Les échelles de Likert tirent leur nom du psychologue américain Rensis Likert qui les a développées. Elles sont le plus souvent utilisées pour des variables d’opinion. Elles sont codées sous forme de variable catégorielle et chaque item est codé selon une graduation comprenant en général cinq ou sept choix de réponse, par exemple : Tout à fait d’accord, D’accord, Ni en désaccord ni d’accord, Pas d’accord, Pas du tout d’accord.
Pour les échelles à nombre impair de choix, le niveau central permet d’exprimer une absence d’avis, ce qui rend inutile une modalité « Ne sait pas ». Les échelles à nombre pair de modalités voient l’omission de la modalité neutre et sont dites « à choix forcé ».
20.1 Exemple de données
Générons un jeu de données qui nous servira pour les différents exemples.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.2.0 ✔ readr 2.1.6
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.2 ✔ tibble 3.3.1
✔ lubridate 1.9.5 ✔ tidyr 1.3.2
✔ purrr 1.2.1
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Cependant, cela produit un tableau inutilement long, d’autant plus que les variables q1 à q6 ont les mêmes modalités de réponse. La fonction gtsummary::tbl_likert() offre un affichage plus compact.
df |>tbl_likert(include = q1:q6 )
Characteristic
Pas du tout d’accord
Plutôt pas d’accord
Ni d’accord, ni pas d’accord
Plutôt d’accord
Tout à fait d’accord
Première question
39 (26%)
32 (21%)
25 (17%)
30 (20%)
24 (16%)
Seconde question
56 (37%)
44 (29%)
19 (13%)
26 (17%)
5 (3.3%)
Troisième question
8 (5.3%)
17 (11%)
29 (19%)
43 (29%)
53 (35%)
Quatrième question
11 (7.3%)
19 (13%)
31 (21%)
40 (27%)
49 (33%)
Cinquième question
33 (26%)
25 (20%)
28 (22%)
25 (20%)
16 (13%)
Sixième question
50 (33%)
0 (0%)
50 (33%)
50 (33%)
0 (0%)
On peut utiliser add_n() pour ajouter les effectifs totaux.
Dans certains contextes, il est envisageable de traiter notre variable ordinale comme un score numérique. Ici, nous allons attribuer les valeurs -2, -1, 0, +1 et +2 à nos 5 modalités. Dès lors, nous pourrions être intéressé de rajouter à notre tableau le score moyen. Cela est possible en quelques étapes :
transformer nos facteurs en scores : les fonctions as.integer() ou unclass() permettent de transformer un facteur en valeurs numériques (1 pour la première modalité, 2 pour la seconde, etc.). Dans le cas présent, il est préférable d’utiliser unclass() qui préserve les étiquettes de variables ce qui n’est pas le cas de as.integer(). Il ne faut pas oublier de retirer 3 pour obtenir des scores allant de -2 à +2. La fonction dplyr::across() permet d’effectuer l’opération sur plusieurs variables en même temps.
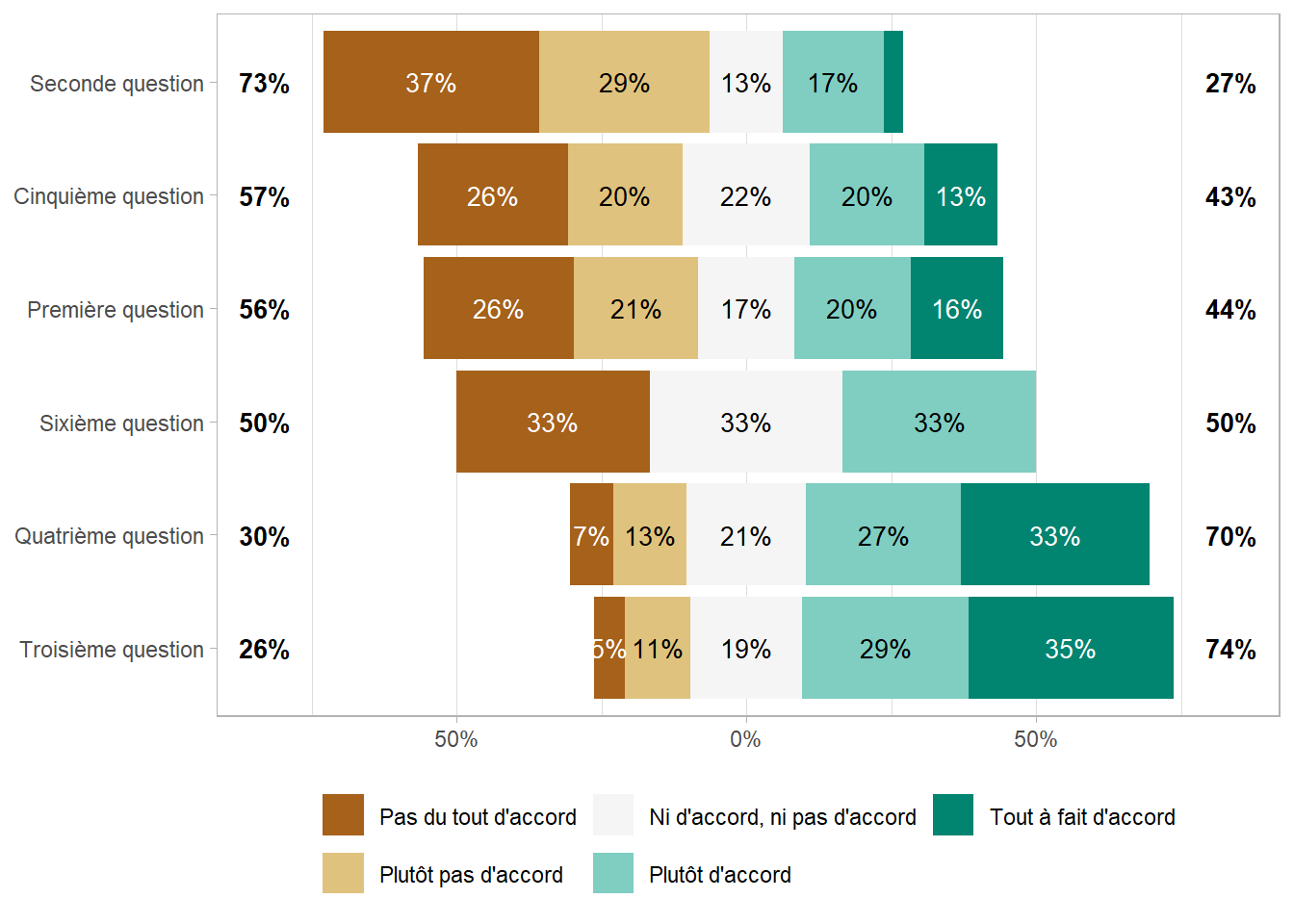
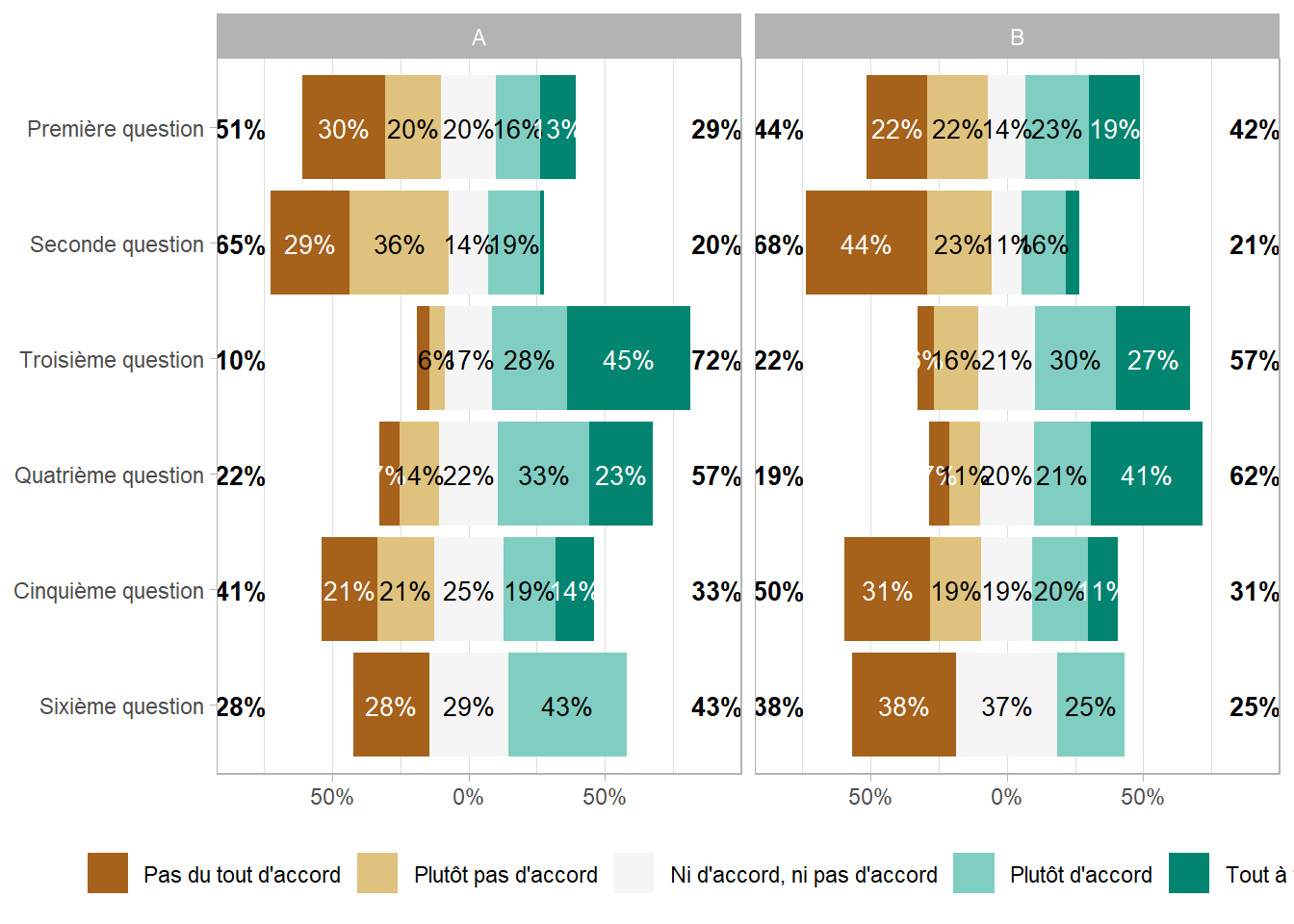
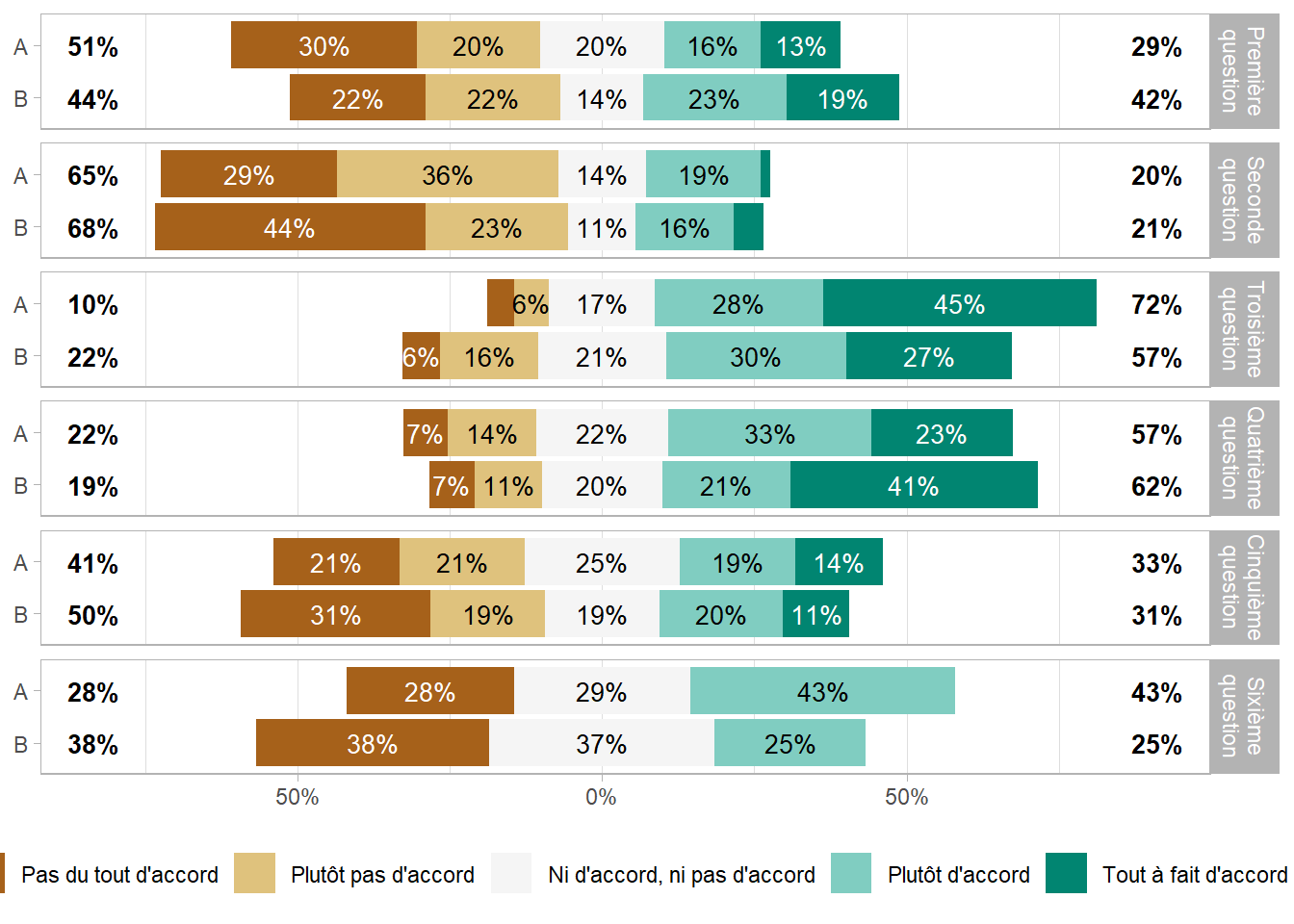
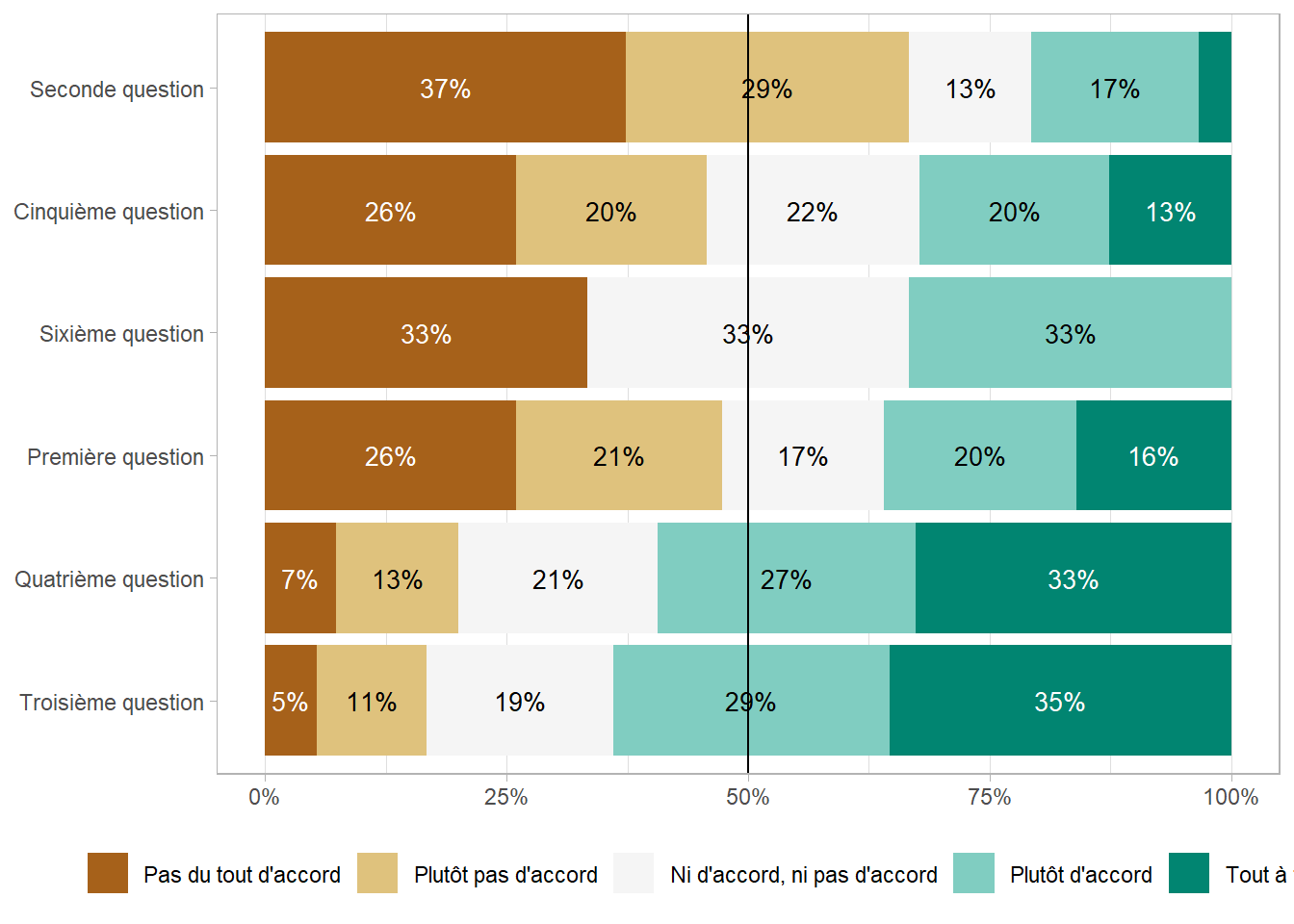
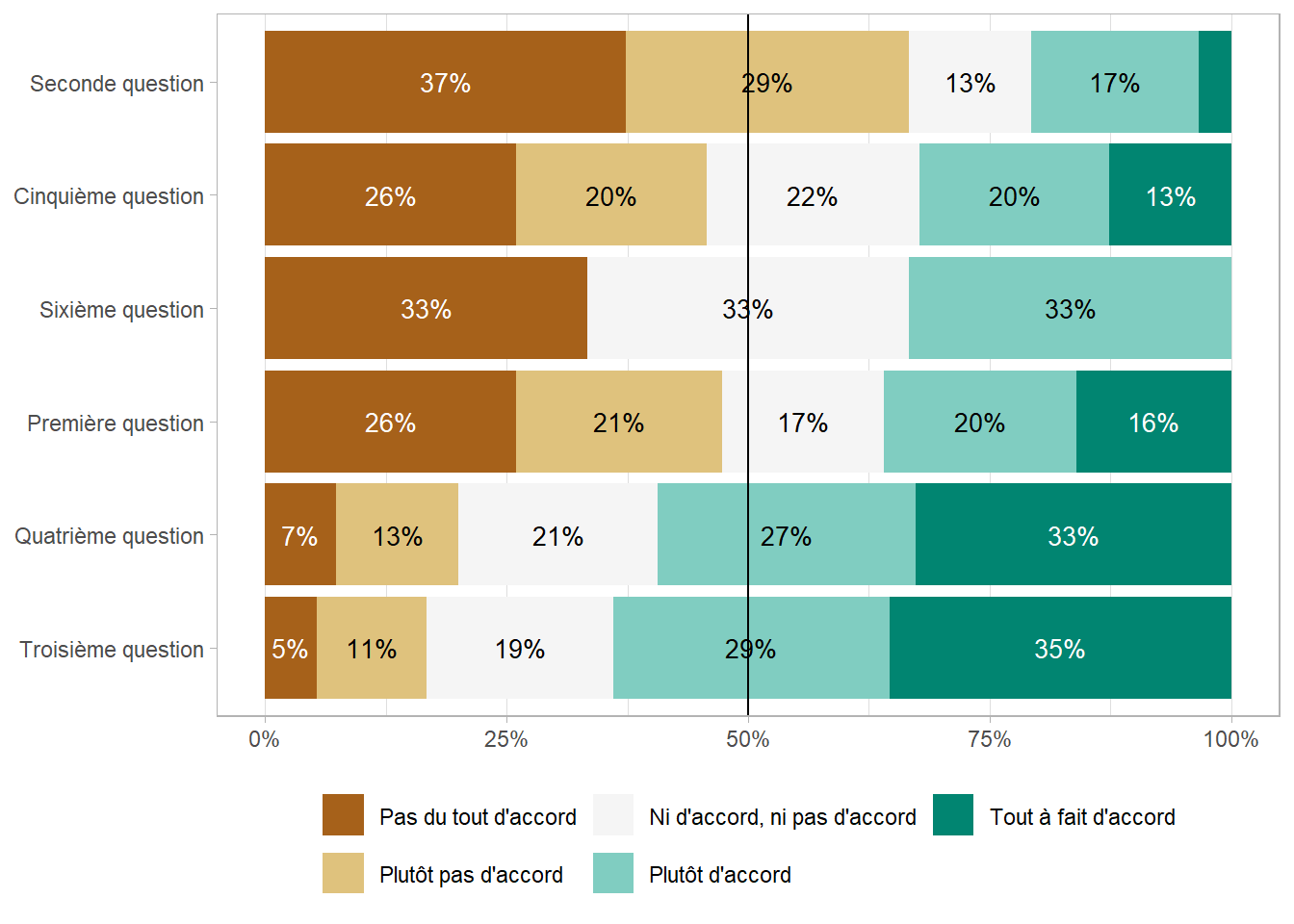
Le package ggstats propose une fonction ggstats::gglikert() pour représenter des données de Likert sous la forme d’un diagramme en barres centré sur la modalité centrale.
library(ggstats)gglikert(df, include = q1:q6)
Par défaut, les pourcentages totaux ne prennent pas en compte la modalité centrale (lorsque le nombre de modalité est impair). On peut inclure la modalité centrale avec totals_include_center = TRUE, auquel cas la modalité centrale seront comptabilisée pour moitié de chaque côté. Le paramètre sort permet de trier les modalités (voir l’aide de ggstats::gglikert() pour plus de détails sur les différentes méthodes de tri).
Certains auteurs préconisent de représenter les indécis / ne sait pas à part, sous la forme d’un graphique en barres sur le côté. Cela peut être obtenu avec ggstats::gglikert_side().
df |>gglikert_side(include = q1:q6,side_values ="Ni d'accord, ni pas d'accord",sort ="ascending" )
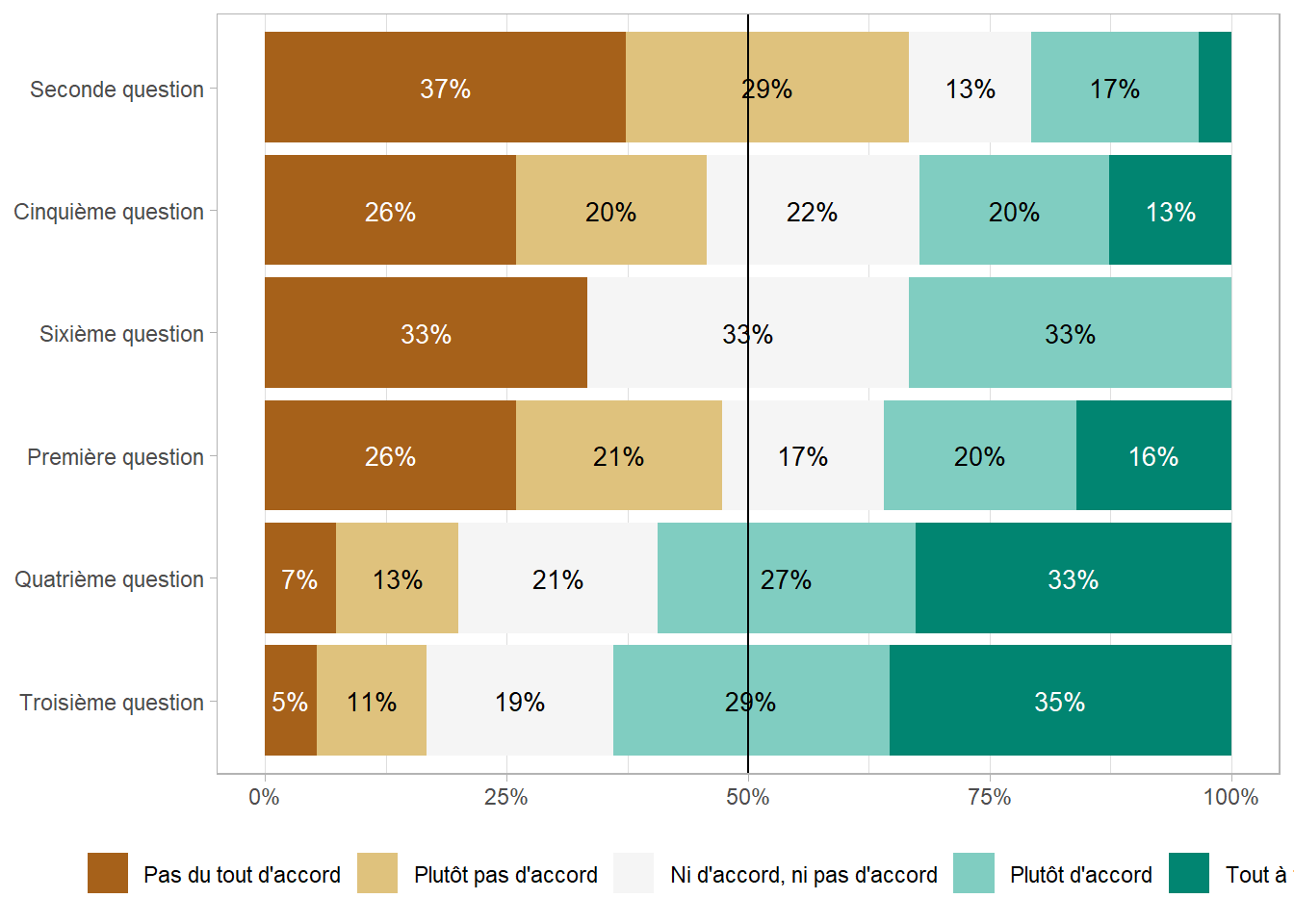
Une représentation alternative consiste à réaliser un graphique en barres classiques, ce que l’on peut aisément obtenir avec ggstats::gglikert_stacked().