, comme suggéré par Thomas Lumley dans son ouvrage Complex Surveys: A Guide to Analysis Using R. Thomas Lumley est par ailleurs l’auteur de l’extension survey.
46.4.1 avec svrepmisc::svymultinom()
L’extension svrepmisc disponible sur GitHub fournit quelques fonctions facilitant l’utilisation des poids de réplication avec survey. Pour l’installer, on utilisera le code ci-dessous :
En premier lieu, il faut définir le design de notre tableau de données puis calculer des poids de réplication.
Il faut prévoir un nombre de replicates suffisant pour calculer ultérieurement les intervalles de confiance des coefficients. Plus ce nombre est élevé, plus précise sera l’estimation de la variance et donc des valeurs p et des intervalles de confiance. Cependant, plus ce nombre est élevé, plus le temps de calcul sera important. Pour gagner en temps de calcul, nous avons ici pris une valeur de 25, mais l’usage est de considérer au moins 1000 réplications.
svrepmisc fournit une fonction svrepmisc::svymultinom() pour le calcul d’une régression multinomiale avec des poids de réplication.
svrepmisc fournit également des méthodes svrepmisc::confint() et svrepmisc::tidy(). Nous pouvons donc calculer et afficher les odds ratio et leur intervalle de confiance.
Coefficient SE t value
Satisfaction.(Intercept) -0.116149 0.682140 -0.1703
Insatisfaction.(Intercept) -1.547056 0.968423 -1.5975
Satisfaction.sexeHomme -0.041405 0.203336 -0.2036
Insatisfaction.sexeHomme 0.221849 0.281590 0.7878
Satisfaction.etudesSecondaire 0.115722 0.385037 0.3005
Insatisfaction.etudesSecondaire 0.418476 0.591875 0.7070
Satisfaction.etudesTechnique / Professionnel 0.220702 0.411932 0.5358
Insatisfaction.etudesTechnique / Professionnel 0.529317 0.543952 0.9731
Satisfaction.etudesSupérieur 0.905852 0.370173 2.4471
Insatisfaction.etudesSupérieur 0.584499 0.590935 0.9891
Satisfaction.etudesNon documenté -0.323293 1.013718 -0.3189
Insatisfaction.etudesNon documenté 0.646168 6.312242 0.1024
Satisfaction.trav.impAussi -0.027506 0.632522 -0.0435
Insatisfaction.trav.impAussi -0.375642 0.956326 -0.3928
Satisfaction.trav.impMoins -0.220703 0.633586 -0.3483
Insatisfaction.trav.impMoins -0.694337 0.916940 -0.7572
Satisfaction.trav.impPeu -0.069034 0.630887 -0.1094
Insatisfaction.trav.impPeu 1.584747 0.911861 1.7379
Pr(>|t|)
Satisfaction.(Intercept) 0.86961
Insatisfaction.(Intercept) 0.15419
Satisfaction.sexeHomme 0.84444
Insatisfaction.sexeHomme 0.45663
Satisfaction.etudesSecondaire 0.77249
Insatisfaction.etudesSecondaire 0.50240
Satisfaction.etudesTechnique / Professionnel 0.60871
Insatisfaction.etudesTechnique / Professionnel 0.36292
Satisfaction.etudesSupérieur 0.04429 *
Insatisfaction.etudesSupérieur 0.35556
Satisfaction.etudesNon documenté 0.75909
Insatisfaction.etudesNon documenté 0.92134
Satisfaction.trav.impAussi 0.96653
Insatisfaction.trav.impAussi 0.70616
Satisfaction.trav.impMoins 0.73783
Insatisfaction.trav.impMoins 0.47362
Satisfaction.trav.impPeu 0.91594
Insatisfaction.trav.impPeu 0.12579
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 2.5 % 97.5 %
Satisfaction.(Intercept) -1.72915416 1.4968557
Insatisfaction.(Intercept) -3.83701296 0.7429002
Satisfaction.sexeHomme -0.52221762 0.4394068
Insatisfaction.sexeHomme -0.44400668 0.8877045
Satisfaction.etudesSecondaire -0.79474538 1.0261902
Insatisfaction.etudesSecondaire -0.98108643 1.8180392
Satisfaction.etudesTechnique / Professionnel -0.75336124 1.1947661
Insatisfaction.etudesTechnique / Professionnel -0.75692584 1.8155607
Satisfaction.etudesSupérieur 0.03053207 1.7811720
Insatisfaction.etudesSupérieur -0.81283932 1.9818381
Satisfaction.etudesNon documenté -2.72035652 2.0737697
Insatisfaction.etudesNon documenté -14.27991169 15.5722472
Satisfaction.trav.impAussi -1.52318355 1.4681713
Insatisfaction.trav.impAussi -2.63699457 1.8857109
Satisfaction.trav.impMoins -1.71889608 1.2774892
Insatisfaction.trav.impMoins -2.86255616 1.4738823
Satisfaction.trav.impPeu -1.56084516 1.4227764
Insatisfaction.trav.impPeu -0.57146052 3.7409549 term estimate std.error
1 Insatisfaction.(Intercept) 0.2128737 0.9684230
2 Insatisfaction.etudesNon documenté 1.9082140 6.3122415
3 Insatisfaction.etudesSecondaire 1.5196444 0.5918753
4 Insatisfaction.etudesSupérieur 1.7940926 0.5909348
5 Insatisfaction.etudesTechnique / Professionnel 1.6977731 0.5439525
6 Insatisfaction.sexeHomme 1.2483828 0.2815904
7 Insatisfaction.trav.impAussi 0.6868483 0.9563265
8 Insatisfaction.trav.impMoins 0.4994055 0.9169403
9 Insatisfaction.trav.impPeu 4.8780580 0.9118606
10 Satisfaction.(Intercept) 0.8903423 0.6821401
11 Satisfaction.etudesNon documenté 0.7237615 1.0137184
12 Satisfaction.etudesSecondaire 1.1226842 0.3850370
13 Satisfaction.etudesSupérieur 2.4740390 0.3701730
14 Satisfaction.etudesTechnique / Professionnel 1.2469523 0.4119317
15 Satisfaction.sexeHomme 0.9594401 0.2033356
16 Satisfaction.trav.impAussi 0.9728687 0.6325222
17 Satisfaction.trav.impMoins 0.8019545 0.6335859
18 Satisfaction.trav.impPeu 0.9332946 0.6308870
statistic p.value conf.low conf.high
1 -1.59750065 0.15418582 2.155790e-02 2.102023e+00
2 0.10236740 0.92133583 6.285114e-07 5.793500e+06
3 0.70703463 0.50239618 3.749036e-01 6.159768e+00
4 0.98910980 0.35555874 4.435968e-01 7.256068e+00
5 0.97309496 0.36292396 4.691063e-01 6.144520e+00
6 0.78784250 0.45663323 6.414611e-01 2.429546e+00
7 -0.39279663 0.70615685 7.157606e-02 6.591039e+00
8 -0.75723248 0.47362376 5.712256e-02 4.366153e+00
9 1.73792702 0.12578843 5.647001e-01 4.213821e+01
10 -0.17027184 0.86961314 1.774344e-01 4.467619e+00
11 -0.31891835 0.75909405 6.585127e-02 7.954754e+00
12 0.30054881 0.77248856 4.516962e-01 2.790415e+00
13 2.44710481 0.04429493 1.031003e+00 5.936810e+00
14 0.53577434 0.60870870 4.707815e-01 3.302785e+00
15 -0.20363098 0.84443509 5.932036e-01 1.551786e+00
16 -0.04348642 0.96652826 2.180167e-01 4.341289e+00
17 -0.34834019 0.73782588 1.792639e-01 3.587621e+00
18 -0.10942428 0.91593685 2.099585e-01 4.148623e+00Par contre, le support de gtsummary::tbl_regression() et ggstats::ggcoef_model() est plus limité. Vous pourrez afficher un tableau basique des résultats et un graphiques des coefficients, mais sans les enrichissements usuels (identification des variables, étiquettes propres, identification des niveaux, etc.).
46.4.2 avec svyVGAM::svy_glm()
Une alternative possible pour le calcul de la régression logistique multinomiale avec des données pondérées est svyVGAM::svy_vglm() avec family = VGAM::multinomial.
Nous allons commencer par définir le plan d’échantillonnage.
Puis, on appelle svyVGAM::svy_vglm() en précisant family = VGAM::multinomial. Par défaut, VGAM::multinomial() utilise la dernière modalité de la variable d’intérêt comme modalité de référence. Cela est modifiable avec refLevel.
svy_vglm.survey.design(trav.satisf ~ sexe + etudes + trav.imp,
family = VGAM::multinomial(refLevel = "Equilibre"), design = dw)
Independent Sampling design (with replacement)
Called via srvyr
Sampling variables:
- ids: `1`
- weights: poids
Data variables:
- id (int), age (int), sexe (fct), nivetud (fct), poids (dbl), occup (fct),
qualif (fct), freres.soeurs (int), clso (fct), relig (fct), trav.imp (fct),
trav.satisf (fct), hard.rock (fct), lecture.bd (fct), peche.chasse (fct),
cuisine (fct), bricol (fct), cinema (fct), sport (fct), heures.tv (dbl),
groupe_ages (fct), etudes (fct)
Coef SE z p
(Intercept):1 -0.116117 0.553242 -0.2099 0.833757
(Intercept):2 -1.547693 0.876195 -1.7664 0.077332
sexeHomme:1 -0.041412 0.171351 -0.2417 0.809029
sexeHomme:2 0.221930 0.272669 0.8139 0.415693
etudesSecondaire:1 0.115688 0.341830 0.3384 0.735034
etudesSecondaire:2 0.418102 0.563205 0.7424 0.457868
etudesTechnique / Professionnel:1 0.220662 0.310123 0.7115 0.476754
etudesTechnique / Professionnel:2 0.529020 0.501080 1.0558 0.291079
etudesSupérieur:1 0.905798 0.314513 2.8800 0.003977
etudesSupérieur:2 0.584320 0.525633 1.1116 0.266289
etudesNon documenté:1 -0.323271 0.662511 -0.4879 0.625587
etudesNon documenté:2 0.646195 0.939745 0.6876 0.491687
trav.impAussi:1 -0.027517 0.511636 -0.0538 0.957109
trav.impAussi:2 -0.374881 0.825214 -0.4543 0.649625
trav.impMoins:1 -0.220706 0.494951 -0.4459 0.655659
trav.impMoins:2 -0.693571 0.792031 -0.8757 0.381200
trav.impPeu:1 -0.069004 0.706959 -0.0976 0.922244
trav.impPeu:2 1.585521 0.866529 1.8297 0.067289Là encore, le support de gtsummary::tbl_regression() sera limité4. Pour calculer les odds ratios avec leurs intervalles de confiance, on pourra avoir recours à broom.helpers::tidy_svy_vglm(), dédié justement à ce type de modèles5.
4 Du moins, avec la version stable actuelle de gtsummary (la version 2.2.0). Par contre, le support est intégré à la version de développement et sera donc disponible dans la prochaine version stable.
5 Cette fonction a été introduite dans la version 1.21.0 de broom.helpers. Pensez à éventuellement mettre à jour le package.
original_term term group
1 (Intercept):1 (Intercept) 1
2 (Intercept):2 (Intercept) 2
3 sexeHomme:1 sexeHomme 1
4 sexeHomme:2 sexeHomme 2
5 etudesSecondaire:1 etudesSecondaire 1
6 etudesSecondaire:2 etudesSecondaire 2
7 etudesTechnique / Professionnel:1 etudesTechnique / Professionnel 1
8 etudesTechnique / Professionnel:2 etudesTechnique / Professionnel 2
9 etudesSupérieur:1 etudesSupérieur 1
10 etudesSupérieur:2 etudesSupérieur 2
11 etudesNon documenté:1 etudesNon documenté 1
12 etudesNon documenté:2 etudesNon documenté 2
13 trav.impAussi:1 trav.impAussi 1
14 trav.impAussi:2 trav.impAussi 2
15 trav.impMoins:1 trav.impMoins 1
16 trav.impMoins:2 trav.impMoins 2
17 trav.impPeu:1 trav.impPeu 1
18 trav.impPeu:2 trav.impPeu 2
estimate std.error conf.level conf.low conf.high statistic df.error
1 0.8903708 0.4925908 0.95 0.30105802 2.633247 -0.20988509 Inf
2 0.2127382 0.1864002 0.95 0.03819678 1.184853 -1.76637893 Inf
3 0.9594340 0.1643997 0.95 0.68574259 1.342360 -0.24167835 Inf
4 1.2484837 0.3404228 0.95 0.73162172 2.130488 0.81391637 Inf
5 1.1226456 0.3837540 0.95 0.57448201 2.193860 0.33843739 Inf
6 1.5190753 0.8555505 0.95 0.50370762 4.581209 0.74236198 Inf
7 1.2469025 0.3866926 0.95 0.67897791 2.289862 0.71153296 Inf
8 1.6972676 0.8504673 0.95 0.63566751 4.531799 1.05575832 Inf
9 2.4739057 0.7780767 0.95 1.33557655 4.582448 2.87999791 Inf
10 1.7937708 0.9428657 0.95 0.64024629 5.025587 1.11164951 Inf
11 0.7237778 0.4795111 0.95 0.19754885 2.651771 -0.48794745 Inf
12 1.9082659 1.7932841 0.95 0.30250055 12.037925 0.68762767 Inf
13 0.9728582 0.4977496 0.95 0.35689786 2.651888 -0.05378223 Inf
14 0.6873710 0.5672279 0.95 0.13638549 3.464290 -0.45428375 Inf
15 0.8019528 0.3969271 0.95 0.30398071 2.115688 -0.44591425 Inf
16 0.4997879 0.3958473 0.95 0.10582985 2.360279 -0.87568771 Inf
17 0.9333229 0.6598208 0.95 0.23348961 3.730751 -0.09760692 Inf
18 4.8818349 4.2302506 0.95 0.89328990 26.679258 1.82973852 Inf
p.value component y.level
1 0.833757356 log(mu[,2]/mu[,1]) Satisfaction
2 0.077332298 log(mu[,3]/mu[,1]) Insatisfaction
3 0.809029407 log(mu[,2]/mu[,1]) Satisfaction
4 0.415692863 log(mu[,3]/mu[,1]) Insatisfaction
5 0.735033605 log(mu[,2]/mu[,1]) Satisfaction
6 0.457868051 log(mu[,3]/mu[,1]) Insatisfaction
7 0.476754032 log(mu[,2]/mu[,1]) Satisfaction
8 0.291078645 log(mu[,3]/mu[,1]) Insatisfaction
9 0.003976778 log(mu[,2]/mu[,1]) Satisfaction
10 0.266288875 log(mu[,3]/mu[,1]) Insatisfaction
11 0.625587062 log(mu[,2]/mu[,1]) Satisfaction
12 0.491687277 log(mu[,3]/mu[,1]) Insatisfaction
13 0.957108667 log(mu[,2]/mu[,1]) Satisfaction
14 0.649624613 log(mu[,3]/mu[,1]) Insatisfaction
15 0.655659186 log(mu[,2]/mu[,1]) Satisfaction
16 0.381199829 log(mu[,3]/mu[,1]) Insatisfaction
17 0.922244427 log(mu[,2]/mu[,1]) Satisfaction
18 0.067289048 log(mu[,3]/mu[,1]) InsatisfactionPar contre, les dernières versions de ggstats sont compatibles avec ce type de modèle. On pourra donc utiliser les fonctions ggcoef_*().
ℹ <svy_vglm> model detected.✔ `tidy_svy_vglm()` used instead.ℹ Add `tidy_fun = broom.helpers::tidy_svy_vglm` to quiet these messages.`height` was translated to `width`.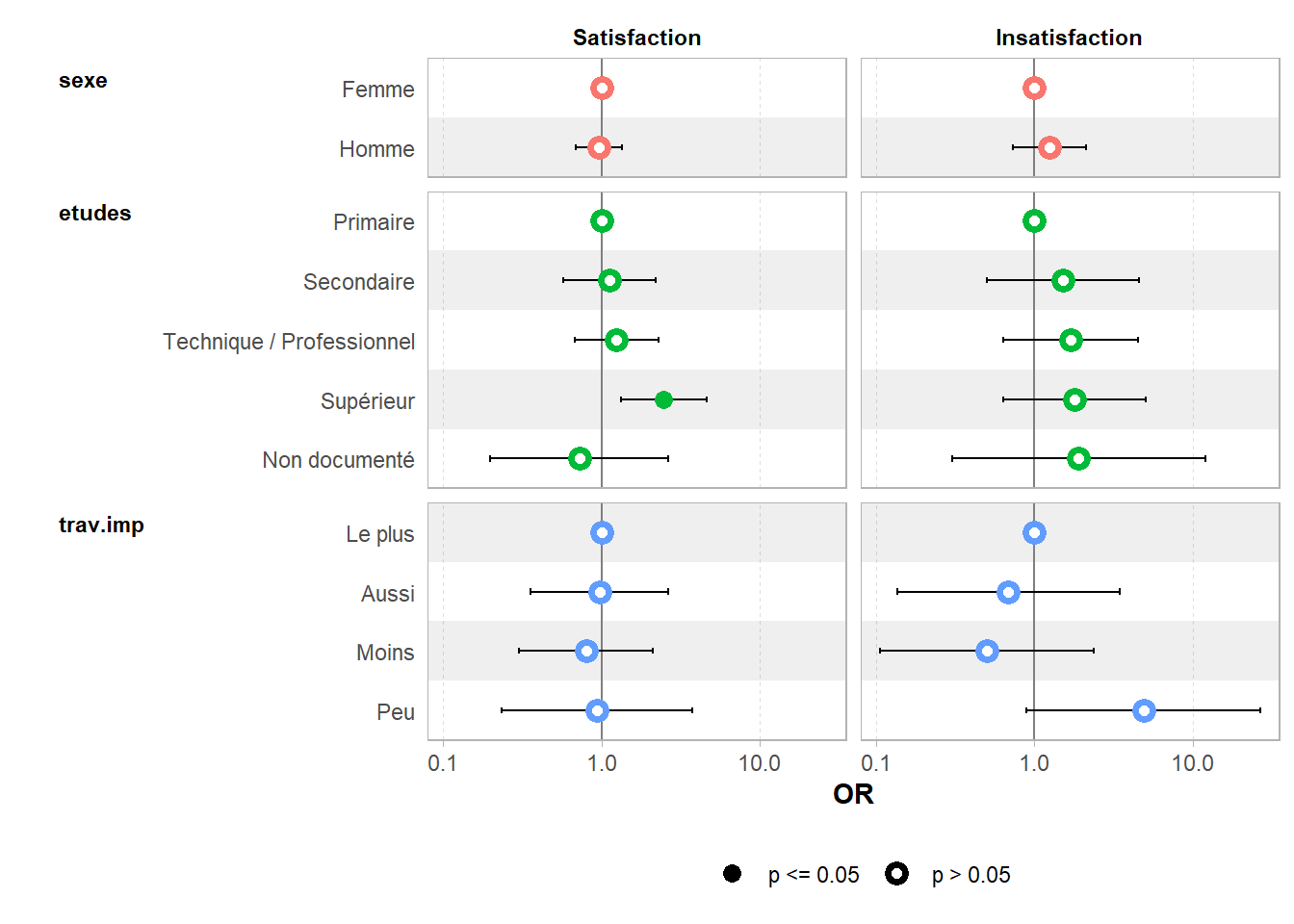
svy_vglm()(type “faceted”)
46.5 webin-R
La régression logistique multinomiale est abordée dans le webin-R #20 (trajectoires de soins : un exemple de données longitudinales (4)) sur YouTube.