18 Statistique univariée & Intervalles de confiance
On entend par statistique univariée l’étude d’une seule variable, que celle-ci soit continue (quantitative) ou catégorielle (qualitative). La statistique univariée fait partie de la statistique descriptive.
18.1 Exploration graphique
Une première approche consiste à explorer visuelle la variable d’intérêt, notamment à l’aide de l’interface proposée par esquisse (cf Section 17.4).
Nous indiquons ci-après le code correspond aux graphiques ggplot2 les plus courants.
18.1.1 Variable continue
Un histogramme est la représentation graphique la plus commune pour représenter la distribution d’une variable, par exemple ici la longueur des pétales (variable Petal.Length) du fichier de données datasets::iris. Il s’obtient avec la géométrie ggplot2::geom_histogram().
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.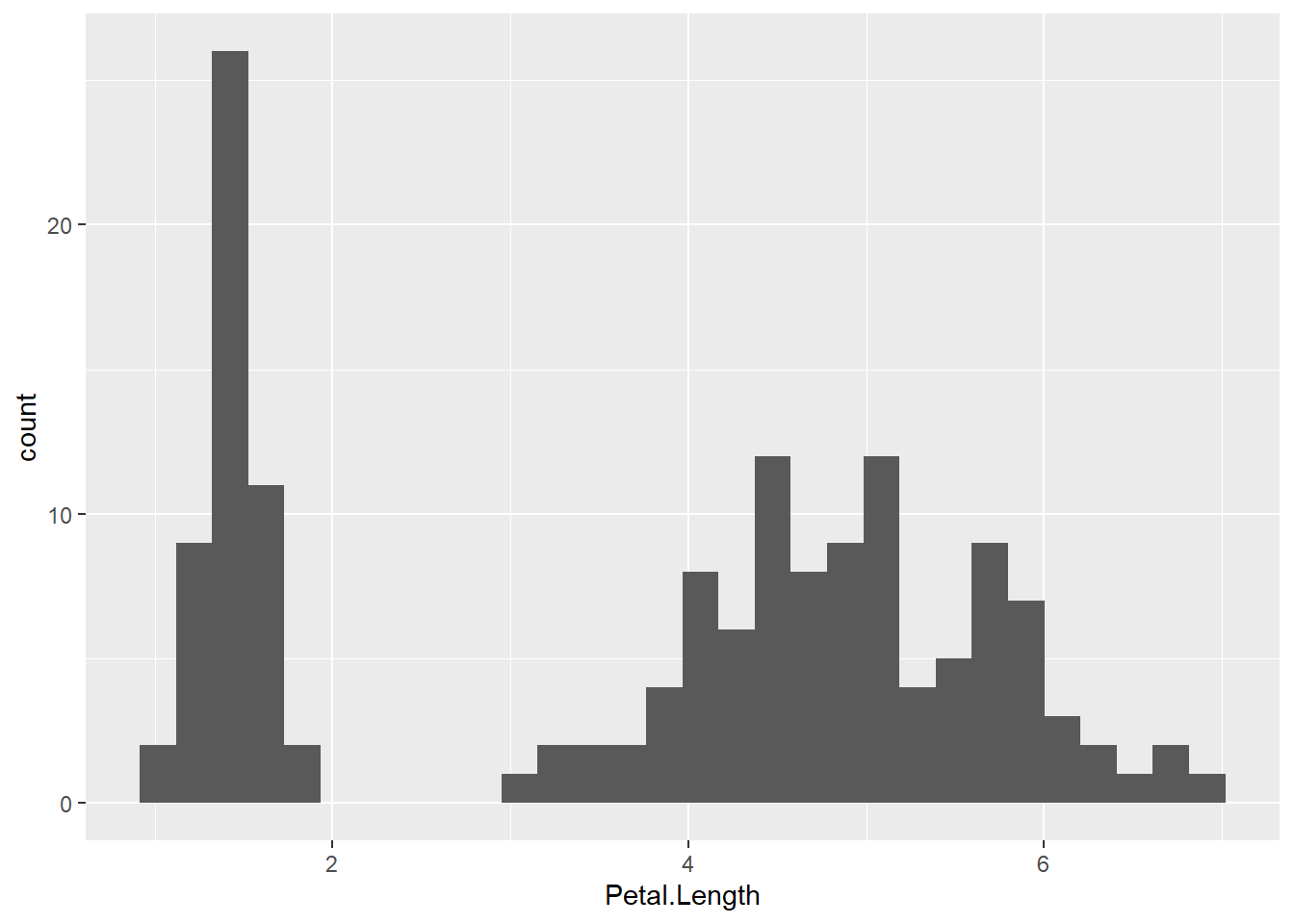
Il faut noter qu’il nous a suffit d’associer simplement la variable Petal.Length à l’esthétique x, sans avoir eu besoin d’indiquer une variable pour l’esthétique y.
En fait, ggplot2 associe par défaut à toute géométrie une certaine statistique. Dans le cas de ggplot2::geom_histogram(), il s’agit de la statistique ggplot2::stat_bin() qui divise la variable continue en classes de même largeur et compte le nombre d’observation dans chacune. ggplot2::stat_bin() renvoie un certain nombre de variables calculées (la liste complète est indiquée dans la documentation dans la section Compute variables), dont la variable count qui correspond au nombre d’observations la classe. On peut associer cette variable calculée à une esthétique grâce à la fonction ggplot2::after_stat(), par exemple aes(y = after_stat(count)). Dans le cas présent, ce n’est pas nécessaire car ggplot2 fait cette association automatiquement si l’on n’a pas déjà attribué une variable à l’esthétique y.
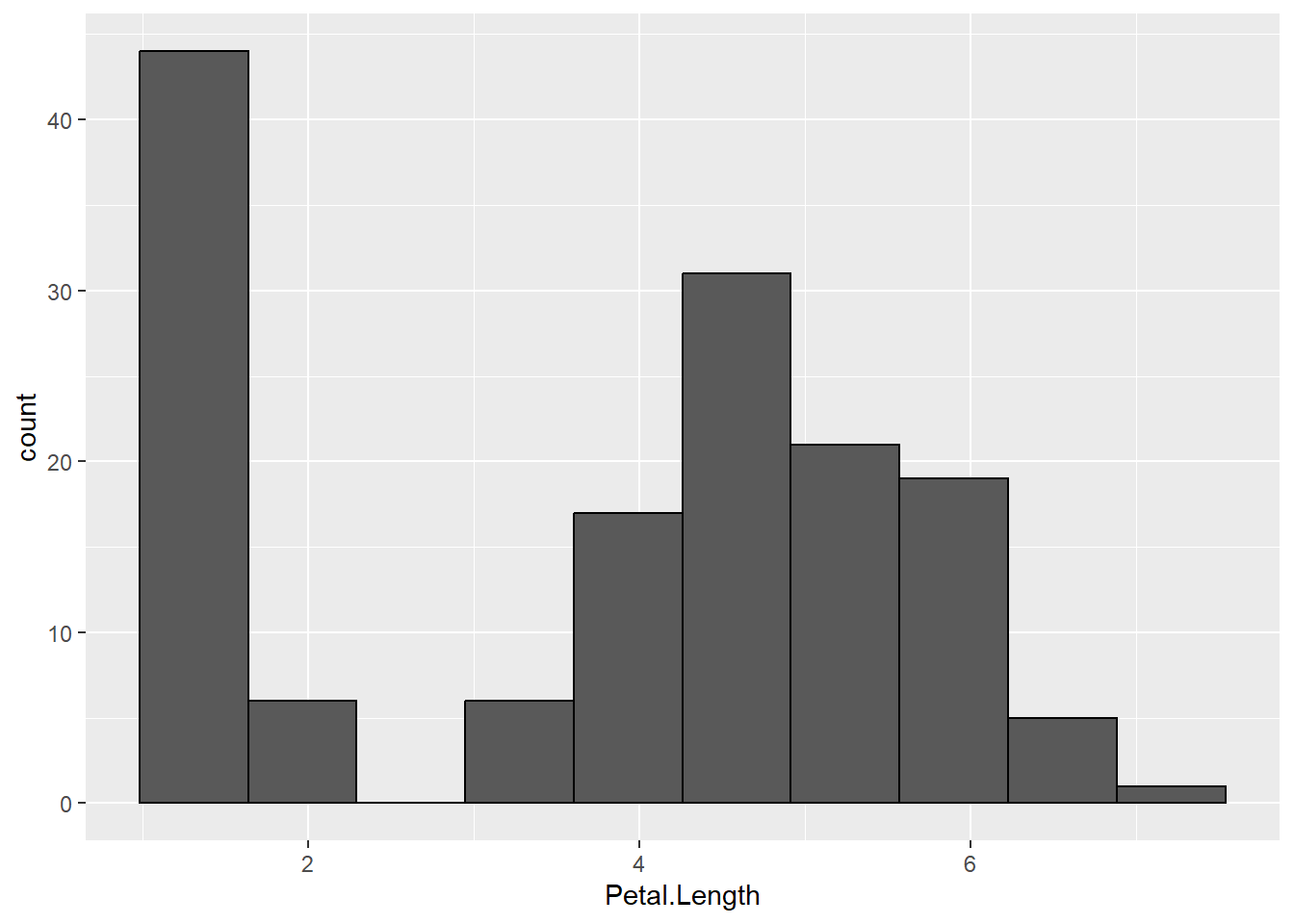
On peut personnaliser la couleur de remplissage des rectangles en indiquant une valeur fixe pour l’esthétique fill dans l’appel de ggplot2::geom_histogram() (et non via la fonction ggplot2::aes() puisqu’il ne s’agit pas d’une variable du tableau de données). L’esthétique colour permet de spécifier la couleur du trait des rectangles. Enfin, le paramètre binwidth permet de spécifier la largeur des barres.

À noter, les dernières versions de ggplot2 prennent en compte les étiquettes de variables (voir Chapitre 11).
On peut alternativement indiquer un nombre de classes avec bins.
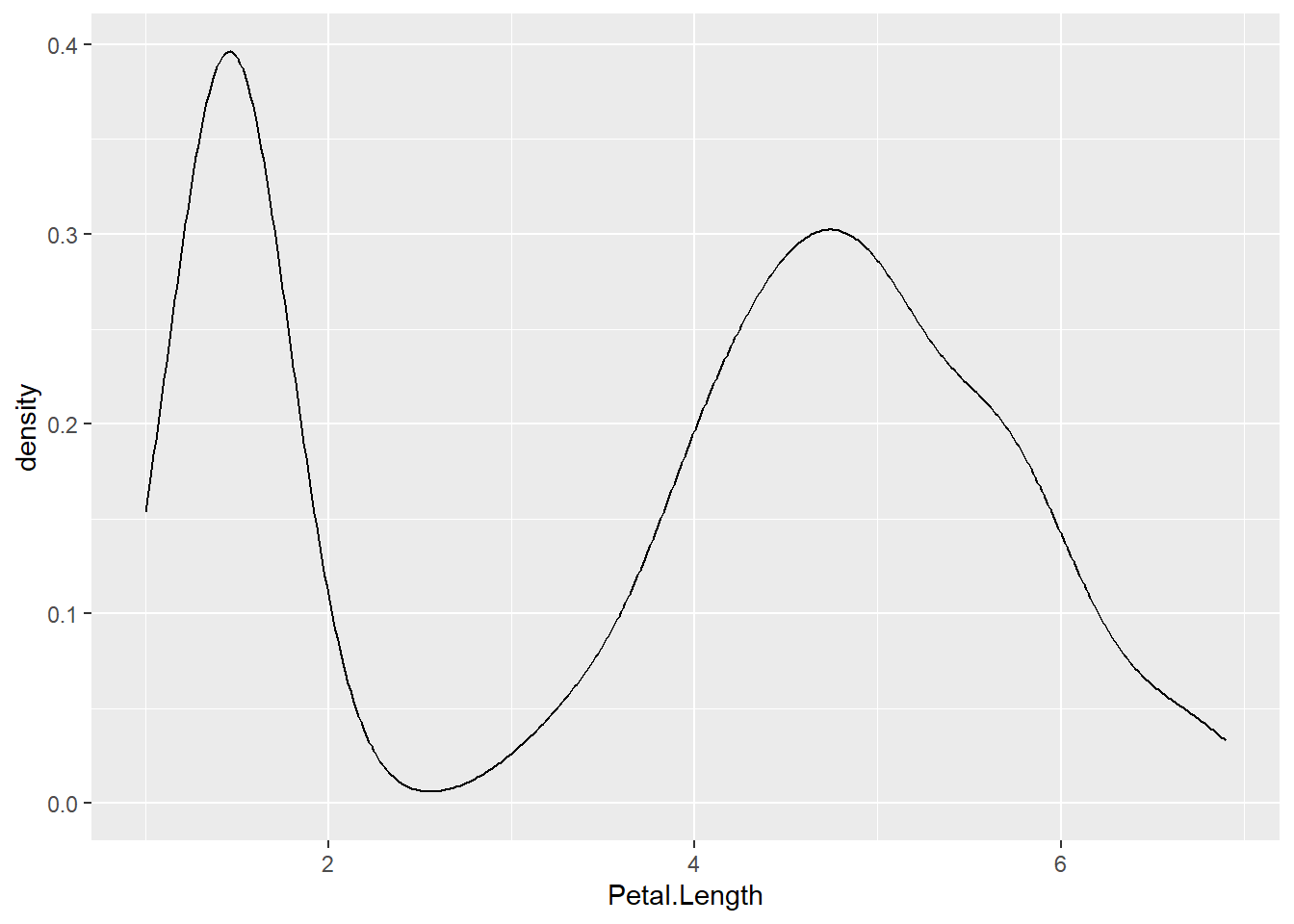
Une représentation alternative de la distribution d’une variable peut être obtenue avec une courbe de densité, dont la particularité est d’avoir une surface sous la courbe égale à 1. Une telle courbe s’obtient avec ggplot2::geom_density(). Le paramètre adjust permet d’ajuster le niveau de lissage de la courbe.
18.1.2 Variable catégorielle
Pour représenter la répartition des effectifs parmi les modalités d’une variable catégorielle, on a souvent tendance à utiliser des diagrammes en secteurs (camemberts
). Or, ce type de représentation graphique est très rarement appropriée : l’œil humain préfère comparer des longueurs plutôt que des surfaces1.
1 Voir en particulier https://www.data-to-viz.com/caveat/pie.html pour un exemple concret.
Dans certains contextes ou pour certaines présentations, on pourra éventuellement considérer un diagramme en donut
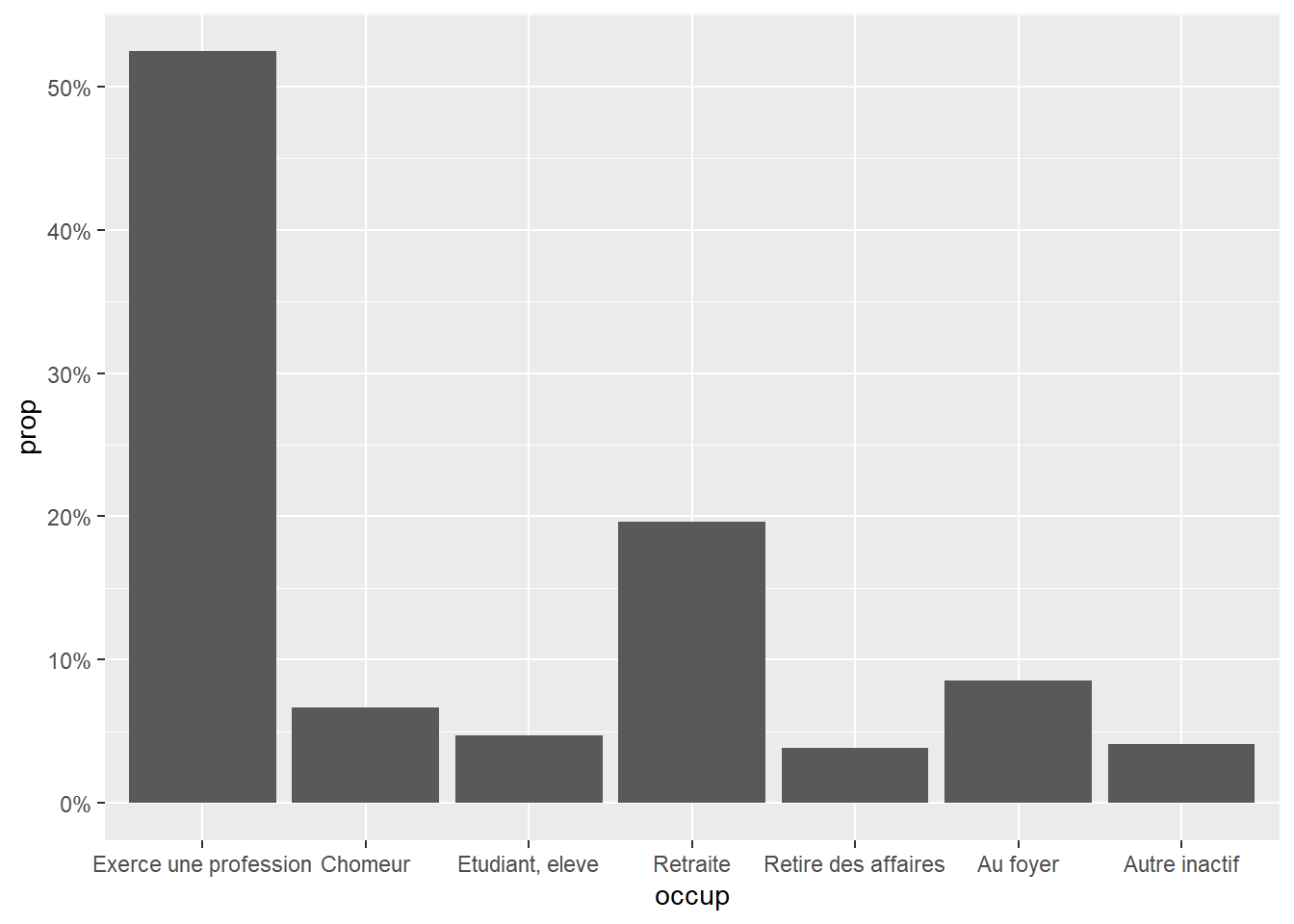
, mais le plus souvent, rien ne vaut un bon vieux diagramme en barres avec ggplot2::geom_bar(). Prenons pour l’exemple la variable occup du jeu de données hdv2003 du package questionr.
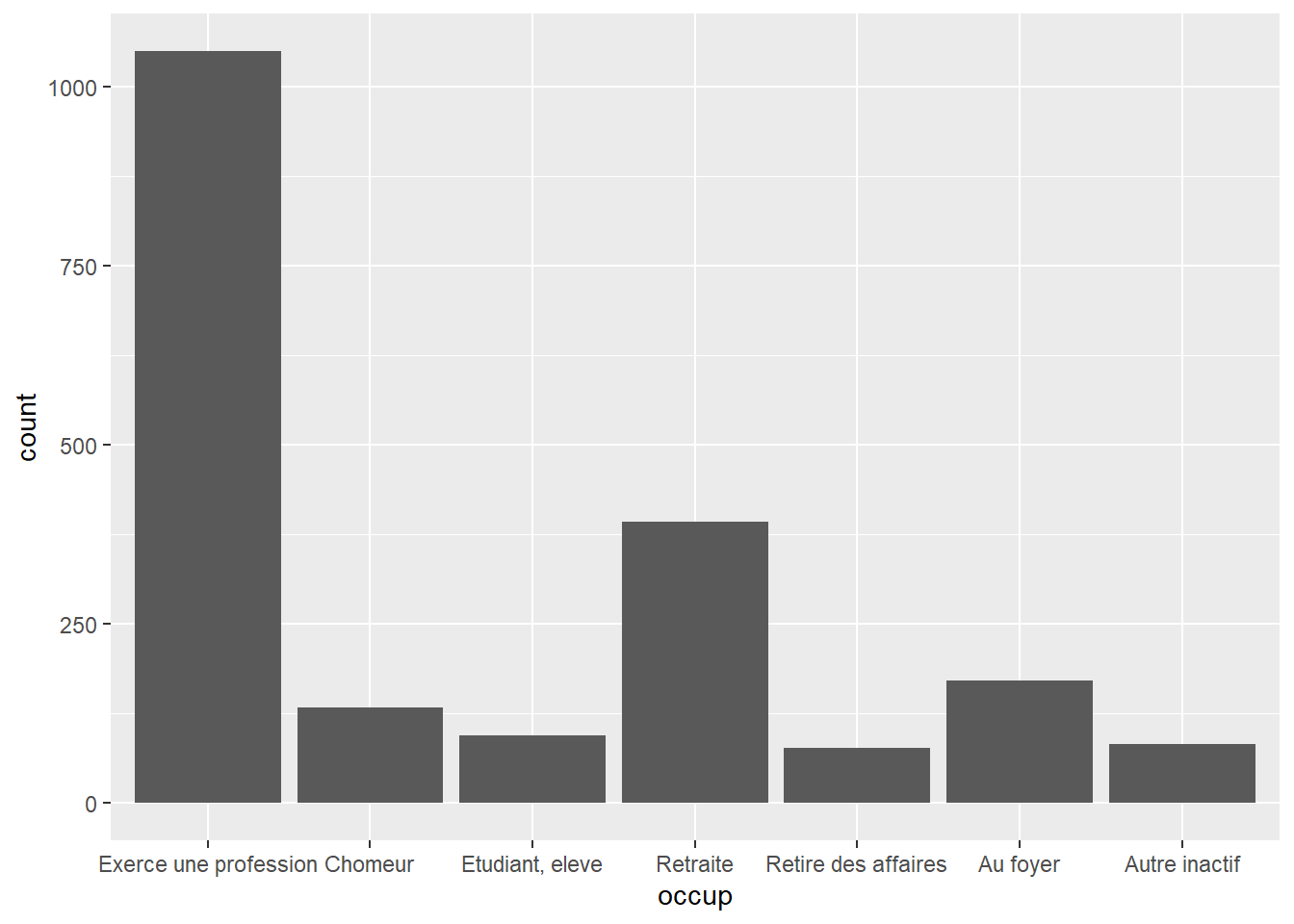
Là encore, ggplot2 a calculé de lui-même le nombre d’observations de chaque modalité, en utilisant cette fois la statistique ggplot2::stat_count().
Si l’on souhaite représenter des pourcentages plutôt que des effectifs, le plus simple est d’avoir recours à la statistique ggstats::stat_prop() du package ggstats. Pour appeler cette statistique, on utilisera simplement stat = "prop" dans les géométries concernées.
Cette statistique, qui sera également bien utile pour des graphiques plus complexes, nécessite qu’on lui indique une esthétique by pour indiquer dans quels sous-groupes calculer des proportions. Ici, nous avons un seul groupe considéré et nous souhaitons des pourcentages du total. On indiquera simplement by = 1.
Pour formater l’axe vertical avec des pourcentages, on pourra avoir recours à la fonction scales::label_percent() que l’on appellera via ggplot2::scale_y_continuous().
Pour une publication ou une communication, il ne faut surtout pas hésiter à épurer vos graphiques (less is better!), voire à trier les modalités en fonction de leur fréquence pour faciliter la lecture (ce qui se fait aisément avec forcats::fct_infreq()).
ggplot(hdv2003) +
aes(x = forcats::fct_infreq(occup),
y = after_stat(prop), by = 1) +
geom_bar(stat = "prop",
fill = "#4477AA", colour = "black") +
geom_text(
aes(
label = after_stat(prop) |>
scales::percent(accuracy = .1)
),
stat = "prop",
nudge_y = .02
) +
theme_minimal() +
theme(
panel.grid = element_blank(),
axis.text.y = element_blank()
) +
xlab(NULL) + ylab(NULL) +
ggtitle("Occupation des personnes enquêtées")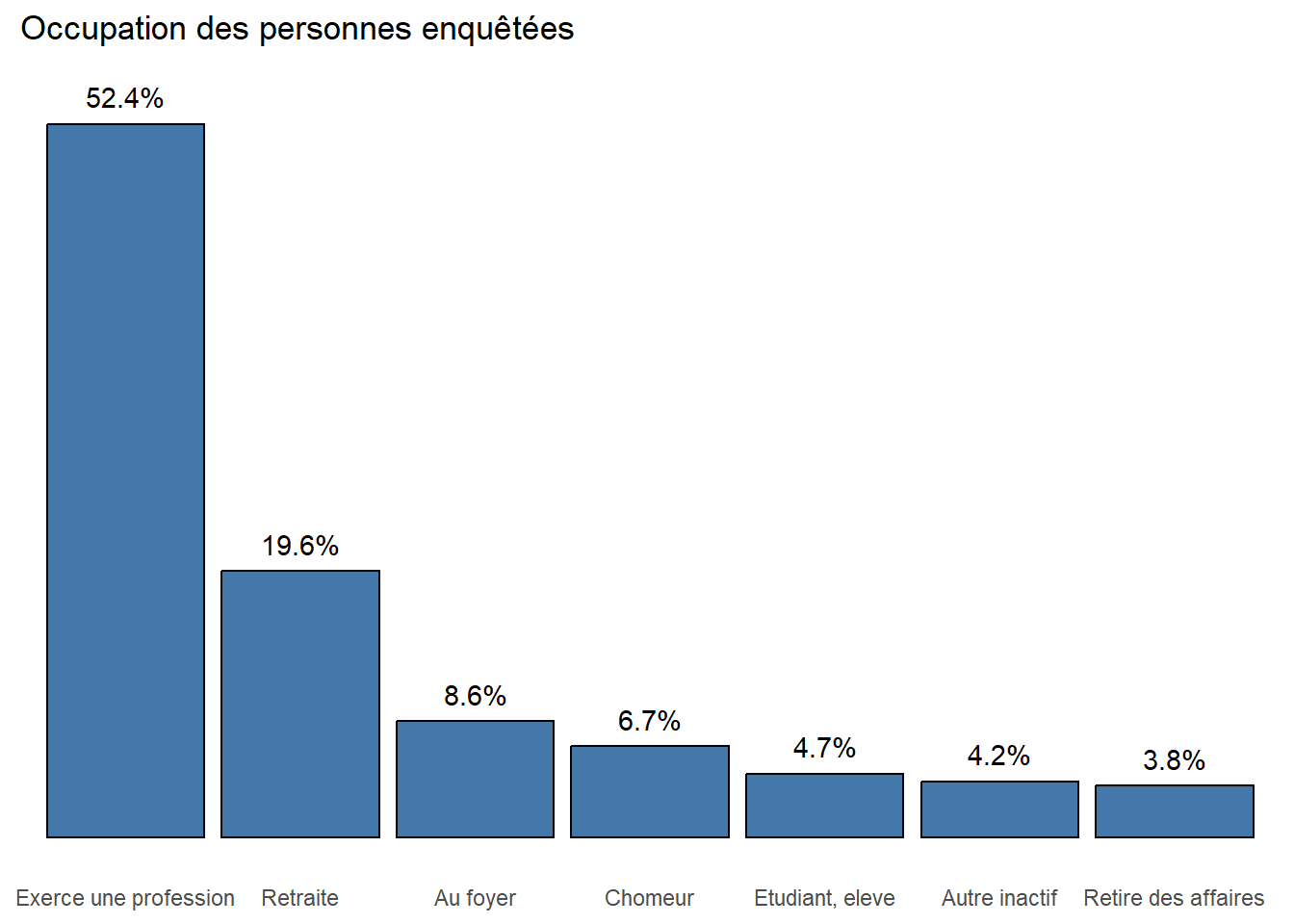
Le diaporama ci-dessous vous permet de visualiser chaque étape du code.
Pour représenter plusieurs variables catégorielles en un seul graphique, on pourra éventuellement profiter de la géométrie ggalluvial::geom_stratum() du package ggalluvial.
Cette géométrie est un peu particulière. On indiquera les différentes variables à représenter avec les esthétiques axis1, axis2, etc. On utilisera l’argument limits de ggplot2::scale_x_discrete() pour personnaliser l’axe des x.
library(ggalluvial)
ggplot(hdv2003) +
aes(axis1 = sexe, axis2 = occup, axis3 = sport) +
geom_stratum(
width = .9,
mapping = aes(fill = factor(after_stat(x))),
show.legend = FALSE
) +
geom_text(
stat = "stratum",
mapping = aes(label = after_stat(stratum))
) +
scale_x_discrete(
limits = c(
"Sexe",
"Occupation",
"Pratique un sport"
)
) +
khroma::scale_fill_bright() +
theme_minimal()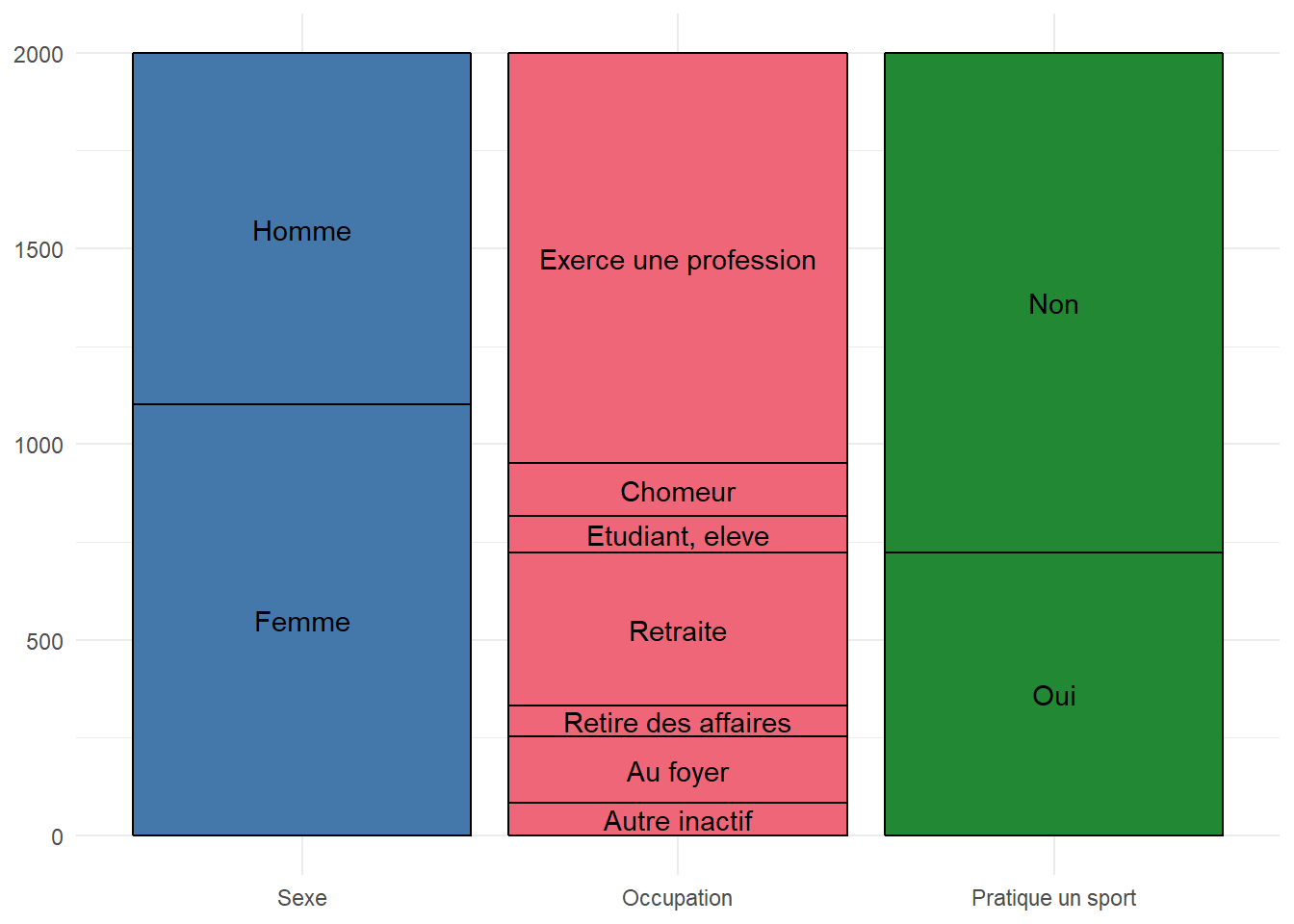
18.2 Tableaux et tris à plat
Le package gtsummary constitue l’une des boites à outils de l’analyste quantitative, car il permet de réaliser très facilement des tableaux quasiment publiables en l’état. En matière de statistiques univariées, la fonction clé est gtsummary::tbl_summary().
Commençons avec un premier exemple rapide. On part d’un tableau de données et on indique, avec l’argument include, les variables à afficher dans le tableau statistique (si on n’indique rien, toutes les variables du tableau de données sont considérées). Il faut noter que l’argument include de gtsummary::tbl_summary() utilise la même syntaxe dite tidy select
que dplyr::select() (cf. Section 8.2.1). On peut indiquer tout autant des variables catégorielles que des variables continues.
| Characteristic | N = 2,0001 |
|---|---|
| age | 48 (35, 60) |
| occup | |
| Exerce une profession | 1,049 (52%) |
| Chomeur | 134 (6.7%) |
| Etudiant, eleve | 94 (4.7%) |
| Retraite | 392 (20%) |
| Retire des affaires | 77 (3.9%) |
| Au foyer | 171 (8.6%) |
| Autre inactif | 83 (4.2%) |
| 1 Median (Q1, Q3); n (%) | |
gtsummary permets de réaliser des tableaux statistiques combinant plusieurs variables, l’affichage des résultats pouvant dépendre du type de variables.
Par défaut, gtsummary considère qu’une variable est catégorielle s’il s’agit d’un facteur, d’une variable textuelle ou d’une variable numérique ayant moins de 10 valeurs différentes.
Une variable sera considérée comme dichotomique (variable catégorielle à seulement deux modalités) s’il s’agit d’un vecteur logique (TRUE/FALSE), d’une variable textuelle codée yes/no ou d’une variable numérique codée 0/1.
Dans les autres cas, une variable numérique sera considérée comme continue.
Si vous utilisez des vecteurs labellisés (cf. Chapitre 12), vous devez les convertir, en amont, en facteurs ou en variables numériques. Voir l’extension labelled et les fonctions labelled::to_factor(), labelled::unlabelled() et unclass().
Au besoin, il est possible de forcer le type d’une variable avec l’argument type de gtsummary::tbl_summary().
gtsummary fournit des sélecteurs qui peuvent être utilisés dans les options des différentes fonctions, en particulier gtsummary::all_continuous() pour les variables continues, gtsummary::all_dichotolous() pour les variables dichotomiques et gtsummary::all_categorical() pour les variables catégorielles. Cela inclue les variables dichotomiques. Il faut utiliser all_categorical(dichotomous = FALSE) pour sélectionner les variables catégorielles en excluant les variables dichotomiques.
18.2.1 Thème du tableau
gtsummary fournit plusieurs fonctions préfixées theme_gtsummary_*() permettant de modifier l’affichage par défaut des tableaux. Vous aurez notez que, par défaut, gtsummary est anglophone.
La fonction gtsummary::theme_gtsummary_journal() permets d’adopter les standards de certaines grandes revues scientifiques telles que JAMA (Journal of the American Medical Association), The Lancet ou encore le NEJM (New England Journal of Medicine).
La fonction gtsummary::theme_gtsummary_language() permet de modifier la langue utilisée par défaut dans les tableaux. Les options decimal.mark et big.mark permettent de définir respectivement le séparateur de décimales et le séparateur des milliers. Ainsi, pour présenter un tableau en français, on appliquera en début de script :
Setting theme "language: fr"Ce thème sera appliqué à tous les tableaux ultérieurs.
Le package guideR, le compagnon de guide-R, propose également quelques thèmes complémentaires. Notamment, guideR::theme_gtsummary_prop_n() permet d’afficher d’abord les proportions, en forçant le nombre de décimales à 1, suivi des effectifs entre parenthèses. Le thème guideR::theme_gtsummary_bold_labels() applique quant à lui du gras à tous les noms de variable.
| Caractéristique | N = 2 0001 |
|---|---|
| age | 48,0 (35,0, 60,0) |
| occup | |
| Exerce une profession | 52,5% (1 049) |
| Chomeur | 6,7% (134) |
| Etudiant, eleve | 4,7% (94) |
| Retraite | 19,6% (392) |
| Retire des affaires | 3,9% (77) |
| Au foyer | 8,6% (171) |
| Autre inactif | 4,2% (83) |
| 1 Médiane (Q1, Q3); % (n) | |
18.2.2 Étiquettes des variables
gtsummary, par défaut, prends en compte les étiquettes de variables (cf. Chapitre 11), si elles existent, et sinon utilisera le nom de chaque variable dans le tableau. Pour rappel, les étiquettes de variables peuvent être manipulées avec l’extension labelled et les fonctions labelled::var_label() et labelled::set_variable_labels().
Il est aussi possible d’utiliser l’option label de gtsummary::tbl_summary() pour indiquer des étiquettes personnalisées.
| Caractéristique | N = 2 0001 |
|---|---|
| Âge médian | 48,0 (35,0, 60,0) |
| Occupation actuelle | |
| Exerce une profession | 52,5% (1 049) |
| Chomeur | 6,7% (134) |
| Etudiant, eleve | 4,7% (94) |
| Retraite | 19,6% (392) |
| Retire des affaires | 3,9% (77) |
| Au foyer | 8,6% (171) |
| Autre inactif | 4,2% (83) |
| heures.tv | 2,0 (1,0, 3,0) |
| Manquant | 5 |
| 1 Médiane (Q1, Q3); % (n) | |
Pour modifier les modalités d’une variable catégorielle, il faut modifier en amont les niveaux du facteur correspondant.
De nombreuses options des fonctions de gtsummary peuvent s’appliquer seulement à une ou certaines variables. Pour ces options-là, gtsummary attends une formule de la forme variables concernées ~ valeur de l'option ou bien une liste de formules ayant cette forme.
Par exemple, pour modifier l’étiquette associée à une certaine variable, on peut utiliser l’option label de gtsummary::tbl_summary().
Lorsque l’on souhaite passer plusieurs options pour plusieurs variables différentes, on utilisera une list().
gtsummary est très flexible sur la manière d’indiquer la ou les variables concernées. Il peut s’agir du nom de la variable, d’une chaîne de caractères contenant le nom de la variable, ou d’un vecteur contenant le nom de la variable. Les syntaxes ci-dessous sont ainsi équivalentes.
Pour appliquer le même changement à plusieurs variables, plusieurs syntaxes sont acceptées pour lister plusieurs variables.
Il est également possible d’utiliser la syntaxe tidyselect et les sélecteurs de tidyselect comme tidyselect::everything(), tidyselect::starts_with(), tidyselect::contains() ou tidyselect::all_of(). Ces différents sélecteurs peuvent être combinés au sein d’un c().
En plus, il est possible d’utiliser les sélecteurs propres à gtsummary.
Enfin, si l’on ne précise rien à gauche du ~, ce sera considéré comme équivalent à everything(). Les deux syntaxes ci-dessous sont donc équivalentes.
18.2.3 Statistiques affichées
Le paramètre statistic permets de sélectionner les statistiques à afficher pour chaque variable. On indiquera une chaîne de caractères dont les différentes statistiques seront indiquées entre accolades ({}).
Pour une variable continue, on pourra utiliser {median} pour la médiane, {mean} pour la moyenne, {sd} pour l’écart type, {var} pour la variance, {min} pour le minimum, {max} pour le maximum, ou encore {p##} (en remplaçant ## par un nombre entier entre 00 et 100) pour le percentile correspondant (par exemple p25 et p75 pour le premier et le troisième quartile). Utilisez gtsummary::all_continous() pour sélectionner toutes les variables continues.
| Caractéristique | N = 2 0001 |
|---|---|
| age | Moy. : 48,2 [min-max : 18,0 - 97,0] |
| heures.tv | Moy. : 2,2 [min-max : 0,0 - 12,0] |
| Manquant | 5 |
| 1 Moy. : Moyenne [min-max : Min - Max] | |
Il est possible d’afficher des statistiques différentes pour chaque variable.
| Caractéristique | N = 2 0001 |
|---|---|
| age | Méd. : 48,0 [35,0 - 60,0] |
| heures.tv | Moy. : 2,2 (1,8) |
| Manquant | 5 |
| 1 Méd. : Médiane [Q1 - Q3]; Moy. : Moyenne (ET) | |
Pour les variables continues, il est également possible d’indiquer le nom d’une fonction personnalisée qui prends un vecteur et renvoie une valeur résumée. Par exemple, pour afficher la moyenne des carrés :
| Caractéristique | N = 2 0001 |
|---|---|
| heures.tv | MC : 8,2 |
| Manquant | 5 |
| 1 MC : moy_carres | |
Par défaut, les variables continues sont représentées avec leur médiane et leur intervalle interquartile.
Si l’on souhaite afficher à la place la moyenne et l’écart-type, il faut indiquer le changement manuellement à chaque tableau avec le paramètre statistic. Cependant, gtsummary fournit un thème gtsummary::theme_gtsummary_mean_sd() qui permet de faire ce changement de manière systématique pour tous les tableaux suivants.
À noter, gtsummary::theme_gtsummary_mean_sd() n’est pas compatibles avec guideR::theme_gtsummary_prop_n(). Si l’on veut combiner les deux options, on optera alors la version guideR::theme_gtsummary_prop_n(mean_sd = TRUE).
Cela présente par ailleurs d’autres avantages que nous verrons plus loin, car guideR::theme_gtsummary_prop_n() met également à jour les intervalles de confiance renvoyés par gtsummary::add_ci() et les tests par défaut utilisés par gtsummary::add_p().
Pour une variable catégorielle, les statistiques possibles sont {n} le nombre d’observations, {N} le nombre total d’observations, et {p} le pourcentage correspondant. Utilisez gtsummary::all_categorical() pour sélectionner toutes les variables catégorielles.
| Caractéristique | N = 2 0001 |
|---|---|
| occup | |
| Exerce une profession | 52,5 % (1 049/2 000) |
| Chomeur | 6,7 % (134/2 000) |
| Etudiant, eleve | 4,7 % (94/2 000) |
| Retraite | 19,6 % (392/2 000) |
| Retire des affaires | 3,9 % (77/2 000) |
| Au foyer | 8,6 % (171/2 000) |
| Autre inactif | 4,2 % (83/2 000) |
| 1 | |
Il est possible, pour une variable catégorielle, de trier les modalités de la plus fréquente à la moins fréquente avec le paramètre sort.
| Caractéristique | N = 2 0001 |
|---|---|
| occup | |
| Exerce une profession | 52,5% (1 049) |
| Retraite | 19,6% (392) |
| Au foyer | 8,6% (171) |
| Chomeur | 6,7% (134) |
| Etudiant, eleve | 4,7% (94) |
| Autre inactif | 4,2% (83) |
| Retire des affaires | 3,9% (77) |
| 1 | |
Pour toutes les variables (catégorielles et continues), les statistiques suivantes sont également disponibles :
-
{N_obs}le nombre total d’observations, -
{N_miss}le nombre d’observations manquantes (NA), -
{N_nonmiss}le nombre d’observations non manquantes, -
{p_miss}le pourcentage d’observations manquantes (i.e.N_miss / N_obs) et -
{p_nonmiss}le pourcentage d’observations non manquantes (i.e.N_nonmiss / N_obs).
18.2.4 Affichage du nom des statistiques
Lorsque l’on affiche de multiples statistiques, la liste des statistiques est regroupée dans une note de tableau qui peut vite devenir un peu confuse.
| Caractéristique | N = 2 0001 |
|---|---|
| age | 48,2 (16,9) |
| heures.tv | 2,0 [1,0 - 3,0] |
| Manquant | 5 |
| occup | |
| Exerce une profession | 52,5% (1 049) |
| Chomeur | 6,7% (134) |
| Etudiant, eleve | 4,7% (94) |
| Retraite | 19,6% (392) |
| Retire des affaires | 3,9% (77) |
| Au foyer | 8,6% (171) |
| Autre inactif | 4,2% (83) |
| 1 Moyenne (ET); Médiane [Q1 - Q3]; % (n) | |
La fonction gtsummary::add_stat_label() permets d’indiquer le type de statistique à côté du nom des variables ou bien dans une colonne dédiée, plutôt qu’en note de tableau.
| Caractéristique | N = 2 000 |
|---|---|
| age, Moyenne (ET) | 48,2 (16,9) |
| heures.tv, Médiane [Q1 - Q3] | 2,0 [1,0 - 3,0] |
| Manquant | 5 |
| occup, % (n) | |
| Exerce une profession | 52,5% (1 049) |
| Chomeur | 6,7% (134) |
| Etudiant, eleve | 4,7% (94) |
| Retraite | 19,6% (392) |
| Retire des affaires | 3,9% (77) |
| Au foyer | 8,6% (171) |
| Autre inactif | 4,2% (83) |
| Caractéristique | Statistique | N = 2 000 |
|---|---|---|
| age | Moyenne (ET) | 48,2 (16,9) |
| heures.tv | Médiane [Q1 - Q3] | 2,0 [1,0 - 3,0] |
| Manquant | n | 5 |
| occup | ||
| Exerce une profession | % (n) | 52,5% (1 049) |
| Chomeur | % (n) | 6,7% (134) |
| Etudiant, eleve | % (n) | 4,7% (94) |
| Retraite | % (n) | 19,6% (392) |
| Retire des affaires | % (n) | 3,9% (77) |
| Au foyer | % (n) | 8,6% (171) |
| Autre inactif | % (n) | 4,2% (83) |
18.2.5 Forcer le type de variable
Comme évoqué plus haut, gtsummary détermine automatiquement le type de chaque variable. Par défaut, la variable age du tableau de données trial est traitée comme variable continue, death comme dichotomique (seule la valeur 1 est affichée) et grade comme variable catégorielle.
| Caractéristique | N = 2001 |
|---|---|
| Grade | |
| I | 34,0% (68) |
| II | 34,0% (68) |
| III | 32,0% (64) |
| Age | 47,2 (14,3) |
| Manquant | 11 |
| Patient Died | 56,0% (112) |
| 1 | |
Il est cependant possible de forcer un certain type avec l’argument type. Précision : lorsque l’on force une variable en dichotomique, il faut indiquer avec value la valeur à afficher (les autres sont alors masquées).
| Caractéristique | N = 2001 |
|---|---|
| Grade III | 32,0% (64) |
| Patient Died | |
| 0 | 44,0% (88) |
| 1 | 56,0% (112) |
| 1 | |
Il ne faut pas oublier que, par défaut, gtsummary traite les variables quantitatives avec moins de 10 valeurs comme des variables catégorielles. Prenons un exemple :
| Caractéristique | N = 2001 |
|---|---|
| alea | |
| 1 | 22,5% (45) |
| 2 | 28,0% (56) |
| 3 | 23,0% (46) |
| 4 | 26,5% (53) |
| 1 | |
On pourra forcer le traitement de cette variable comme continue.
18.2.6 Afficher des statistiques sur plusieurs lignes (variables continues)
Pour les variables continues, gtsummary a introduit un type de variable "continuous2", qui doit être attribué manuellement via type, et qui permets d’afficher plusieurs lignes de statistiques (en indiquant plusieurs chaînes de caractères dans statistic). À noter le sélecteur dédié gtsummary::all_continuous2().
| Caractéristique | N = 2 0001 |
|---|---|
| age | |
| Médiane (Q1 - Q3) | 48,0 (35,0 - 60,0) |
| Moyenne (ET) | 48,2 (16,9) |
| Min - Max | 18,0 - 97,0 |
| heures.tv | 2,2 (1,8) |
| Manquant | 5 |
| 1 Moyenne (ET) | |
18.2.7 Mise en forme des statistiques
L’argument digits permet de spécifier comment mettre en forme les différentes statistiques. Le plus simple est d’indiquer le nombre de décimales à afficher. Il est important de tenir compte que plusieurs statistiques peuvent être affichées pour une même variable. On peut alors indiquer une valeur différente pour chaque statistique.
| Caractéristique | N = 2 0001 |
|---|---|
| age | 48,2 (16,9) |
| occup | |
| Exerce une profession | 52,5% (1 049) |
| Chomeur | 6,7% (134) |
| Etudiant, eleve | 4,7% (94) |
| Retraite | 19,6% (392) |
| Retire des affaires | 3,9% (77) |
| Au foyer | 8,6% (171) |
| Autre inactif | 4,2% (83) |
| 1 Moyenne (ET); % (n) | |
On peut aussi nommer les statistiques concernées dans l’argument digits. Cela est même recommandé pour éviter toute confusion.
| Caractéristique | N = 2 0001 |
|---|---|
| age | 48,16 (16,9) |
| occup | |
| Exerce une profession | 52,5% (1 049) |
| Chomeur | 6,7% (134) |
| Etudiant, eleve | 4,7% (94) |
| Retraite | 19,6% (392) |
| Retire des affaires | 3,9% (77) |
| Au foyer | 8,6% (171) |
| Autre inactif | 4,2% (83) |
| 1 Moyenne (ET); % (n) | |
Au lieu d’un nombre de décimales, on peut indiquer plutôt une fonction à appliquer pour mettre en forme le résultat. Par exemple, gtsummary fournit les fonctions suivantes : gtsummary::style_number() pour les nombres de manière générale, gtsummary::style_percent() pour les pourcentages (les valeurs sont multipliées par 100, mais le symbole % n’est pas ajouté), gtsummary::style_pvalue() pour les p-valeurs, gtsummary::style_sigfig() qui n’affiche, par défaut, que deux chiffres significatifs, ou encore gtsummary::style_ratio() qui est une variante de gtsummary::style_sigfig() pour les ratios (comme les odds ratios) que l’on compare à 1.
Il faut bien noter que ce qui est attendu par digits, c’est une fonction et non le résultat d’une fonction. On indiquera donc le nom de la fonction sans parenthèse, comme dans l’exemple ci-dessous (même si pas forcément pertinent ;-)).
| Caractéristique | N = 2 0001 |
|---|---|
| age | 4 816 (17) |
| 1 Moyenne (ET) | |
Comme digits s’attend à recevoir une fonction (et non le résultat) d’une fonction, on ne peut pas passer directement des arguments aux fonctions style_*() de gtsummary. Pour cela, on aura recours à leurs équivalents label_style_*() qui ne mettent pas directement un nombre en forme, mais renvoient une fonction de mise en forme.
| Caractéristique | N = 2001 |
|---|---|
| Marker Level (ng/mL) | 91,6 pour 100 |
| Manquant | 10 |
| 1 Moyenne pour 100 | |
À noter dans l’exemple précédent que les fonctions style_*() et label_style_*() de gtsummary tiennent compte du thème défini (ici la virgule comme séparateur de décimale).
Pour une mise en forme plus avancée des nombres, il faut se tourner vers l’extension scales et ses diverses fonctions de mise en forme comme scales::label_number() ou scales::label_percent().
ATTENTION : les fonctions de scales n’héritent pas des paramètres du thème gtsummary actif. Il faut donc personnaliser le séparateur de décimal dans l’appel à la fonction.
| Caractéristique | N = 2001 |
|---|---|
| Marker Level (ng/mL) | 0,92 ng/mL |
| Manquant | 10 |
| 1 Moyenne | |
18.2.8 Données manquantes
Le paramètre missing permets d’indiquer s’il faut afficher le nombre d’observations manquantes (c’est-à-dire égales à NA) : "ifany" (valeur par défaut) affiche ce nombre seulement s’il y en a, "no" masque ce nombre et "always" force l’affichage de ce nombre même s’il n’y pas de valeur manquante. Le paramètre missing_text permets de personnaliser le texte affiché.
| Caractéristique | N = 2 0001 |
|---|---|
| age | 48,2 (16,9) |
| Nbre observations manquantes | 0 |
| heures.tv | 2,2 (1,8) |
| Nbre observations manquantes | 5 |
| 1 Moyenne (ET) | |
Il est à noter, pour les variables catégorielles, que les valeurs manquantes ne sont jamais pris en compte pour le calcul des pourcentages. Pour les inclure dans le calcul, il faut les transformer en valeurs explicites, par exemple avec forcats::fct_na_value_to_level() de forcats.
| Caractéristique | N = 2 0001 |
|---|---|
| trav.imp | |
| Le plus important | 2,8% (29) |
| Aussi important que le reste | 24,7% (259) |
| Moins important que le reste | 67,6% (708) |
| Peu important | 5,0% (52) |
| Manquant | 952 |
| trav.imp.explicit | |
| Le plus important | 1,5% (29) |
| Aussi important que le reste | 13,0% (259) |
| Moins important que le reste | 35,4% (708) |
| Peu important | 2,6% (52) |
| (non renseigné) | 47,6% (952) |
| 1 | |
18.2.9 Ajouter les effectifs observés
Lorsque l’on masque les manquants, il peut être pertinent d’ajouter une colonne avec les effectifs observés pour chaque variable à l’aide de la fonction gtsummary::add_n().
| Caractéristique | N | N = 2 0001 |
|---|---|---|
| heures.tv | 1 995 | 2,2 (1,8) |
| trav.imp | 1 048 | |
| Le plus important | 2,8% (29) | |
| Aussi important que le reste | 24,7% (259) | |
| Moins important que le reste | 67,6% (708) | |
| Peu important | 5,0% (52) | |
| 1 Moyenne (ET); % (n) | ||
18.3 Calcul manuel
18.3.1 Variable continue
R fournit de base toutes les fonctions nécessaires pour le calcul des différentes statistiques descriptives :
-
mean()pour la moyenne -
sd()pour l’écart-type -
min()etmax()pour le minimum et le maximum -
range()pour l’étendue -
median()pour la médiane
Si la variable contient des valeurs manquantes (NA), ces fonctions renverront une valeur manquante, sauf si on leur précise na.rm = TRUE.
[1] NA[1] 2.246566[1] 1.775853[1] 0[1] 12[1] 0 12[1] 2La fonction quantile() permets de calculer tous types de quantiles.
0% 25% 50% 75% 100%
0 1 2 3 12 20% 40% 60% 80%
1 2 2 3 La fonction summary() renvoie la plupart de ces indicateurs en une seule fois, ainsi que le nombre de valeurs manquantes.
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.000 1.000 2.000 2.247 3.000 12.000 5 Le package guideR fournit deux fonctions bien pratiques dans ce contexte : guideR::mean_sd() et guideR::median_iqr(). Ces deux fonctions s’appliquent sur un tableau de données et suivent une syntaxe similaire aux fonctions du tidyverse. Elles renvoient par ailleurs les résultats sous forme d’un tableau de données qui peut, par la suite, être facilement réutilisés pour d’autres calculs ou des graphiques.
La fonction guideR::mean_sd() renvoie tout simplement la moyenne et l’écart-type (standard deviation ou sd en anglais), ainsi que le nombre d’observations valides (n) et de manquants (missing).
# A tibble: 1 × 5
x mean sd n missing
<chr> <dbl> <dbl> <int> <int>
1 heures.tv 2.25 1.78 1995 5La fonction guideR::median_iqr() renvoie, quant à elle, la médiane, le minimum, le premier quartile (q1), le troisième quartile (q3), le maximum et l’intervalle interquartile (interquartile range ou iqr en anglais) soit la différence entre q3 et q1. Là encore sont renvoyés le nombre d’observations valides et de manquants.
18.3.2 Variable catégorielle
Les fonctions de base pour le calcul d’un tri à plat sont les fonctions table() et xtabs(). Leur syntaxe est quelque peu différente. On passe un vecteur entier à table() alors que la syntaxe de xtabs() se rapproche de celle d’un modèle linéaire : on décrit le tableau attendu à l’aide d’une formule et on indique le tableau de données. Les deux fonctions renvoient le même résultat.
trav.imp
Le plus important Aussi important que le reste
29 259
Moins important que le reste Peu important
708 52 Comme on le voit, il s’agit du tableau brut des effectifs, sans les valeurs manquantes, et pas vraiment lisible dans la console de R.
Pour calculer les proportions, on appliquera proportions() (au pluriel) sur la table des effectifs bruts.
trav.imp
Le plus important Aussi important que le reste
0.02767176 0.24713740
Moins important que le reste Peu important
0.67557252 0.04961832 Pour la réalisation rapide d’un tri à plat, on pourra aussi utiliser la fonction questionr::freq() qui affiche également le nombre de valeurs manquantes et les pourcentages, en un seul appel.
n % val%
Le plus important 29 1.5 2.8
Aussi important que le reste 259 13.0 24.7
Moins important que le reste 708 35.4 67.6
Peu important 52 2.6 5.0
NA 952 47.6 NACeci dit, si l’on préfère une approche à la dplyr, on pourra se reposer sur dplyr::count() qui permet de compter le nombre d’observations.
trav.imp n
1 Le plus important 29
2 Aussi important que le reste 259
3 Moins important que le reste 708
4 Peu important 52
5 <NA> 952À partir de là, il est possible de calculer à la suite les proportions en utilisant proportions() (au pluriel) au sein d’un dplyr::mutate().
trav.imp n prop
1 Le plus important 29 0.0145
2 Aussi important que le reste 259 0.1295
3 Moins important que le reste 708 0.3540
4 Peu important 52 0.0260
5 <NA> 952 0.4760Ou encore plus simplement, on pourra avoir recours à guideR, le package compagnon de guide-R et qui propose une fonction proportion() (sans s, comme le verbe anglais to proportion).
# A tibble: 5 × 4
trav.imp n N prop
<fct> <int> <int> <dbl>
1 Le plus important 29 2000 1.45
2 Aussi important que le reste 259 2000 13.0
3 Moins important que le reste 708 2000 35.4
4 Peu important 52 2000 2.6
5 <NA> 952 2000 47.6 Notez que, par défaut, les proportions sont multipliées par 100 pour afficher des pourcentages. Ceci est modifiable avec .scale. L’argument .na.rm permet quant à lui de retirer les valeurs manquantes du calcul.
18.4 Intervalles de confiance
18.4.1 Intervalles de confiance avec gtsummary
La fonction gtsummary::add_ci() permet d’ajouter des intervalles de confiance à un tableau créé avec gtsummary::tbl_summary().
Par défaut, pour les variables continues, gtsummary::tbl_summary() affiche la médiane tandis que gtsummary::add_ci() calcule l’intervalle de confiance d’une moyenne !
Il faut donc :
- soit afficher la moyenne dans
gtsummary::tbl_summary()à l’aide du paramètrestatistic; - soit calculer les intervalles de confiance d’une médiane (méthode
"wilcox.text") via le paramètremethoddegtsummary::add_ci().
ENCORE PLUS SIMPLE
Utiliser guideR::theme_gtsummary_prop_n(). En effet, si on l’appelle avec ses options par défaut, cela affiche la médiane et l’IQR pour les variables continues et définie "wilcox.test" comme méthode par défaut pour les intervalles de confiance des variables continues. Si on l’appelle avec l’option mean_sd = TRUE, alors c’est la moyenne qui est affichée et la méthode "t.test" est appliquée pour les intervalles de confiance.
| Caractéristique | N = 2 0001 | 95% IC |
|---|---|---|
| age | 48,0 (35,0, 60,0) | 47, 49 |
| heures.tv | 2,0 (1,0, 3,0) | 2,5, 2,5 |
| Manquant | 5 | |
| trav.imp | ||
| Le plus important | 2,8% (29) | 1,9%, 4,0% |
| Aussi important que le reste | 24,7% (259) | 22%, 27% |
| Moins important que le reste | 67,6% (708) | 65%, 70% |
| Peu important | 5,0% (52) | 3,8%, 6,5% |
| Manquant | 952 | |
| 1 Médiane (Q1, Q3); % (n) | ||
| Abréviation: IC = intervalle de confiance | ||
L’argument statistic permet de personnaliser la présentation de l’intervalle ; conf.level de changer le niveau de confiance et style_fun de modifier la mise en forme des nombres de l’intervalle.
| Caractéristique | N = 2 0001 | 90% IC |
|---|---|---|
| age | 48,2 (16,9) | entre 47,5 et 48,8 |
| heures.tv | 2,2 (1,8) | entre 2,2 et 2,3 |
| Manquant | 5 | |
| 1 Moyenne (ET) | ||
| Abréviation: IC = intervalle de confiance | ||
18.4.2 Calcul manuel des intervalles de confiance
Le calcul de l’intervalle de confiance d’une moyenne s’effectue avec la fonction t.test().
One Sample t-test
data: hdv2003$age
t = 127.12, df = 1999, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
47.41406 48.89994
sample estimates:
mean of x
48.157 Le résultat renvoyé est une liste contenant de multiples informations.
List of 10
$ statistic : Named num 127
..- attr(*, "names")= chr "t"
$ parameter : Named num 1999
..- attr(*, "names")= chr "df"
$ p.value : num 0
$ conf.int : num [1:2] 47.4 48.9
..- attr(*, "conf.level")= num 0.95
$ estimate : Named num 48.2
..- attr(*, "names")= chr "mean of x"
$ null.value : Named num 0
..- attr(*, "names")= chr "mean"
$ stderr : num 0.379
$ alternative: chr "two.sided"
$ method : chr "One Sample t-test"
$ data.name : chr "hdv2003$age"
- attr(*, "class")= chr "htest"Si l’on a besoin d’accéder spécifiquement à l’intervalle de confiance calculé :
[1] 47.41406 48.89994
attr(,"conf.level")
[1] 0.95Plus simplement, on pourra avoir recours à guideR::mean_sd() avec l’option .conf.int = TRUE.
Pour l’intervalle de confiance d’une médiane, on utilisera wilcox.test() en précisant conf.int = TRUE.
Wilcoxon signed rank test with continuity correction
data: hdv2003$age
V = 2001000, p-value < 2.2e-16
alternative hypothesis: true location is not equal to 0
95 percent confidence interval:
47.00001 48.50007
sample estimates:
(pseudo)median
47.99996 [1] 47.00001 48.50007
attr(,"conf.level")
[1] 0.95Au sens strict, stats::wilcox.test() ne renvoie pas l’intervalle de confiance de la médiane, mais de la pseudo-médiane, ce qui dans certains cas peut différer sensiblement de la médiane.
En pratique, il est rare que l’on calcule l’interface de confiance d’une médiane.
Pour une proportion, on utilisera prop.test() en lui transmettant le nombre de succès et le nombre d’observations, qu’il faudra donc avoir calculé au préalable. On peut également passer une table à deux entrées avec le nombre de succès puis le nombre d’échecs.
Ainsi, pour obtenir l’intervalle de confiance de la proportion des enquêtés qui considèrent leur travail comme peu important, en tenant compte des valeurs manquantes, le plus simple est d’effectuer le code suivant2 :
1-sample proportions test with continuity correction
data: rev(xtabs(~I(hdv2003$trav.imp == "Peu important"), data = hdv2003)), null probability 0.5
X-squared = 848.52, df = 1, p-value < 2.2e-16
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.03762112 0.06502346
sample estimates:
p
0.04961832 Par défaut, prop.test() produit un intervalle de confiance bilatéral en utilisant la méthode de Wilson avec correction de continuité. Pour plus d’information sur les différentes manières de calculer l’intervalle de confiance d’une proportion, on pourra se référer à ce billet de blog.
Comme on le voit, il n’est pas aisé, avec les fonctions de R base de calculer les intervalles de confiance pour toutes les modalités d’une variable catégorielle.
On pourra, dès lors, profiter de la fonction guideR::proportion() qui peut facilement calculer les intervalles de confiances. Il suffit de lui préciser .conf.int = TRUE.
# A tibble: 5 × 6
trav.imp n N prop prop_low prop_high
<fct> <int> <int> <dbl> <dbl> <dbl>
1 Le plus important 29 2000 1.45 0.991 2.10
2 Aussi important que le reste 259 2000 13.0 11.5 14.5
3 Moins important que le reste 708 2000 35.4 33.3 37.5
4 Peu important 52 2000 2.6 1.97 3.42
5 <NA> 952 2000 47.6 45.4 49.8 # A tibble: 5 × 6
trav.imp n N prop prop_low prop_high
<fct> <int> <int> <dbl> <dbl> <dbl>
1 Le plus important 29 2000 0.0145 0.00991 0.0210
2 Aussi important que le reste 259 2000 0.130 0.115 0.145
3 Moins important que le reste 708 2000 0.354 0.333 0.375
4 Peu important 52 2000 0.026 0.0197 0.0342
5 <NA> 952 2000 0.476 0.454 0.498 18.5 webin-R
La statistique univariée est présentée dans le webin-R #03 (statistiques descriptives avec gtsummary et esquisse) sur YouTube.
Les fonctions graphiques du package guideR sont présentées dans le webin-R #26 (Graphiques statistiques avec guideR) sur YouTube