48 Régression logistique ordinale
La régression logistique ordinale est une extension de la régression logistique binaire (cf. Chapitre 23) aux variables qualitatives à trois modalités ou plus qui sont ordonnées, par exemple modéré, moyen et fort.
Pour une variable ordonnée, il est possible de réaliser une régression logistique multinomiale (cf. Chapitre 47) comme on le ferait avec une variable non ordonnée. Dans ce cas de figure, chaque modalité de la variable d’intérêt serait comparée à une modalité de référence.
Alternativement, on peut réaliser une régression logistique ordinale aussi appelée modèle cumulatif ou modèle logistique à égalité des pentes. Ce type de modèle est plus simple que la régression multinomiale car il ne renvoie qu’un seul jeu de coefficients.
Supposons une variable d’intérêt à trois modalités A, B et C telles que A < B < C. Les odds ratios qui seront calculés comparerons la probabilité que Y≥B par rapport à la probabilité que Y≤A (aspect cumulatif) et ferons l’hypothèse que ce ratio est le même quand on compare la probabilité que Y≥C par rapport à la probabilité que Y≤B (égalité des pentes).
48.1 Données d’illustration
Pour illustrer la régression logistique multinomiale, nous allons reprendre le jeu de données hdv2003 du package questionr et portant sur l’enquête histoires de vie 2003 de l’Insee et l’exemple utilisé dans le chapitre sur la régression logistique multinomiale (cf. Chapitre 47).
Nous allons considérer comme variable d’intérêt la variable trav.satisf, à savoir la satisfaction ou l’insatisfaction au travail.
# A tibble: 4 × 4
trav.satisf n N prop
<fct> <int> <int> <dbl>
1 Satisfaction 480 2000 24
2 Insatisfaction 117 2000 5.85
3 Equilibre 451 2000 22.6
4 <NA> 952 2000 47.6 Nous allons devoir ordonner les modalités de la plus faible à la plus forte.
Et nous allons indiquer qu’il s’agit d’un facteur ordonné.
Nous allons aussi en profiter pour raccourcir les étiquettes de la variable trav.imp :
Enfin, procédons à quelques recodages additionnels :
d <- d |>
mutate(
sexe = sexe |> fct_relevel("Femme"),
groupe_ages = age |>
cut(
c(18, 25, 45, 99),
right = FALSE,
include.lowest = TRUE,
labels = c("18-24 ans", "25-44 ans",
"45 et plus")
),
etudes = nivetud |>
fct_recode(
"Primaire" = "N'a jamais fait d'etudes",
"Primaire" = "A arrete ses etudes, avant la derniere annee d'etudes primaires",
"Primaire" = "Derniere annee d'etudes primaires",
"Secondaire" = "1er cycle",
"Secondaire" = "2eme cycle",
"Technique / Professionnel" = "Enseignement technique ou professionnel court",
"Technique / Professionnel" = "Enseignement technique ou professionnel long",
"Supérieur" = "Enseignement superieur y compris technique superieur"
) |>
fct_na_value_to_level("Non documenté")
) |>
set_variable_labels(
trav.satisf = "Satisfaction dans le travail",
sexe = "Sexe",
groupe_ages = "Groupe d'âges",
etudes = "Niveau d'études",
trav.imp = "Importance accordée au travail"
)48.2 Calcul du modèle ordinal
48.2.1 avec MASS::polr()
Le plus facile pour le calcul d’un modèle ordinal est d’avoir recours à la fonction MASS::polr().
Nous pouvons aisément simplifier le modèle avec step() (cf. Chapitre 24).
Start: AIC=1978.29
trav.satisf ~ sexe + etudes + groupe_ages + trav.imp
Df AIC
- groupe_ages 2 1977.2
- sexe 1 1978.3
<none> 1978.3
- etudes 4 1991.5
- trav.imp 3 2014.0
Step: AIC=1977.23
trav.satisf ~ sexe + etudes + trav.imp
Df AIC
- sexe 1 1977.0
<none> 1977.2
- etudes 4 1990.6
- trav.imp 3 2013.2
Step: AIC=1976.97
trav.satisf ~ etudes + trav.imp
Df AIC
<none> 1977.0
- etudes 4 1990.6
- trav.imp 3 2011.648.2.2 Fonctions alternatives
Un package alternatif pour le calcul de régressions ordinales est le package dédié ordinal et sa fonction ordinal::clm(). Pour les utilisateurs avancés, ordinal permet également de traiter certains prédicteurs comme ayant un effet nominal (et donc avec un coefficient par niveau) via l’argument nominal. Il existe également une fonction ordinal::clmm() permet de définir des modèles mixtes avec variables à effet aléatoire.
Les modèles créés avec ordinal::clm() sont plutôt bien traités par des fonctions comme gtsummary::tbl_regression() ou ggstats::ggcoef_model().
Enfin, on peut également citer la fonction VGAM::vgam() en spécifiant family = VGAM::cumulative(parallel = TRUE). Cette famille de modèles offre des options avancées (par exemple il est possible de calculer des modèles non parallèles, c’est-à-dire avec une série de coefficients pour chaque changement de niveau). Par contre, le support de gtsummary::tbl_regression() et ggstats::ggcoef_model() sera limité (seulement des résultats bruts).
En toute rigueur, il faudrait tester l’égalité des pentes. Laurent Rouvière propose un code permettant d’effectuer ce test sous R à partir d’un modèle réalisé avec VGAM::vglm(), voir la diapositive 33 sur 35 d’un de ses cours de janvier 2015 intitulé Quelques modèles logistiques polytomiques.
48.3 Affichage des résultats du modèle
Pour un tableau des coefficients, on peut tout simplement appeler gtsummary::tbl_regression(). Nous allons indiquer exponentiate = TRUE car, comme pour la régression logistique binaire, l’exponentielle des coefficients peut s’interpréter comme des odds ratios. Pour éviter certains messages d’information, nous allons préciser tidy_fun = broom.helpers::tidy_parameters (cela implique juste que le tableau des coefficients sera calculé avec le package parameters plutôt qu’avec le package broom). Nous pouvons calculer à la volée la p-valeur globale de chaque variable avec gtsummary::add_global_p().
Réajustement pour obtenir le Hessienℹ Multinomial models, multi-component models and other groups models have a
different underlying structure than the models gtsummary was designed for.
• Functions designed to work with `tbl_regression()` objects may yield
unexpected results.
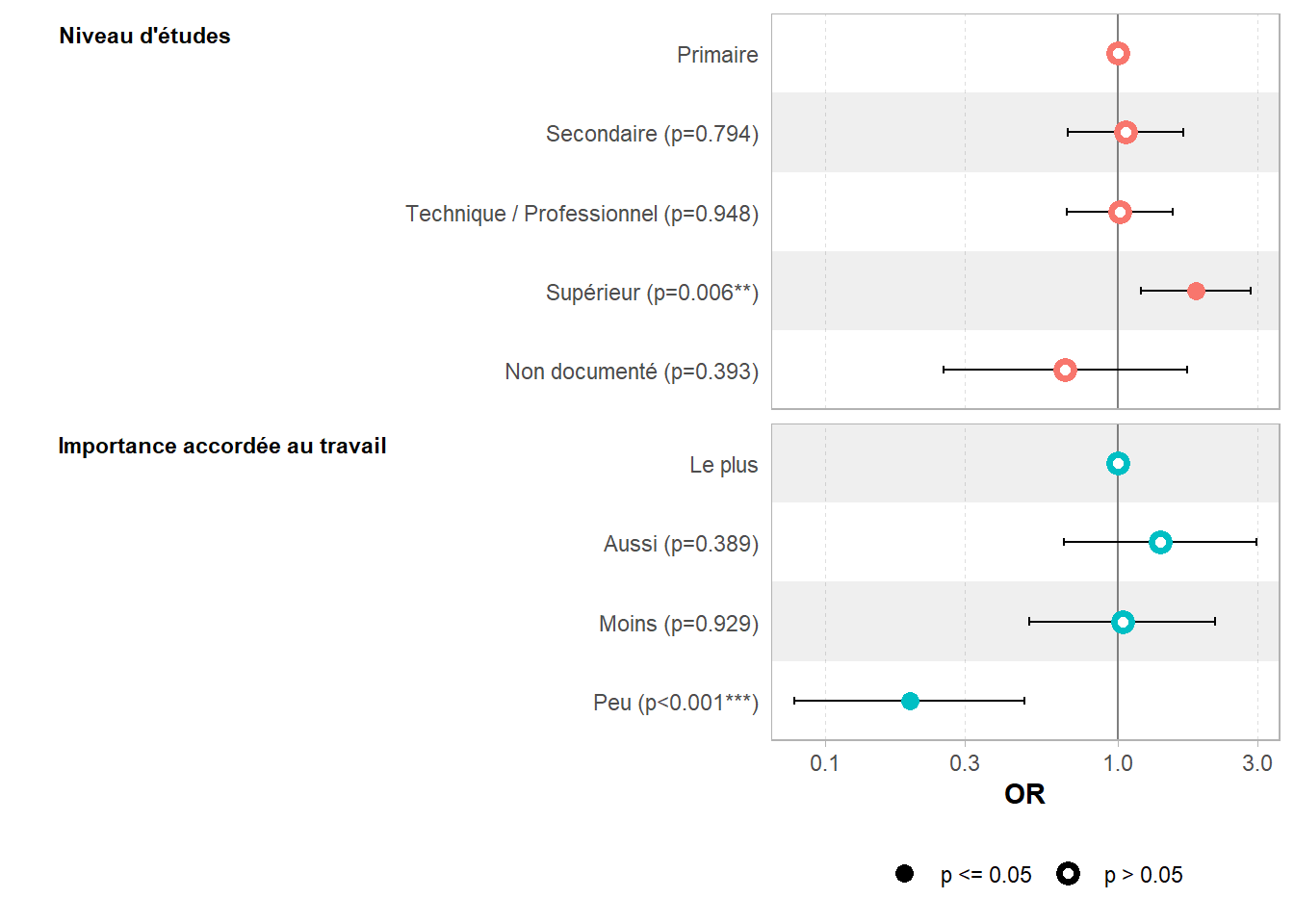
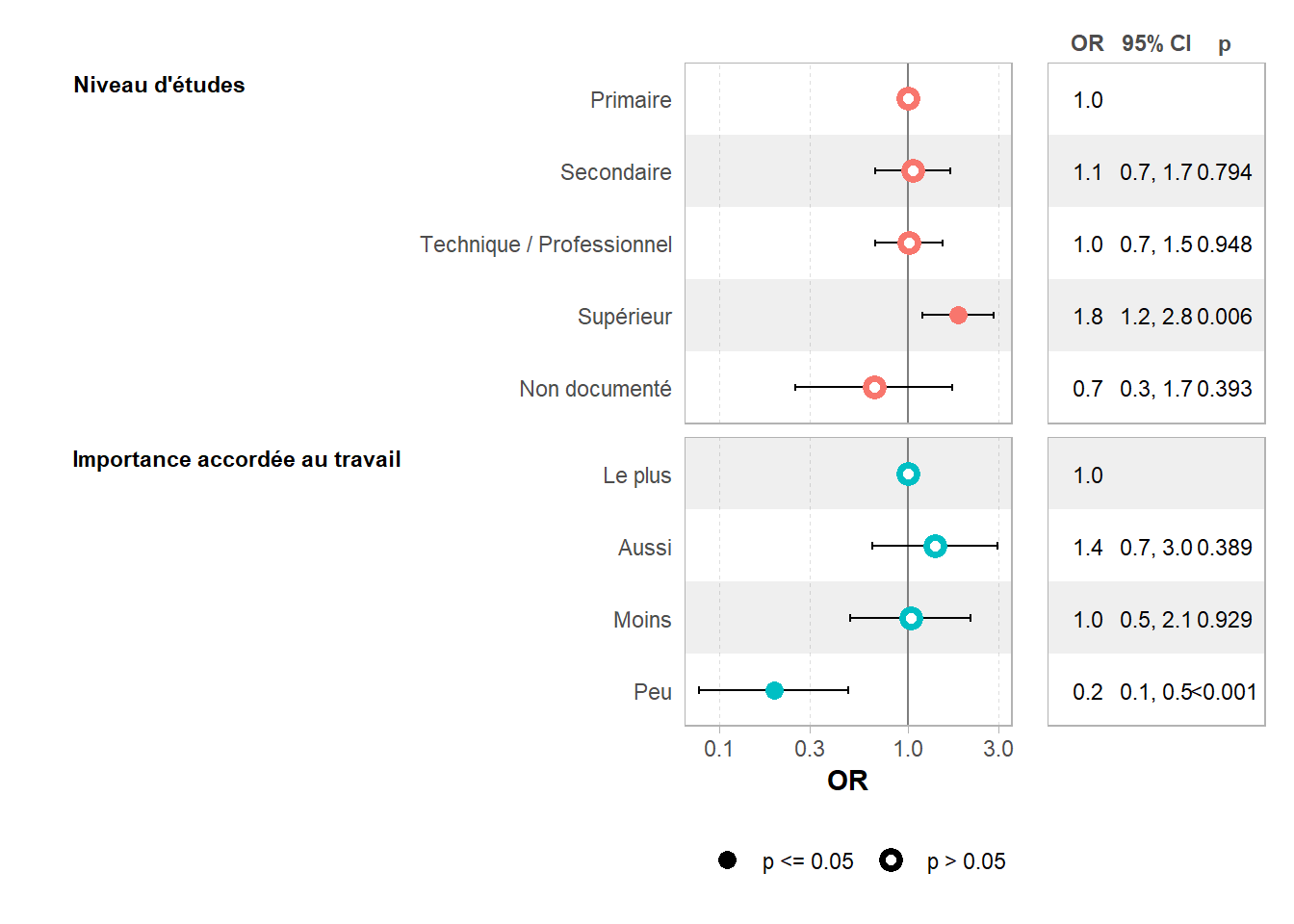
ℹ Suppress this message with `?suppressMessages()`.| Caractéristique | OR | 95% IC | p-valeur |
|---|---|---|---|
| beta | |||
| Niveau d'études | <0,001 | ||
| Primaire | — | — | |
| Secondaire | 1,06 | 0,67 – 1,67 | 0,8 |
| Technique / Professionnel | 1,01 | 0,67 – 1,53 | >0,9 |
| Supérieur | 1,84 | 1,20 – 2,83 | 0,006 |
| Non documenté | 0,66 | 0,25 – 1,72 | 0,4 |
| Importance accordée au travail | <0,001 | ||
| Le plus | — | — | |
| Aussi | 1,39 | 0,65 – 2,97 | 0,4 |
| Moins | 1,03 | 0,50 – 2,14 | >0,9 |
| Peu | 0,19 | 0,08 – 0,48 | <0,001 |
| Abréviations: IC = intervalle de confiance, OR = rapport de cotes | |||
La même commande fonctionne avec un modèle créé avec ordinal::clm().
Pour un graphique des coefficients, on va procéder de même avec ggstats::gcoef_model() ou ggstats::gcoef_table().
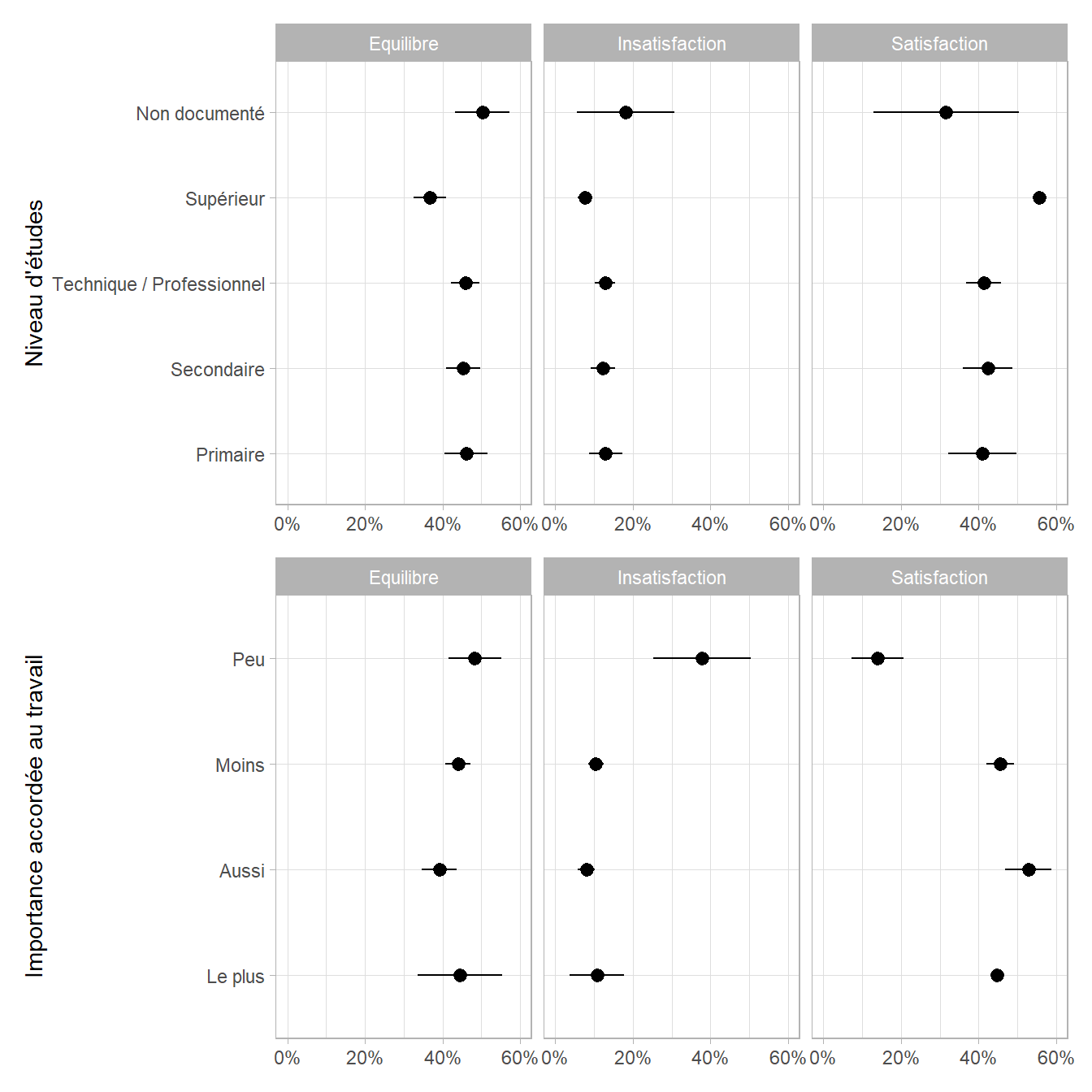
Pour faciliter l’interprétation, on pourra représenter les prédictions marginales du modèle (cf. Chapitre 25) avec broom.helpers::plot_marginal_predictions().
48.4 Données pondérées
48.4.1 avec survey::svyolr()
L’extension survey (cf. Chapitre 30) propose une fonction native survey::svyolr() pour le calcul d’une régression ordinale.
Nous allons commencer par définir le plan d’échantillonnage.
Calculons le modèle.
Le résultat peut être visualisé aisément avec gtsummary::tbl_regression() ou ggstats::ggcoef_model().
48.4.2 avec svrepmisc::svymultinom()
Alternativement, il est possible d’utiliser à ordinal::clm() en ayant recours à des poids de réplication, comme suggéré par Thomas Lumley dans son ouvrage Complex Surveys: A Guide to Analysis Using R.
L’extension svrepmisc disponible sur GitHub fournit quelques fonctions facilitant l’utilisation des poids de réplication avec survey. Pour l’installer, on utilisera le code ci-dessous :
En premier lieu, il faut définir le design de notre tableau de données puis calculer des poids de réplication.
Il faut prévoir un nombre de replicates suffisant pour calculer ultérieurement les intervalles de confiance des coefficients. Plus ce nombre est élevé, plus précise sera l’estimation de la variance et donc des valeurs p et des intervalles de confiance. Cependant, plus ce nombre est élevé, plus le temps de calcul sera important. Pour gagner en temps de calcul, nous avons ici pris une valeur de 25, mais l’usage est de considérer au moins 1000 réplications.
svrepmisc fournit une fonction svrepmisc::svyclm() pour le calcul d’une régression multinomiale avec des poids de réplication.
Warning: (-1) Model failed to converge with max|grad| = 0.000183554 (tol = 1e-06)
In addition: step factor reduced below minimumsvrepmisc fournit également des méthodes svrepmisc::confint() et svrepmisc::tidy(). Nous pouvons donc calculer et afficher les odds ratio et leur intervalle de confiance.
Coefficient SE t value Pr(>|t|)
Insatisfaction|Equilibre -2.03917466 0.49101567 -4.1530 0.00085 ***
Equilibre|Satisfaction 0.27271800 0.46889225 0.5816 0.56946
sexeHomme -0.13280477 0.15913931 -0.8345 0.41708
etudesSecondaire -0.04271403 0.24372887 -0.1753 0.86323
etudesTechnique / Professionnel 0.00042809 0.24169081 0.0018 0.99861
etudesSupérieur 0.64247607 0.24333087 2.6403 0.01855 *
etudesNon documenté -0.46945975 0.46654770 -1.0062 0.33026
trav.impAussi 0.12071087 0.45767404 0.2637 0.79556
trav.impMoins 0.05267146 0.45166794 0.1166 0.90871
trav.impPeu -1.53039056 0.70197414 -2.1801 0.04559 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 2.5 % 97.5 %
Insatisfaction|Equilibre -3.0857498 -0.9925995
Equilibre|Satisfaction -0.7267022 1.2721382
sexeHomme -0.4720022 0.2063926
etudesSecondaire -0.5622098 0.4767818
etudesTechnique / Professionnel -0.5147237 0.5155799
etudesSupérieur 0.1238286 1.1611235
etudesNon documenté -1.4638826 0.5249631
trav.impAussi -0.8547983 1.0962200
trav.impMoins -0.9100360 1.0153789
trav.impPeu -3.0266130 -0.0341681 term estimate std.error statistic p.value
1 Equilibre|Satisfaction 1.3135298 0.4688922 0.58162191 0.5694596402
2 etudesNon documenté 0.6253400 0.4665477 -1.00624171 0.3302565780
3 etudesSecondaire 0.9581854 0.2437289 -0.17525225 0.8632252066
4 etudesSupérieur 1.9011825 0.2433309 2.64033939 0.0185458096
5 etudesTechnique / Professionnel 1.0004282 0.2416908 0.00177121 0.9986101210
6 Insatisfaction|Equilibre 0.1301361 0.4910157 -4.15297269 0.0008499913
7 sexeHomme 0.8756360 0.1591393 -0.83451896 0.4170817838
8 trav.impAussi 1.1282986 0.4576740 0.26374855 0.7955626435
9 trav.impMoins 1.0540833 0.4516679 0.11661545 0.9087118117
10 trav.impPeu 0.2164511 0.7019741 -2.18012385 0.0455903197
conf.low conf.high
1 0.48350087 3.568474
2 0.23133633 1.690397
3 0.56994819 1.610882
4 1.13182187 3.193519
5 0.59766572 1.674609
6 0.04569576 0.370612
7 0.62375216 1.229236
8 0.42536899 2.992832
9 0.40250975 2.760409
10 0.04847956 0.966409Par contre, le support de gtsummary::tbl_regression() et ggstats::ggcoef_model() est plus limité. Vous pourrez afficher un tableau basique des résultats et un graphiques des coefficients, mais sans les enrichissements usuels (identification des variables, étiquettes propres, identification des niveaux, etc.).
48.4.3 avec svyVGAM::svy_glm()
Une alternative possible pour le calcul de la régression logistique multinomiale avec des données pondérées est svyVGAM::svy_vglm() avec family = VGAM::multinomial.
Nous allons commencer par définir le plan d’échantillonnage.
Puis, on appelle svyVGAM::svy_vglm() en précisant family = VGAM::cumulative(parallel = TRUE).
svy_vglm.survey.design(trav.satisf ~ sexe + etudes + trav.imp,
family = VGAM::cumulative(parallel = TRUE), design = dw)
Independent Sampling design (with replacement)
Called via srvyr
Sampling variables:
- ids: `1`
- weights: poids
Data variables:
- id (int), age (int), sexe (fct), nivetud (fct), poids (dbl), occup (fct),
qualif (fct), freres.soeurs (int), clso (fct), relig (fct), trav.imp (fct),
trav.satisf (ord), hard.rock (fct), lecture.bd (fct), peche.chasse (fct),
cuisine (fct), bricol (fct), cinema (fct), sport (fct), heures.tv (dbl),
groupe_ages (fct), etudes (fct)
Coef SE z p
(Intercept):1 -2.03917232 0.52467564 -3.8865 0.0001017
(Intercept):2 0.27272042 0.51315926 0.5315 0.5951044
sexeHomme 0.13280416 0.15421876 0.8611 0.3891602
etudesSecondaire 0.04271296 0.28498254 0.1499 0.8808599
etudesTechnique / Professionnel -0.00043004 0.25720348 -0.0017 0.9986659
etudesSupérieur -0.64247750 0.26590126 -2.4162 0.0156823
etudesNon documenté 0.46945812 0.52541495 0.8935 0.3715896
trav.impAussi -0.12071140 0.48525530 -0.2488 0.8035476
trav.impMoins -0.05267211 0.47029563 -0.1120 0.9108251
trav.impPeu 1.53036737 0.65156164 2.3488 0.0188356Cette fois-ci, gtsummary::tbl_regression() et ggstats::ggcoef_model() sont compatibles avec svyVGAM::svy_vglm().
ℹ <svy_vglm> model detected.✔ `tidy_svy_vglm()` used instead.ℹ Add `tidy_fun = broom.helpers::tidy_svy_vglm` to quiet these messages.ℹ Multinomial models, multi-component models and other groups models have a
different underlying structure than the models gtsummary was designed for.
• Functions designed to work with `tbl_regression()` objects may yield
unexpected results.
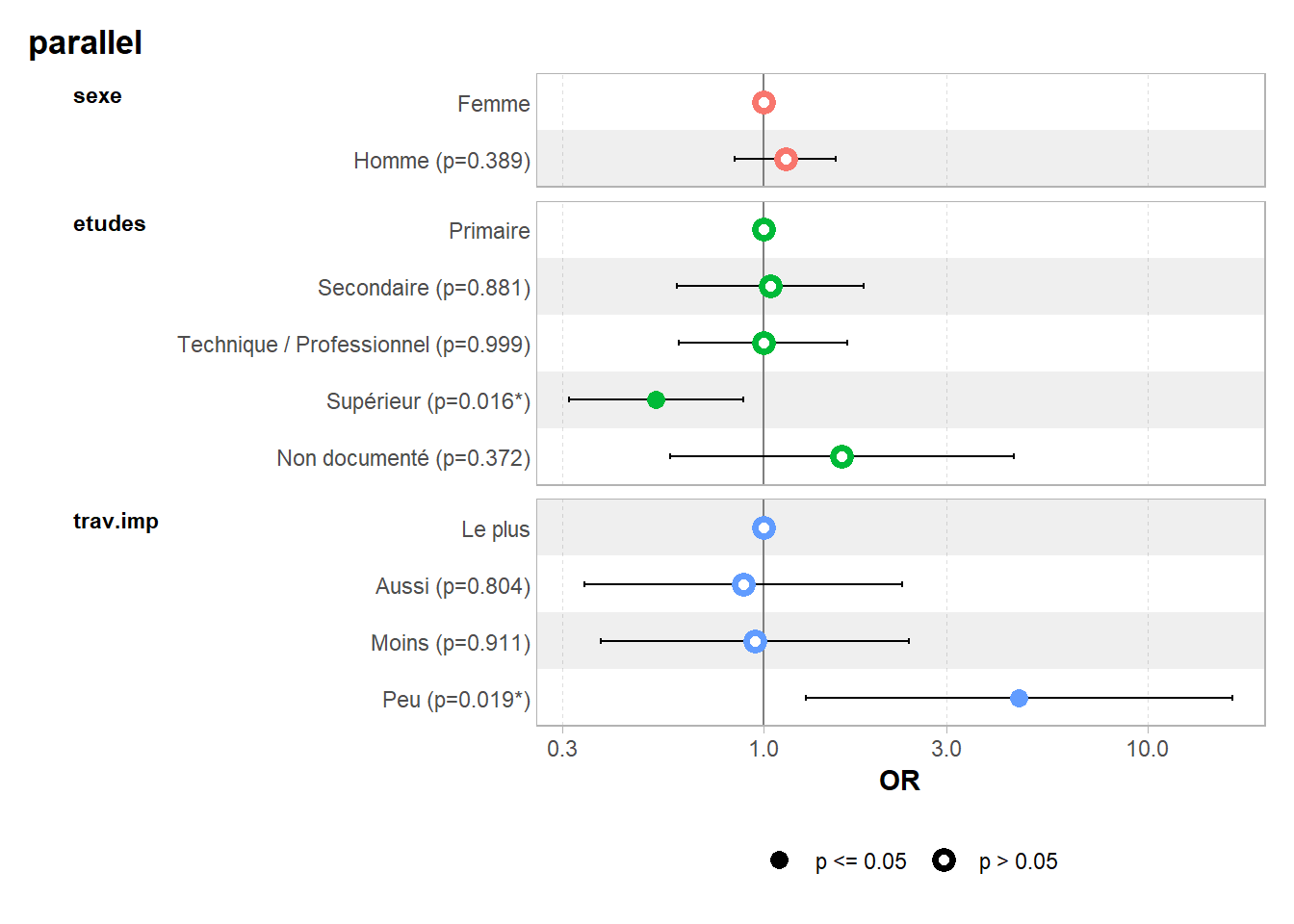
ℹ Suppress this message with `?suppressMessages()`.| Caractéristique | OR | 95% IC | p-valeur |
|---|---|---|---|
| parallel | |||
| sexe | |||
| Femme | — | — | |
| Homme | 1,14 | 0,84 – 1,55 | 0,4 |
| etudes | |||
| Primaire | — | — | |
| Secondaire | 1,04 | 0,60 – 1,82 | 0,9 |
| Technique / Professionnel | 1,00 | 0,60 – 1,65 | >0,9 |
| Supérieur | 0,53 | 0,31 – 0,89 | 0,016 |
| Non documenté | 1,60 | 0,57 – 4,48 | 0,4 |
| trav.imp | |||
| Le plus | — | — | |
| Aussi | 0,89 | 0,34 – 2,29 | 0,8 |
| Moins | 0,95 | 0,38 – 2,38 | >0,9 |
| Peu | 4,62 | 1,29 – 16,6 | 0,019 |
| Abréviations: IC = intervalle de confiance, OR = rapport de cotes | |||