| Characteristic |
I N = 681 |
II N = 681 |
III N = 641 |
Overall N = 2001 |
|---|---|---|---|---|
| Marker Level (ng/mL) | 1.0669 | 0.6805 | 0.9958 | 0.9160 |
| Unknown | 2 | 5 | 3 | 10 |
| 1 Mean | ||||
26 Contrastes (variables catégorielles)
Dans les modèles de régression (comme les modèles linéaires, cf. Chapitre 22, ou les modèles linéaires généralisés comme la régression logistique binaire, cf. Chapitre 23), une transformation des variables catégorielles est nécessaire pour qu’elles puissent être prises en compte dans le modèle. On va dès lors définir des contrastes.
De manière générale, une variable catégorielle à n modalités va être transformée en n-1 variables quantitatives. Il existe cependant plusieurs manières de faire (i.e. plusieurs types de contrastes). Et, selon les contrastes choisis, les coefficients du modèles ne s’interpréteront pas de la même manière.
26.1 Contrastes de type traitement
Par défaut, R applique des contrastes de type traitement
pour un facteur non ordonné. Il s’agit notamment des contrastes utilisés par défaut dans les chapitres précédents.
26.1.1 Exemple 1 : un modèle linéaire avec une variable catégorielle
Commençons avec un premier exemple que nous allons calculer avec le jeu de données trial chargé en mémoire lorsque l’on appelle l’extension gtsummary. Ce jeu de données contient les observations de 200 patients. Nous nous intéressons à deux variables en particulier : marker une variable numérique correspondant à un marqueur biologique et grade un facteur à trois modalités correspondant à différent groupes de patients.
Regardons la moyenne de marker pour chaque valeur de grade.
Utilisons maintenant une régression linaire pour modéliser la valeur de marker en fonction de grade.
Call:
lm(formula = marker ~ grade, data = trial)
Coefficients:
(Intercept) gradeII gradeIII
1.0669 -0.3864 -0.0711 Le modèle obtenu contient trois coefficients ou termes : un intercept et deux termes associés à la variable grade.
Pour bien interpréter ces coefficients, il faut comprendre comment la variable grade a été transformée avant d’être inclue dans le modèle. Nous pouvons voir cela avec la fonction contrasts().
Ce que nous montre cette matrice, c’est que la variable catégorielle grade à 3 modalités a été transformée en 2 variables binaires que l’on retrouve sous les noms de gradeII et gradeIII dans le modèle : gradeII vaut 1 si grade est égal à II et 0 sinon; gradeIII vaut 1 si grade est égal à III et 0 sinon. Si grade est égal à I, alors gradeII et gradeIII valent 0.
Il s’agit ici d’un contraste dit de traitement
ou la première modalité joue ici le rôle de modalité de référence.
Dans ce modèle linéaire, la valeur de l’intercept correspond à la moyenne de marker lorsque nous nous trouvons à la référence, donc quand grade est égal à I dans cet exemple. Et nous pouvons le constater dans notre tableau précédent des moyennes, 1.0669 correspond bien à la moyenne de marker pour la modalité I.
La valeur du coefficient associé à markerII correspond à l’écart par rapport à la référence lorsque marker est égal à II. Autrement dit, la moyenne de marker pour la modalité II correspond à la somme de l’intercept et du coefficient markerII. Et nous retrouvons bien la relation suivante : 0.6805 = 1.0669 + -0.3864. De même, la moyenne de marker lorsque grade vaut III est égale à la somme de l’intercept et du terme markerIII.
Lorsqu’on utilise des contrastes de type traitement, chaque terme du modèle peut être associé à une et une seule modalité d’origine de la variable catégorielle. Dès lors, il est possible de rajouter la modalité de référence lorsque l’on présente les résultats et on peut même lui associer la valeurs 0, ce qui peut être fait avec gtsummary::tbl_regression() avec l’option add_estimate_to_reference_rows = TRUE.
26.1.2 Exemple 2 : une régression logistique avec deux variables catégorielles
Pour ce deuxième exemple, nous allons utiliser le jeu de données hdv2003 fourni par l’extension questionr et recoder la variable age en groupes d’âges à 4 modalités.
Nous allons faire une régression logistique binaire pour investiguer l’effet du sexe (variable à 2 modalités) et du groupe d’âges (variable à 4 modalités) sur la pratique du sport.
Call: glm(formula = sport ~ sexe + groupe_ages, family = binomial,
data = hdv2003)
Coefficients:
(Intercept) sexeFemme groupe_ages25-44 groupe_ages45-64
0.9021 -0.4455 -0.6845 -1.6535
groupe_ages65+
-2.3198
Degrees of Freedom: 1999 Total (i.e. Null); 1995 Residual
Null Deviance: 2617
Residual Deviance: 2385 AIC: 2395Le modèle contient 5 termes : 1 intercept, 1 coefficient pour la variable sexe et 3 coefficients pour la variable groupe_ages. Comme précédemment, nous pouvons constater que les variables à n modalités sont remplacées par défaut (contrastes de type traitement) par n-1 variables binaires, la première modalité jouant à chaque fois le rôle de modalité de référence.
Femme
Homme 0
Femme 1 25-44 45-64 65+
16-24 0 0 0
25-44 1 0 0
45-64 0 1 0
65+ 0 0 1L’intercept correspond donc à la situation à la référence, c’est-à-dire à la prédiction du modèle pour les hommes (référence de sexe) âgés de 16 à 24 ans (référence de groupe_ages).
Il est possible d’exprimer cela en termes de probabilité en utilisant l’inverse de la fonction logit (puisque nous avons utilisé un modèle logit).
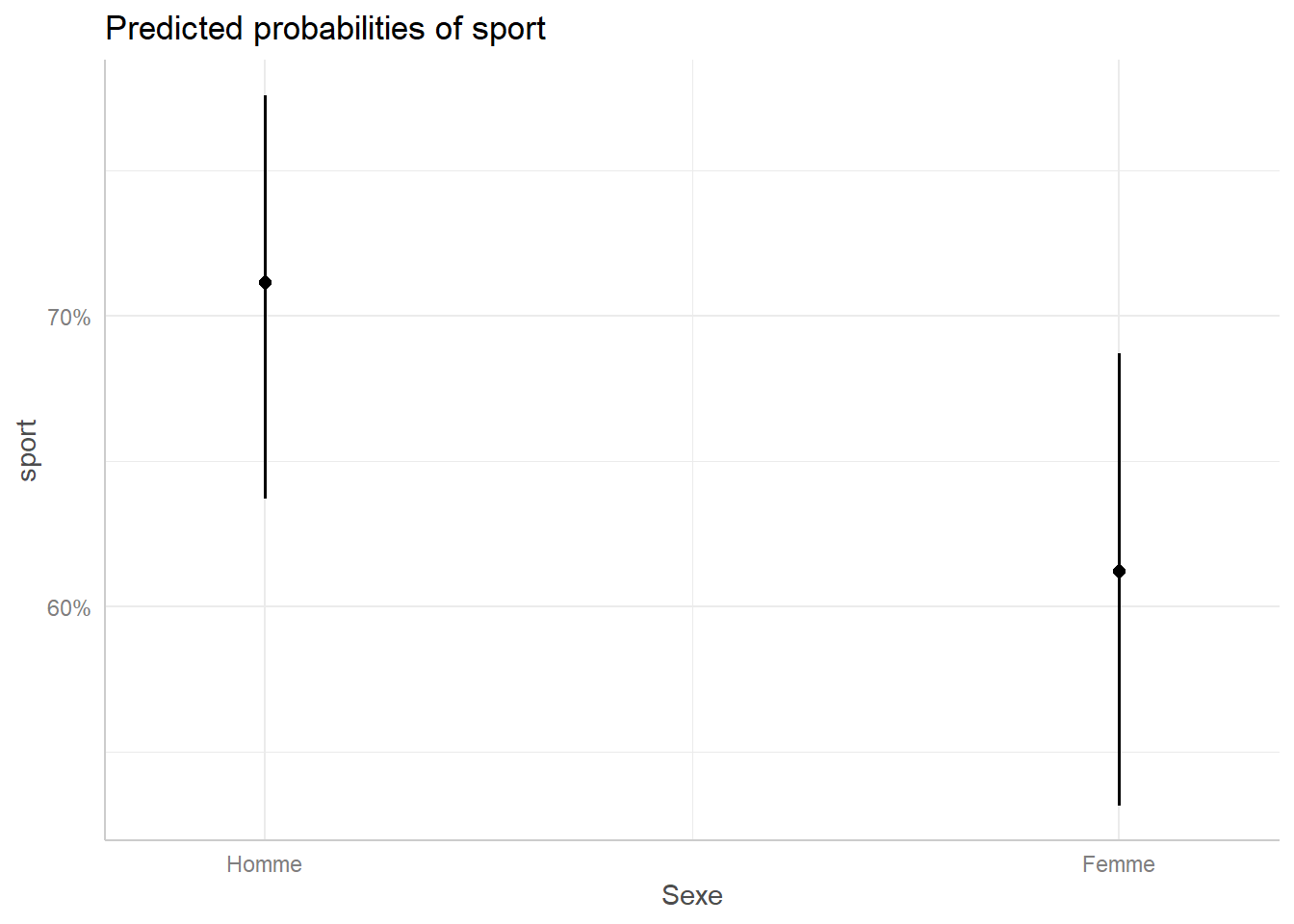
Selon le modèle, les hommes âgés de 16 à 24 ans ont donc 71% de chance de pratiquer du sport.
Regardons maintenant le coefficient associé à sexeFemme (-0.4455) : il représente (pour la modalité de référence des autres variables, soit pour les 16-24 ans ici) la correction à appliquer à l’intercept pour obtenir la probabilité de faire du sport. Il s’agit donc de la différence entre les femmes et les hommes pour le groupe des 16-24 ans.
Autrement dit, selon le modèle, la probabilité de faire du sport pour une femme âgée de 16 à 24 ans est de 61%. On peut représenter cela avec la fonction ggeffects::ggpredict() de ggeffects, qui représente les prédictions d’une variable toutes les autres variables étant à la référence
.
Bien souvent, pour une régression logistique, on préfère représenter les exponentielles des coefficients qui correspondent à des odds ratios.
| Characteristic | OR | 95% CI | p-value |
|---|---|---|---|
| (Intercept) | 2.46 | 1.76, 3.48 | <0.001 |
| Sexe | |||
| Homme | 1.00 | — | |
| Femme | 0.64 | 0.53, 0.78 | <0.001 |
| Groupe d'âges | |||
| 16-24 | 1.00 | — | |
| 25-44 | 0.50 | 0.35, 0.71 | <0.001 |
| 45-64 | 0.19 | 0.13, 0.27 | <0.001 |
| 65+ | 0.10 | 0.06, 0.15 | <0.001 |
| Abbreviations: CI = Confidence Interval, OR = Odds Ratio | |||
Or, 0,64 correspond bien à l’odds ratio entre 61% et 71% (que l’on peut calculer avec questionr::odds.ratio()).
De la même manière, les différents coefficients associés à groupe_ages correspondent à la différence entre chaque groupe d’âges et sa modalité de référence (ici 16-24 ans), quand les autres variables (ici le sexe) sont à leur référence (ici les hommes).
Pour prédire la probabilité de faire du sport pour un profil particulier, il faut prendre en compte toutes les termes qui s’appliquent et qui s’ajoutent à l’intercept. Par exemple, pour une femme de 50 ans il faut considérer l’intercept (0.9021), le coefficient sexeFemme (-0.4455) et le coefficient groupe_ages45-64 (-1.6535). Sa probabilité de faire du sport est donc de 23%.
26.1.3 Changer la modalité de référence
Il est possible de personnaliser les contrastes à utiliser et avoir un recours à un contraste de type traitement
mais en utilisant une autre modalité que la première comme référence, avec la fonction contr.treatment(). Le premier argument de la fonction corresponds au nombre de modalités de la variable et le paramètre base permets de spécifier la modalité de référence (1 par défaut).
contr.SAS() permets de spécifier un contraste de type traitement
dont la modalité de référence est la dernière.
Les contrastes peuvent être modifiés de deux manières : au moment de la construction du modèle (via l’option contrasts) ou comme attribut des variables (via la fonction contrasts()).
| Characteristic | OR | 95% CI | p-value |
|---|---|---|---|
| (Intercept) | 0.30 | 0.25, 0.36 | <0.001 |
| Sexe | |||
| Homme | 1.56 | 1.29, 1.90 | <0.001 |
| Femme | — | — | |
| Groupe d'âges | |||
| 16-24 | 5.23 | 3.67, 7.52 | <0.001 |
| 25-44 | 2.64 | 2.12, 3.29 | <0.001 |
| 45-64 | — | — | |
| 65+ | 0.51 | 0.37, 0.70 | <0.001 |
| Abbreviations: CI = Confidence Interval, OR = Odds Ratio | |||
Comme les modalités de référence ont changé, l’intercept et les différents termes ont également changé (puisque l’on ne compare plus à la même référence).
`height` was translated to `width`.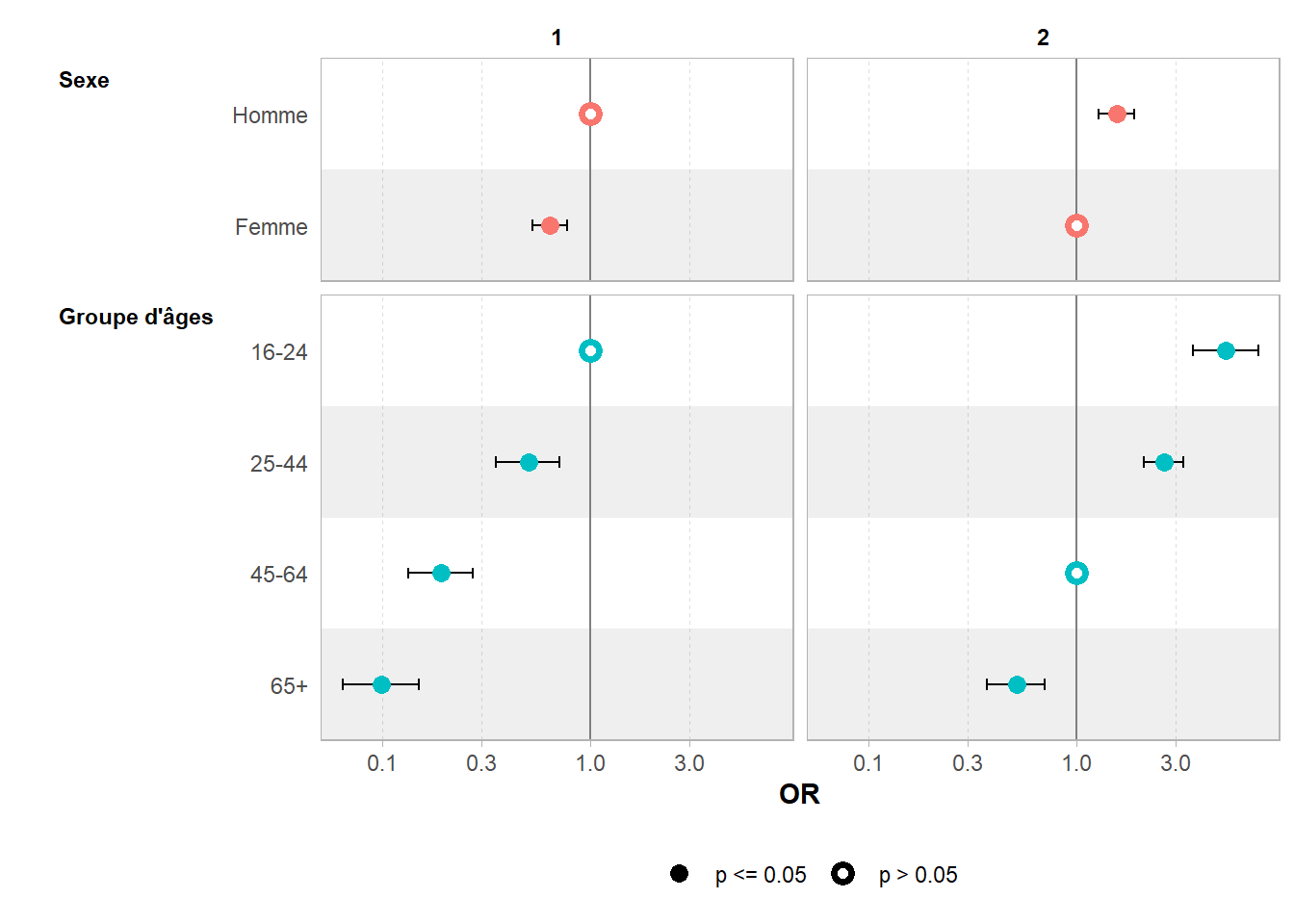
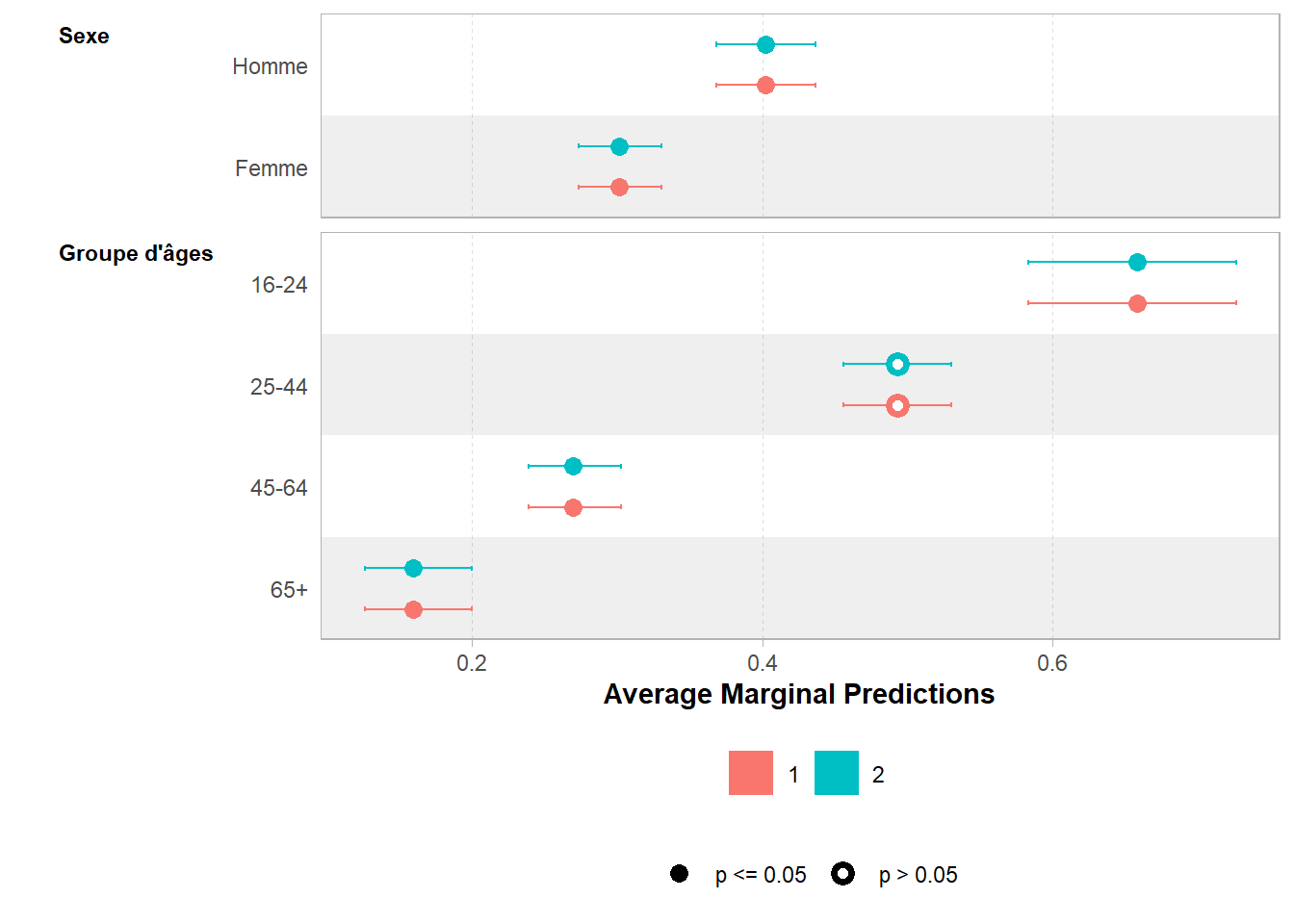
Cependant, du point de vue explicatif et prédictif, les deux modèles sont rigoureusement identiques.
Analysis of Deviance Table
Model 1: sport ~ sexe + groupe_ages
Model 2: sport ~ sexe + groupe_ages
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 1995 2385.2
2 1995 2385.2 0 0 De même, leurs prédictions marginales (cf. Chapitre 25) sont identiques.
26.2 Contrastes de type somme
Nous l’avons vu, les contrastes de type traitement
nécessitent de définir une modalité de référence et toutes les autres modalités seront comparées à cette modalité de référence. Une alternative consiste à comparer toutes les modalités à la grande moyenne
, ce qui s’obtient avec un contraste de type somme
que l’on obtient avec contr.sum().
26.2.1 Exemple 1 : un modèle linéaire avec une variable catégorielle
Reprenons notre premier exemple de tout à l’heure et modifions seulement le contraste.
Call:
lm(formula = marker ~ grade, data = trial)
Coefficients:
(Intercept) grade1 grade2
0.9144 0.1525 -0.2339 L’intercept correspond à ce qu’on appelle parfois la grande moyenne
(ou great average en anglais). Il ne s’agit pas de la moyenne observée de marker mais de la moyenne des moyennes de chaque sous-groupe. Cela va constituer la situation de référence de notre modèle, en quelque sorte indépendante des effets de la variable grade.
[1] 0.9159895# A tibble: 3 × 2
grade moyenne_marker
<fct> <dbl>
1 I 1.07
2 II 0.681
3 III 0.996[1] 0.9144384Le terme grade1 correspond quant à lui au modificateur associé à la première modalité de la variable grade à savoir I. C’est l’écart, pour cette modalité, à la grande moyenne : 1.0669 - 0.9144 = 0.1525.
De même, le terme grade2 correspond à l’écart pour la modalité II par rapport à la grande moyenne : 0.6805 - 0.9144 = -0.2339.
Qu’en est-il de l’écart à la grande moyenne pour la modalité III ? Pour cela, voyons tout d’abord comment la variable grade a été codée :
Comme précédemment, cette variable à trois modalités a été codée avec deux termes. Les deux premiers termes correspondent aux écarts à la grande moyenne des deux premières modalités. La troisième modalité est, quant à elle, codée systématiquement -1. C’est ce qui assure que la somme des contributions soit nulle et donc que l’intercept capture la grande moyenne.
L’écart à la grande moyenne pour la troisième modalité s’obtient donc en faisant la somme des autres termes et en l’inversant : (0.1525 - 0.2339) * -1 = 0.0814 = 0.9958 - 0.9144.
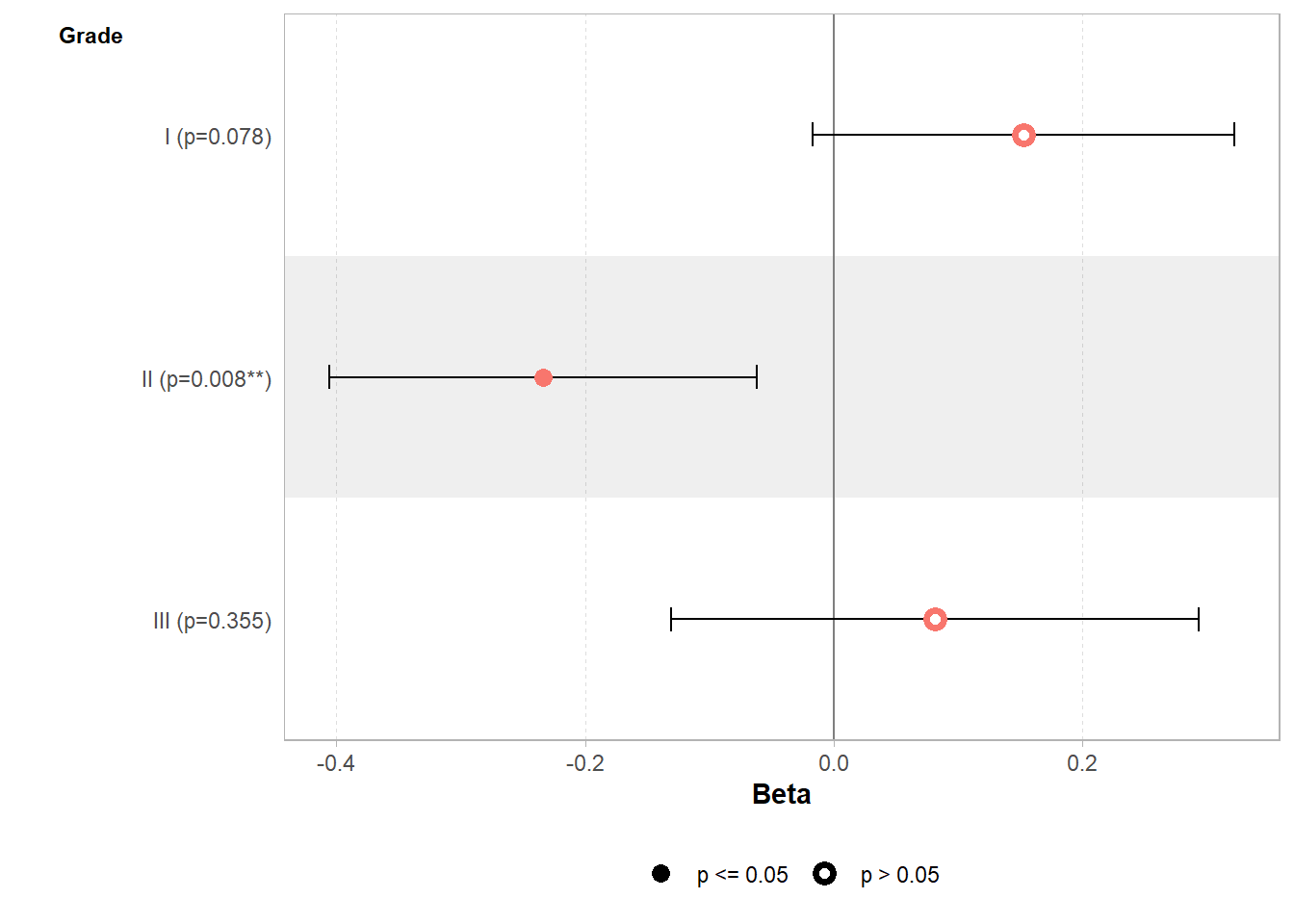
On peut calculer / afficher la valeur associée à la dernière modalité en précisant add_estimate_to_reference_rows = TRUE lorsque l’on appelle gtsummary::tbl_regression().
| Characteristic | Beta | 95% CI | p-value |
|---|---|---|---|
| (Intercept) | 0.91 | 0.79, 1.0 | <0.001 |
| Grade | |||
| I | 0.15 | -0.02, 0.32 | 0.078 |
| II | -0.23 | -0.41, -0.06 | 0.008 |
| III | 0.08 | -0.13, 0.29 | 0.4 |
| Abbreviation: CI = Confidence Interval | |||
De même, cette valeur est correctement affichée par ggstats::ggcoef_model().
Le fait d’utiliser des contrastes de type traitement
ou somme
n’a aucun impact sur la valeur prédictive du modèle. La quantité de variance expliquée, la somme des résidus ou encore l’AIC sont identiques. En un sens, il s’agit du même modèle. C’est seulement la manière d’interpréter les coefficients du modèle qui change.
26.2.2 Exemple 2 : une régression logistique avec deux variables catégorielles
Reprenons notre second exemple et codons les variables catégorielles avec un traitement de type somme
.
| Characteristic | OR | 95% CI | p-value |
|---|---|---|---|
| (Intercept) | 0.62 | 0.55, 0.69 | <0.001 |
| Sexe | |||
| Homme | 1.25 | 1.13, 1.38 | <0.001 |
| Femme | 0.80 | 0.72, 0.89 | <0.001 |
| Groupe d'âges | |||
| 16-24 | 3.20 | 2.49, 4.15 | <0.001 |
| 25-44 | 1.62 | 1.38, 1.89 | <0.001 |
| 45-64 | 0.61 | 0.52, 0.72 | <0.001 |
| 65+ | 0.31 | 0.24, 0.42 | <0.001 |
| Abbreviations: CI = Confidence Interval, OR = Odds Ratio | |||
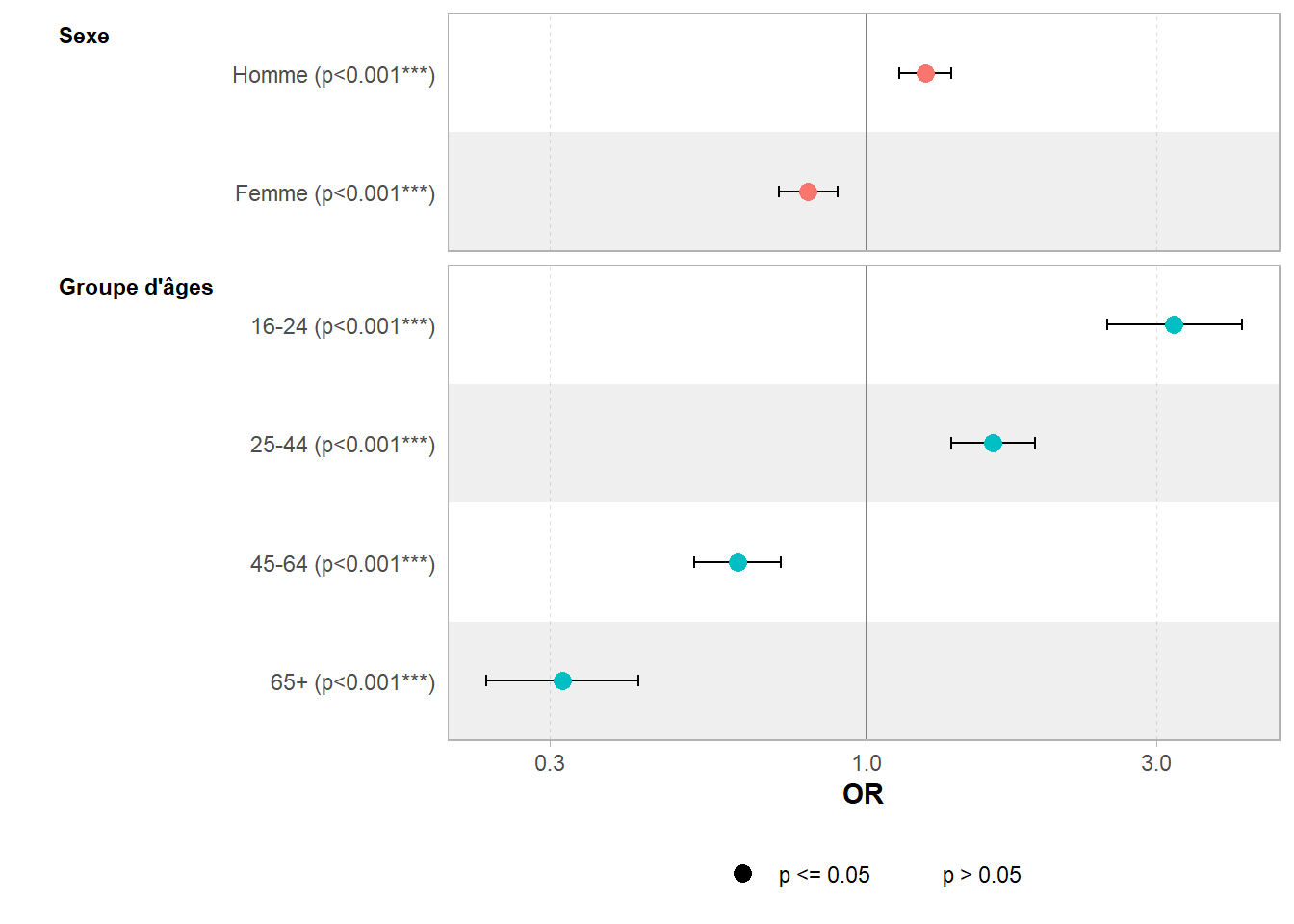
Cette fois-ci, l’intercept capture la situation à la grande moyenne
à la fois du sexe et du groupe d’âges, et les coefficients s’interprètent donc comme modificateurs de chaque modalité par rapport à cette grande moyenne
. En ce sens, les contrastes de type somme
permettent donc de capturer l’effet de chaque modalité.
Du point de vue explicatif et prédictif, le fait d’avoir recours à des contrastes de type somme ou traitement n’a aucun impact : les deux modèles sont rigoureusement identiques. Il n’y a que la manière d’interpréter les coefficients qui change.
Analysis of Deviance Table
Model 1: sport ~ sexe + groupe_ages
Model 2: sport ~ sexe + groupe_ages
Resid. Df Resid. Dev Df Deviance Pr(>Chi)
1 1995 2385.2
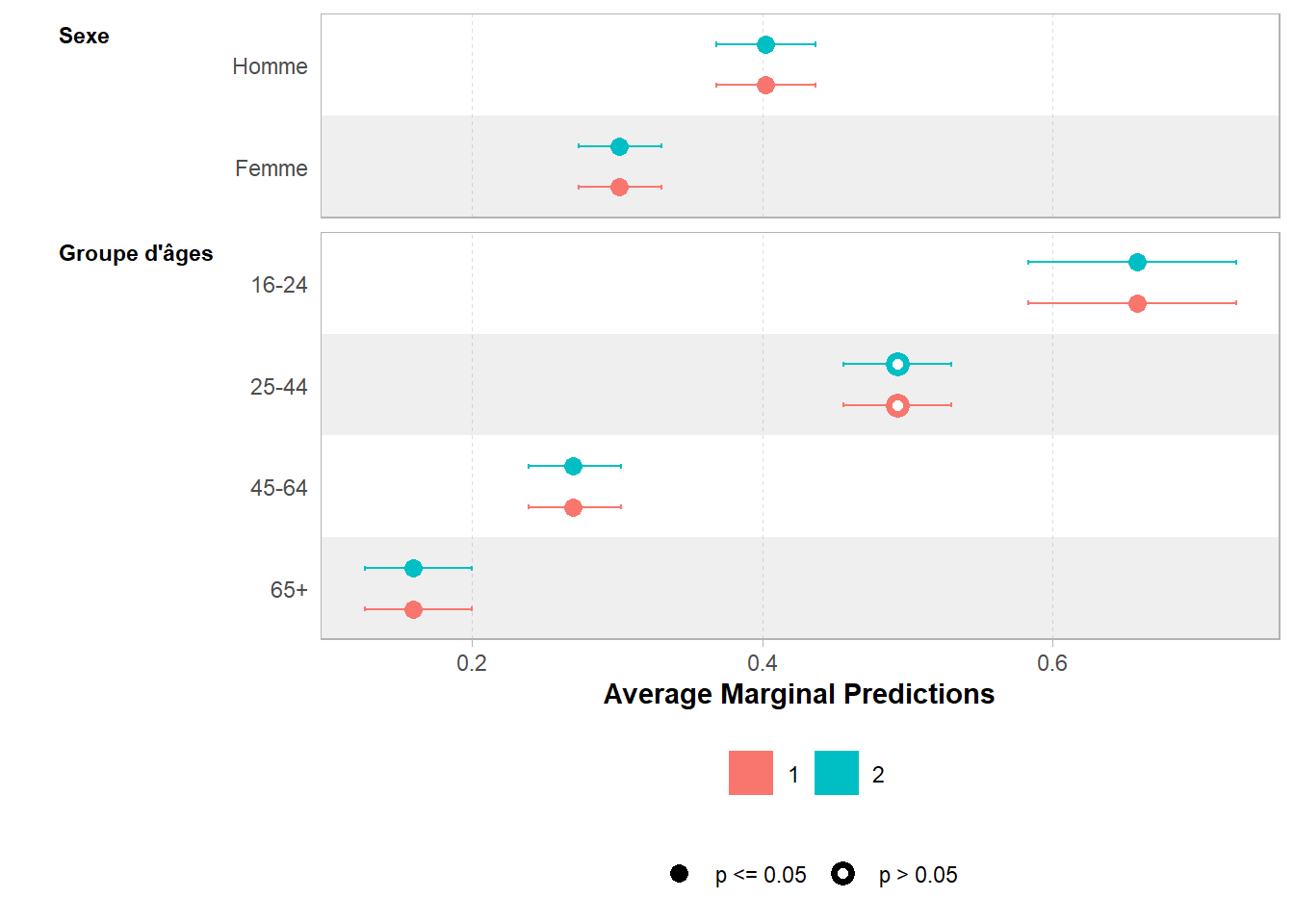
2 1995 2385.2 0 0 Les prédictions marginales (cf. Chapitre 25) sont identiques.
26.3 Contrastes par différences successives
Les contrastes par différences successives consistent à comparer la deuxième modalité à la première, puis la troisième modalité à la seconde, etc. Ils sont disponibles avec la fonction MASS::contr.sdif().
Illustrons cela avec un exemple.
26.3.1 Exemple 1 : un modèle linéaire avec une variable catégorielle
| Characteristic | Beta | 95% CI | p-value |
|---|---|---|---|
| (Intercept) | 0.91 | 0.79, 1.0 | <0.001 |
| Grade | |||
| II - I | -0.39 | -0.68, -0.09 | 0.010 |
| III - II | 0.32 | 0.02, 0.62 | 0.040 |
| Abbreviation: CI = Confidence Interval | |||
En premier lieu, on notera que l’intercept, comme avec les contrastes de type somme, correspond ici à la grande moyenne.
Cela est lié au fait que la somme des coefficients dans ce type de contrastes est égale à 0.
De plus, la matrice de contrastes est calculée de telle manière que l’écart entre les deux premières modalités vaut 1 pour le premier terme, et l’écart entre la seconde et la troisième modalité vaut également 1 pour le deuxième terme.
Ainsi, le terme gradeII-I correspond à la différence entre la moyenne du grade de niveau II et celle du niveau I1.
1 On peut remarquer que la même valeur était obtenue avec un contraste de type traitement où toutes les modalités étaient comparées à la modalité de référence I.
Et le coefficient gradeIII-II à l’écart entre la moyenne du niveau III et celle du niveau II.
26.3.2 Exemple 2 : une régression logistique avec deux variables catégorielles
La même approche peut être appliquée à une régression logistique.
| Characteristic | OR | 95% CI | p-value |
|---|---|---|---|
| (Intercept) | 0.62 | 0.55, 0.69 | <0.001 |
| Sexe | |||
| Femme / Homme | 0.64 | 0.53, 0.78 | <0.001 |
| Groupe d'âges | |||
| 25-44 / 16-24 | 0.50 | 0.35, 0.71 | <0.001 |
| 45-64 / 25-44 | 0.38 | 0.30, 0.47 | <0.001 |
| 65+ / 45-64 | 0.51 | 0.37, 0.70 | <0.001 |
| Abbreviations: CI = Confidence Interval, OR = Odds Ratio | |||
On pourra noter que les odds ratios “femme/homme” et “25-44/16-24” obtenus ici sont équivalents à ceux que l’on avait obtenus précédemment avec des contrastes de types de traitement. Pour la modalité “45-64 ans” par contre, elle est ici comparée aux 25-44 ans, alors qu’avec un contraste de type traitement, toutes les comparaisons auraient eu lieu avec la même modalité de référence, à savoir les 16-24 ans.
Les contrastes par différences successives font donc plutôt sens lorsque les modalités sont ordonnées (d’où l’intérêt de comparer avec la modalité précédente), ce qui n’est pas forcément le cas lorsque les modalités ne sont pas ordonnées.
Astuce
De manière générale, et quels que soient les contrastes utilisés pour le calcul du modèle, il est toujours possible de recalculer a posteriori les différences entre chaque combinaison de modalités deux à deux avec emmeans::emmeans(). Cela peut même se faire directement en passant l’argument add_pairwise_contrasts = TRUE à tbl_regression().
| Characteristic | OR | 95% CI | p-value |
|---|---|---|---|
| Sexe | |||
| Femme / Homme | 0.64 | 0.53, 0.78 | <0.001 |
| Groupe d'âges | |||
| (25-44) / (16-24) | 0.50 | 0.32, 0.80 | <0.001 |
| (45-64) / (16-24) | 0.19 | 0.12, 0.31 | <0.001 |
| (45-64) / (25-44) | 0.38 | 0.28, 0.51 | <0.001 |
| (65+) / (16-24) | 0.10 | 0.06, 0.17 | <0.001 |
| (65+) / (25-44) | 0.19 | 0.13, 0.29 | <0.001 |
| (65+) / (45-64) | 0.51 | 0.34, 0.78 | <0.001 |
| Abbreviations: CI = Confidence Interval, OR = Odds Ratio | |||
26.4 Autres types de contrastes
26.4.1 Contrastes de type Helmert
Les contrastes de Helmert sont un peu plus complexes : ils visent à comparer la seconde modalité à la première, la troisième à la moyenne des deux premières, la quatrième à la moyenne des trois premières, etc.
Prenons un exemple avec une variable catégorielle à quatre modalités.
[,1] [,2] [,3]
T1 -1 -1 -1
T2 1 -1 -1
T3 0 2 -1
T4 0 0 3
Call:
lm(formula = marker ~ stage, data = trial)
Coefficients:
(Intercept) stage1 stage2 stage3
0.91661 0.19956 0.03294 -0.02085 Pour bien comprendre comment interpréter ces coefficients, calculons déjà la grande moyenne
.
[1] 0.9166073On le voit, l’intercept (0.9166) capture ici cette grande moyenne
, à savoir la moyenne des moyennes de chaque sous-groupe.
Maintenant, pour interpréter les coefficients, regardons comment évolue la moyenne à chaque fois que l’on ajoute une modalité. La fonction dplyr::cummean() nous permet de calculer la moyenne cumulée, c’est-à-dire la moyenne de la valeur actuelle et des valeurs des lignes précédentes. Avec dplyr::lag() nous pouvons obtenir la moyenne cumulée de la ligne précédente. Il nous est alors possible de calculer l’écart entre les deux, et donc de voir comment la moyenne a changé avec l’ajout d’une modalité.
# A tibble: 4 × 5
stage moy moy_cum moy_cum_prec ecart
<fct> <dbl> <dbl> <dbl> <dbl>
1 T1 0.705 0.705 NA NA
2 T2 1.10 0.905 0.705 0.200
3 T3 1.00 0.937 0.905 0.0329
4 T4 0.854 0.917 0.937 -0.0208On le voit, les valeurs de la colonne ecart correspondent aux coefficients du modèle.
Le premier terme stage1 compare la deuxième modalité (T2) à la première (T1) et indique l’écart entre la moyenne des moyennes de T1 et T2 et la moyenne de T1.
Le second terme stage2 compare la troisième modalité (T3) aux deux premières (T1 et T2) et indique l’écart entre la moyenne des moyennes de T1, T2 et T3 par rapport à la moyenne des moyennes de T1 et T2.
Le troisième terme stage3 compare la quatrième modalité (T4) aux trois premières (T1, T2 et T3) et indique l’écart entre la moyenne des moyennes de T1, T2, T3 et T4 par rapport à la moyenne des moyennes de T1, T2 et T3.
Les contrastes de Helmert sont ainsi un peu plus complexes à interpréter et à réserver à des cas particuliers où ils prennent tout leur sens.
26.4.2 Contrastes polynomiaux
Les contrastes polynomiaux, définis avec contr.poly(), sont utilisés par défaut pour les variables catégorielles ordonnées. Ils permettent de décomposer les effets selon une composante linéaire, une composante quadratique, une composante cubique, voire des composantes de degrés supérieurs.
.L .Q .C
T1 -0.6708204 0.5 -0.2236068
T2 -0.2236068 -0.5 0.6708204
T3 0.2236068 -0.5 -0.6708204
T4 0.6708204 0.5 0.2236068
Call:
lm(formula = marker ~ stage, data = trial)
Coefficients:
(Intercept) stage.L stage.Q stage.C
0.91661 0.07749 -0.27419 0.10092 Ici aussi, l’intercept correspond à la grande moyenne des moyennes
. Il est par contre plus difficile de donner un sens interprétatif / sociologique aux différents coefficients.
26.5 Lectures additionnelles
- A (sort of) Complete Guide to Contrasts in R par Rose Maier
- An introductory explanation of contrast coding in R linear models par Athanassios Protopapas
- Understanding Sum Contrasts for Regression Models: A Demonstration par Mona Zhu