[1] nord sud sud est est est
Levels: est nord sud9 Facteurs et forcats
Dans R, les facteurs sont utilisés pour représenter des variables catégorielles, c’est-à-dire des variables qui ont un nombre fixé et limité de valeurs possibles (par exemple une variable sexe ou une variable niveau d’éducation).
De telles variables sont parfois représentées sous forme textuelle (vecteurs de type character). Cependant, cela ne permets pas d’indiquer un ordre spécifique aux modalités, à la différence des facteurs.
Note
Lorsque l’on importe des données d’enquêtes, il est fréquent que les variables catégorielles sont codées sous la forme d’un code numérique (par exemple 1 pour femme et 2 pour homme) auquel est associé une étiquette de valeur. C’est notamment le fonctionnement usuel de logiciels tels que SPSS, Stata ou SAS. Les étiquettes de valeurs seront abordés dans un prochain chapitre (voir Chapitre 12).
Au moment de l’analyse (tableaux statistiques, graphiques, modèles de régression…), il sera nécessaire de transformer ces vecteurs avec étiquettes en facteurs.
9.1 Création d’un facteur
Le plus simple pour créer un facteur est de partir d’un vecteur textuel et d’utiliser la fonction factor().
Par défaut, les niveaux du facteur obtenu correspondent aux valeurs uniques du facteur textuel, triés par ordre alphabétique. Si l’on veut contrôler l’ordre des niveaux, et éventuellement indiquer un niveau absent des données, on utilisera l’argument levels de factor().
[1] nord sud sud est est est
Levels: nord est sud ouestSi une valeur observée dans les données n’est pas indiqué dans levels, elle sera silencieusement convertie en valeur manquante (NA).
Si l’on veut être averti par un warning dans ce genre de situation, on pourra avoir plutôt recours à la fonction readr::parse_factor() du package readr, qui, le cas échéant, renverra un tableau avec les problèmes rencontrés.
Warning: 3 parsing failures.
row col expected actual
4 -- value in level set est
5 -- value in level set est
6 -- value in level set est[1] nord sud sud <NA> <NA> <NA>
attr(,"problems")
# A tibble: 3 × 4
row col expected actual
<int> <int> <chr> <chr>
1 4 NA value in level set est
2 5 NA value in level set est
3 6 NA value in level set est
Levels: nord sudUne fois un facteur créé, on peut accéder à la liste de ses étiquettes avec levels().
Dans certaines situations (par exemple pour la réalisation d’une régression logistique ordinale), on peut avoir avoir besoin d’indiquer que les modalités du facteur sont ordonnées hiérarchiquement. Dans ce cas là, on aura simplement recours à ordered() pour créer/convertir notre facteur.
[1] supérieur primaire secondaire primaire supérieur
Levels: primaire < secondaire < supérieurTechniquement, les valeurs d’un facteur sont stockés de manière interne à l’aide de nombres entiers, dont la valeur représente la position de l’étiquette correspondante dans l’attribut levels. Ainsi, un facteur à n modalités sera toujours codé avec les nombre entiers allant de 1 à n.
9.2 Changer l’ordre des modalités
Le package forcats, chargé par défaut lorsque l’on exécute la commande library(tidyverse), fournie plusieurs fonctions pour manipuler des facteurs. Pour donner des exemples d’utilisation de ces différentes fonctions, nous allons utiliser le jeu de données hdv2003 du package questionr.
Considérons la variable qualif qui indique le niveau de qualification des enquêtés. On peut voir la liste des niveaux de ce facteur, et leur ordre, avec levels(), ou en effectuant un tri à plat avec la fonction questionr::freq().
[1] "Ouvrier specialise" "Ouvrier qualifie"
[3] "Technicien" "Profession intermediaire"
[5] "Cadre" "Employe"
[7] "Autre" # A tibble: 8 × 4
qualif n N prop
<fct> <int> <int> <dbl>
1 Ouvrier specialise 203 2000 10.2
2 Ouvrier qualifie 292 2000 14.6
3 Technicien 86 2000 4.3
4 Profession intermediaire 160 2000 8
5 Cadre 260 2000 13
6 Employe 594 2000 29.7
7 Autre 58 2000 2.9
8 <NA> 347 2000 17.3Parfois, on a simplement besoin d’inverser l’ordre des facteurs, ce qui peut se faire facilement avec la fonction forcats::fct_rev(). Elle renvoie le facteur fourni en entrée en ayant inverser l’ordre des modalités (mais sans modifier l’ordre des valeurs dans le vecteur).
# A tibble: 8 × 4
`fct_rev(qualif)` n N prop
<fct> <int> <int> <dbl>
1 Autre 58 2000 2.9
2 Employe 594 2000 29.7
3 Cadre 260 2000 13
4 Profession intermediaire 160 2000 8
5 Technicien 86 2000 4.3
6 Ouvrier qualifie 292 2000 14.6
7 Ouvrier specialise 203 2000 10.2
8 <NA> 347 2000 17.3Pour plus de contrôle, on utilisera forcats::fct_relevel() où l’on indique l’ordre souhaité des modalités. On peut également seulement indiquer les premières modalités, les autres seront ajoutées à la fin sans changer leur ordre.
# A tibble: 8 × 4
fct_relevel(qualif, "Cadre", "Autre", "Technicien", "Emplo…¹ n N prop
<fct> <int> <int> <dbl>
1 Cadre 260 2000 13
2 Autre 58 2000 2.9
3 Technicien 86 2000 4.3
4 Employe 594 2000 29.7
5 Ouvrier specialise 203 2000 10.2
6 Ouvrier qualifie 292 2000 14.6
7 Profession intermediaire 160 2000 8
8 <NA> 347 2000 17.3
# ℹ abbreviated name:
# ¹`fct_relevel(qualif, "Cadre", "Autre", "Technicien", "Employe")`La fonction forcats::fct_infreq() ordonne les modalités de celle la plus fréquente à celle la moins fréquente (nombre d’observations) :
# A tibble: 8 × 4
`fct_infreq(qualif)` n N prop
<fct> <int> <int> <dbl>
1 Employe 594 2000 29.7
2 Ouvrier qualifie 292 2000 14.6
3 Cadre 260 2000 13
4 Ouvrier specialise 203 2000 10.2
5 Profession intermediaire 160 2000 8
6 Technicien 86 2000 4.3
7 Autre 58 2000 2.9
8 <NA> 347 2000 17.3Pour inverser l’ordre, on combinera forcats::fct_infreq() avec forcats::fct_rev().
# A tibble: 8 × 4
`fct_rev(fct_infreq(qualif))` n N prop
<fct> <int> <int> <dbl>
1 Autre 58 2000 2.9
2 Technicien 86 2000 4.3
3 Profession intermediaire 160 2000 8
4 Ouvrier specialise 203 2000 10.2
5 Cadre 260 2000 13
6 Ouvrier qualifie 292 2000 14.6
7 Employe 594 2000 29.7
8 <NA> 347 2000 17.3Dans certains cas, on souhaite créer un facteur dont les modalités sont triées selon leur ordre d’apparition dans le jeu de données. Pour cela, on aura recours à forcats::fct_inorder().
[1] c a d b a c
Levels: a b c d[1] c a d b a c
Levels: c a d bLa fonction forcats::fct_reorder() permets de trier les modalités en fonction d’une autre variable. Par exemple, si je souhaite trier les modalités de la variable qualif en fonction de l’âge moyen (dans chaque modalité) :
# A tibble: 8 × 2
qualif_tri_age age_moyen
<fct> <dbl>
1 Technicien 45.9
2 Employe 46.7
3 Autre 47.0
4 Ouvrier specialise 48.9
5 Profession intermediaire 49.1
6 Cadre 49.7
7 Ouvrier qualifie 50.0
8 <NA> 47.9
Astuce
questionr propose une interface graphique afin de faciliter les opérations de ré-ordonnancement manuel. Pour la lancer, sélectionner le menu Addins puis Levels ordering, ou exécuter la fonction questionr::iorder() en lui passant comme paramètre le facteur à réordonner.
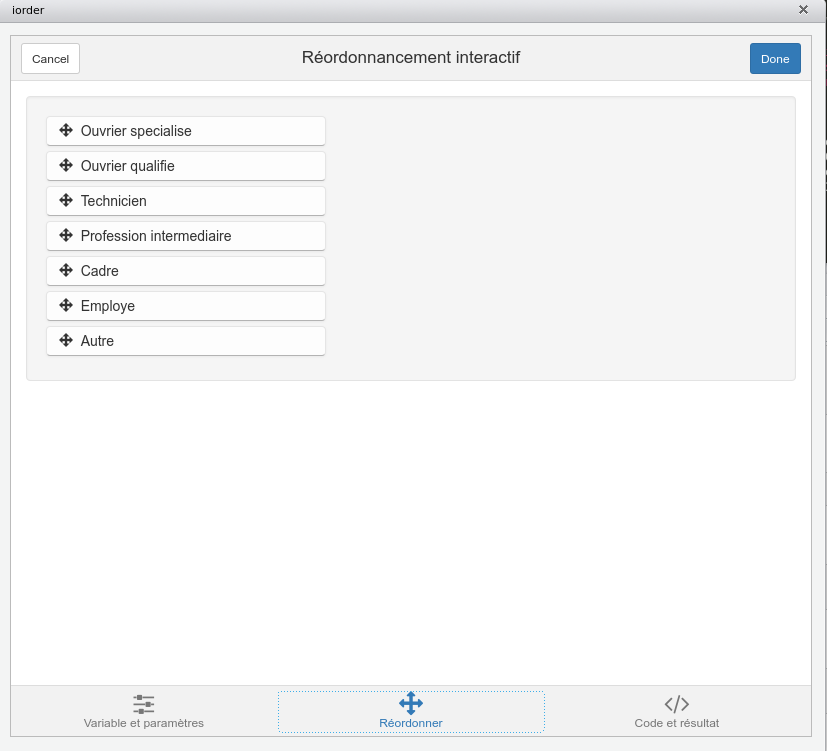
Une démonstration en vidéo de cet add-in est disponible dans le webin-R #05 (recoder des variables) sur [YouTube](https://youtu.be/CokvTbtWdwc?t=3934).
9.3 Modifier les modalités
Pour modifier le nom des modalités, on pourra avoir recours à forcats::fct_recode() avec une syntaxe de la forme "nouveau nom" = "ancien nom".
# A tibble: 2 × 4
sexe n N prop
<fct> <int> <int> <dbl>
1 Homme 899 2000 45.0
2 Femme 1101 2000 55.0# A tibble: 2 × 4
sexe n N prop
<fct> <int> <int> <dbl>
1 m 899 2000 45.0
2 f 1101 2000 55.0On peut également fusionner des modalités ensemble en leur attribuant le même nom.
# A tibble: 9 × 4
nivetud n N prop
<fct> <int> <int> <dbl>
1 N'a jamais fait d'etudes 39 2000 1.95
2 A arrete ses etudes, avant la derniere annee d'etudes prima… 86 2000 4.3
3 Derniere annee d'etudes primaires 341 2000 17.0
4 1er cycle 204 2000 10.2
5 2eme cycle 183 2000 9.15
6 Enseignement technique ou professionnel court 463 2000 23.2
7 Enseignement technique ou professionnel long 131 2000 6.55
8 Enseignement superieur y compris technique superieur 441 2000 22.0
9 <NA> 112 2000 5.6 hdv2003$instruction <-
hdv2003$nivetud |>
fct_recode(
"primaire" = "N'a jamais fait d'etudes",
"primaire" = "A arrete ses etudes, avant la derniere annee d'etudes primaires",
"primaire" = "Derniere annee d'etudes primaires",
"secondaire" = "1er cycle",
"secondaire" = "2eme cycle",
"technique/professionnel" = "Enseignement technique ou professionnel court",
"technique/professionnel" = "Enseignement technique ou professionnel long",
"supérieur" = "Enseignement superieur y compris technique superieur"
)
hdv2003 |> guideR::proportion(instruction)# A tibble: 5 × 4
instruction n N prop
<fct> <int> <int> <dbl>
1 primaire 466 2000 23.3
2 secondaire 387 2000 19.4
3 technique/professionnel 594 2000 29.7
4 supérieur 441 2000 22.0
5 <NA> 112 2000 5.6
AstuceInterface graphique
Le packagequestionr propose une interface graphique facilitant le recodage des modalités d’une variable qualitative. L’objectif est de permettre à la personne qui l’utilise de saisir les nouvelles valeurs dans un formulaire, et de générer ensuite le code R correspondant au recodage indiqué.
Pour utiliser cette interface, sous RStudio vous pouvez aller dans le menu Addins (présent dans la barre d’outils principale) puis choisir Levels recoding. Sinon, vous pouvez lancer dans la console la fonction questionr::irec() en lui passant comme paramètre la variable à recoder.
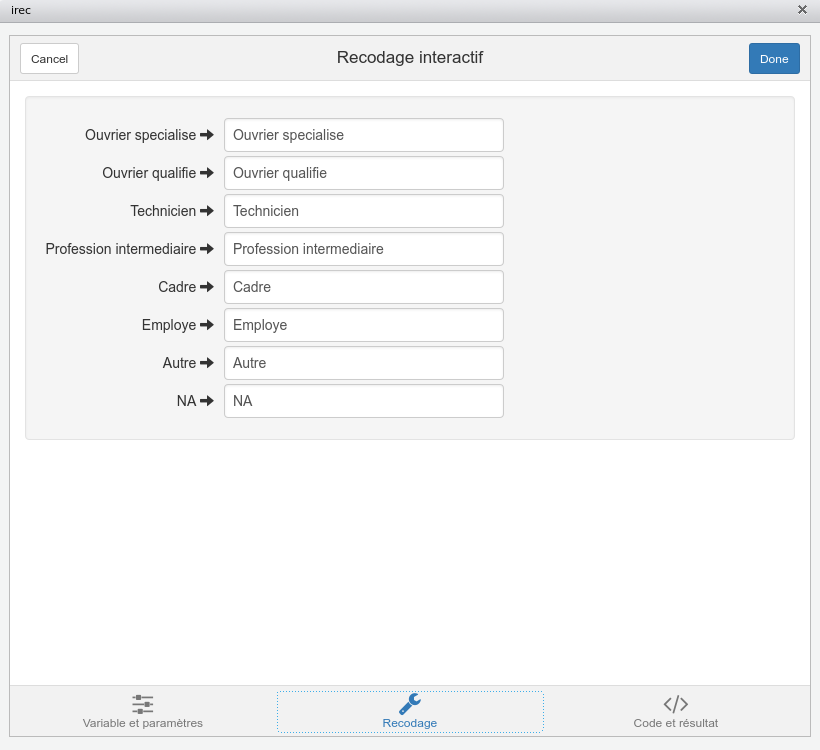
Une démonstration en vidéo de cet add-in est disponible dans le webin-R #05 (recoder des variables) sur [YouTube](https://youtu.be/CokvTbtWdwc?t=3387).
La fonction forcats::fct_collapse() est une variante de forcats::fct_recode() pour indiquer les fusions de modalités. La même recodification s’écrirait alors :
hdv2003$instruction <-
hdv2003$nivetud |>
fct_collapse(
"primaire" = c(
"N'a jamais fait d'etudes",
"A arrete ses etudes, avant la derniere annee d'etudes primaires",
"Derniere annee d'etudes primaires"
),
"secondaire" = c(
"1er cycle",
"2eme cycle"
),
"technique/professionnel" = c(
"Enseignement technique ou professionnel court",
"Enseignement technique ou professionnel long"
),
"supérieur" = "Enseignement superieur y compris technique superieur"
)Pour transformer les valeurs manquantes (NA) en une modalité explicite, on pourra avoir recours à forcats::fct_na_value_to_level()1.
1 Cette fonction s’appelait précédemment forcats::fct_explicit_na() et a été renommée depuis la version 1.0.0 de {forcats}.
# A tibble: 5 × 4
instruction n N prop
<fct> <int> <int> <dbl>
1 primaire 466 2000 23.3
2 secondaire 387 2000 19.4
3 technique/professionnel 594 2000 29.7
4 supérieur 441 2000 22.0
5 (manquant) 112 2000 5.6Plusieurs fonctions permettent de regrouper plusieurs modalités dans une modalité autres.
Par exemple, avec forcats::fct_other(), on pourra indiquer les modalités à garder.
# A tibble: 8 × 4
qualif n N prop
<fct> <int> <int> <dbl>
1 Ouvrier specialise 203 2000 10.2
2 Ouvrier qualifie 292 2000 14.6
3 Technicien 86 2000 4.3
4 Profession intermediaire 160 2000 8
5 Cadre 260 2000 13
6 Employe 594 2000 29.7
7 Autre 58 2000 2.9
8 <NA> 347 2000 17.3# A tibble: 5 × 4
fct_other(qualif, keep = c("Technicien", "Cadre", "Employe…¹ n N prop
<fct> <int> <int> <dbl>
1 Technicien 86 2000 4.3
2 Cadre 260 2000 13
3 Employe 594 2000 29.7
4 Other 713 2000 35.6
5 <NA> 347 2000 17.3
# ℹ abbreviated name:
# ¹`fct_other(qualif, keep = c("Technicien", "Cadre", "Employe"))`La fonction forcats::fct_lump_n() permets de ne conserver que les modalités les plus fréquentes et de regrouper les autres dans une modalité autres.
# A tibble: 6 × 4
`fct_lump_n(qualif, n = 4, other_level = "Autres")` n N prop
<fct> <int> <int> <dbl>
1 Ouvrier specialise 203 2000 10.2
2 Ouvrier qualifie 292 2000 14.6
3 Cadre 260 2000 13
4 Employe 594 2000 29.7
5 Autres 304 2000 15.2
6 <NA> 347 2000 17.3Et forcats::fct_lump_min() celles qui ont un minimum d’observations.
# A tibble: 6 × 4
`fct_lump_min(qualif, min = 200, other_level = "Autres")` n N prop
<fct> <int> <int> <dbl>
1 Ouvrier specialise 203 2000 10.2
2 Ouvrier qualifie 292 2000 14.6
3 Cadre 260 2000 13
4 Employe 594 2000 29.7
5 Autres 304 2000 15.2
6 <NA> 347 2000 17.3Il peut arriver qu’une des modalités d’un facteur ne soit pas représentée dans les données.
n % val%
a 3 75 75
b 1 25 25
c 0 0 0Pour calculer certains tests statistiques ou faire tourner un modèle, ces modalités sans observation peuvent être problématiques. forcats::fct_drop() permet de supprimer les modalités qui n’apparaissent pas dans les données.
À l’inverse, forcats::fct_expand() permet d’ajouter une ou plusieurs modalités à un facteur.
9.4 Découper une variable numérique en classes
Il est fréquent d’avoir besoin de découper une variable numérique en une variable catégorielles (un facteur) à plusieurs modalités, par exemple pour créer des groupes d’âges à partir d’une variable age.
On utilise pour cela la fonction cut() qui prend, outre la variable à découper, un certain nombre d’arguments :
-
breaksindique soit le nombre de classes souhaité, soit, si on lui fournit un vecteur, les limites des classes ; -
labelspermet de modifier les noms de modalités attribués aux classes ; -
include.lowestetrightinfluent sur la manière dont les valeurs situées à la frontière des classes seront inclues ou exclues ; -
dig.labindique le nombre de chiffres après la virgule à conserver dans les noms de modalités.
Prenons tout de suite un exemple et tentons de découper la variable age en cinq classes :
# A tibble: 5 × 4
groupe_ages n N prop
<fct> <int> <int> <dbl>
1 (17.9,33.8] 454 2000 22.7
2 (33.8,49.6] 628 2000 31.4
3 (49.6,65.4] 556 2000 27.8
4 (65.4,81.2] 319 2000 16.0
5 (81.2,97.1] 43 2000 2.15Par défaut R nous a bien créé cinq classes d’amplitudes égales. La première classe va de 17,9 à 33,8 ans (en fait de 17 à 32), etc.
Les frontières de classe seraient plus présentables si elles utilisaient des nombres ronds. On va donc spécifier manuellement le découpage souhaité, par tranches de 20 ans :
# A tibble: 6 × 4
groupe_ages n N prop
<fct> <int> <int> <dbl>
1 (18,20] 55 2000 2.75
2 (20,40] 660 2000 33
3 (40,60] 780 2000 39
4 (60,80] 436 2000 21.8
5 (80,97] 52 2000 2.6
6 <NA> 17 2000 0.85Les symboles dans les noms attribués aux classes ont leur importance : ( signifie que la frontière de la classe est exclue, tandis que [ signifie qu’elle est incluse. Ainsi, (20,40] signifie « strictement supérieur à 20 et inférieur ou égal à 40 ».
On remarque que du coup, dans notre exemple précédent, la valeur minimale, 18, est exclue de notre première classe, et qu’une observation est donc absente de ce découpage. Pour résoudre ce problème on peut soit faire commencer la première classe à 17, soit utiliser l’option include.lowest=TRUE :
# A tibble: 5 × 4
groupe_ages n N prop
<fct> <int> <int> <dbl>
1 [18,20] 72 2000 3.6
2 (20,40] 660 2000 33
3 (40,60] 780 2000 39
4 (60,80] 436 2000 21.8
5 (80,97] 52 2000 2.6On peut également modifier le sens des intervalles avec l’option right=FALSE :
# A tibble: 5 × 4
groupe_ages n N prop
<fct> <int> <int> <dbl>
1 [18,20) 48 2000 2.4
2 [20,40) 643 2000 32.2
3 [40,60) 793 2000 39.6
4 [60,80) 454 2000 22.7
5 [80,97] 62 2000 3.1
AstuceInterface graphique
Il n’est pas nécessaire de connaître toutes les options de cut(). Le package questionr propose là encore une interface graphique permettant de visualiser l’effet des différents paramètres et de générer le code R correspondant.
Pour utiliser cette interface, sous RStudio vous pouvez aller dans le menu Addins (présent dans la barre d’outils principale) puis choisir Numeric range dividing. Sinon, vous pouvez lancer dans la console la fonction questionr::icut() en lui passant comme paramètre la variable numérique à découper.
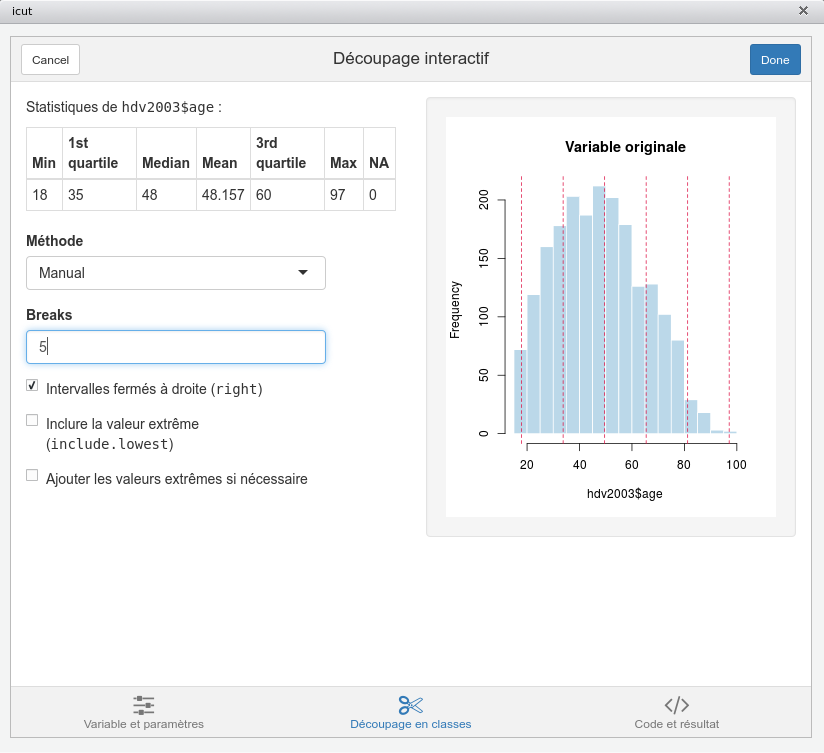 Une démonstration en vidéo de cet add-in est disponible dans le webin-R #05 (recoder des variables) sur [YouTube](https://youtu.be/CokvTbtWdwc?t=2795).
Une démonstration en vidéo de cet add-in est disponible dans le webin-R #05 (recoder des variables) sur [YouTube](https://youtu.be/CokvTbtWdwc?t=2795).