

Facteurs et vecteurs labellisés
Une version actualisée de ce chapitre est disponible sur guide-R : Facteurs et forcats, Étiquettes de variables, Étiquettes de valeurs & Valeurs manquantes
Ce chapitre est évoqué dans le webin-R #02 (les bases du langage R) sur YouTube.
Dans le chapire sur les vecteurs, nous avons abordé les types fondementaux de vecteurs (numériques, textuels, logiques). Mais il existe de nombreux autres classes de vecteurs afin de représenter des données diverses (comme les dates). Dans ce chapitre, nous nous intéressons plus particulièrement aux variables catégorielles.
Les facteurs (ou factors an anglais) sont un type de vecteur géré nativement par R et utilisés dans de nombreux domaines (modèles statistiques, représentations graphiques, …).
Les facteurs sont souvent mis en regard des données labellisées telles qu’elles sont utilisées dans d’autres logiciels comme SPSS ou Stata. Or, les limites propres aux facteurs font qu’ils ne sont pas adpatés pour rendre compte des différents usages qui sont fait des données labellisées. Plusieurs extensions (telles que memisc ou Hmisc) ont proposé leur propre solution qui, bien qu’elles apportaient un plus pour la gestion des données labellisées, ne permettaient pas que celles-ci soient utilisées en dehors de ces extensions ou des extensions compatibles. Nous aborderons ici une nouvelle classe de vecteurs, la classe labelled, introduite par l’extension haven (que nous aborderons dans le cadre de l’import de données) et qui peut être manipulée avec l’extension homonyme labelled.
Facteurs
Dans ce qui suit on travaillera sur le jeu de données tiré de l’enquête Histoire de vie, fourni avec l’extension questionr.
Jetons un œil à la liste des variables de d :
'data.frame': 2000 obs. of 20 variables:
$ id : int 1 2 3 4 5 6 7 8 9 10 ...
$ age : int 28 23 59 34 71 35 60 47 20 28 ...
$ sexe : Factor w/ 2 levels "Homme","Femme": 2 2 1 1 2 2 2 1 2 1 ...
$ nivetud : Factor w/ 8 levels "N'a jamais fait d'etudes",..: 8 NA 3 8 3 6 3 6 NA 7 ...
$ poids : num 2634 9738 3994 5732 4329 ...
$ occup : Factor w/ 7 levels "Exerce une profession",..: 1 3 1 1 4 1 6 1 3 1 ...
$ qualif : Factor w/ 7 levels "Ouvrier specialise",..: 6 NA 3 3 6 6 2 2 NA 7 ...
$ freres.soeurs: int 8 2 2 1 0 5 1 5 4 2 ...
$ clso : Factor w/ 3 levels "Oui","Non","Ne sait pas": 1 1 2 2 1 2 1 2 1 2 ...
$ relig : Factor w/ 6 levels "Pratiquant regulier",..: 4 4 4 3 1 4 3 4 3 2 ...
$ trav.imp : Factor w/ 4 levels "Le plus important",..: 4 NA 2 3 NA 1 NA 4 NA 3 ...
$ trav.satisf : Factor w/ 3 levels "Satisfaction",..: 2 NA 3 1 NA 3 NA 2 NA 1 ...
$ hard.rock : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 1 1 1 1 ...
$ lecture.bd : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 1 1 1 1 ...
$ peche.chasse : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 2 2 1 1 ...
$ cuisine : Factor w/ 2 levels "Non","Oui": 2 1 1 2 1 1 2 2 1 1 ...
$ bricol : Factor w/ 2 levels "Non","Oui": 1 1 1 2 1 1 1 2 1 1 ...
$ cinema : Factor w/ 2 levels "Non","Oui": 1 2 1 2 1 2 1 1 2 2 ...
$ sport : Factor w/ 2 levels "Non","Oui": 1 2 2 2 1 2 1 1 1 2 ...
$ heures.tv : num 0 1 0 2 3 2 2.9 1 2 2 ...Nous voyons que de nombreuses variables de ce tableau de données, telles que sexe ou nivetud, sont du type facteur.
Les facteurs prennent leurs valeurs dans un ensemble de modalités prédéfinies et ne peuvent en prendre d’autres. La liste des valeurs possibles est donnée par la fonction levels :
[1] "Homme" "Femme"Si on veut modifier la valeur du sexe du premier individu de notre tableau de données avec une valeur non autorisée, on obient un message d’erreur et une valeur manquante est utilisée à la place :
Warning in `[<-.factor`(`*tmp*`, 1, value = structure(c(NA,
2L, 1L, 1L, : niveau de facteur incorrect, NAs générés[1] <NA>
Levels: Homme Femme[1] Homme
Levels: Homme FemmeOn peut très facilement créer un facteur à partir d’une variable textuelle avec la fonction factor :
[1] H H F H
Levels: F HPar défaut, les niveaux d’un facteur nouvellement créés sont l’ensemble des valeurs de la variable textuelle, ordonnées par ordre alphabétique. Cette ordre des niveaux est utilisé à chaque fois qu’on utilise des fonctions comme table, par exemple :
v
F H
1 3 On peut modifier cet ordre au moment de la création du facteur en utilisant l’option levels :
v
H F
3 1 On peut aussi modifier l’ordre des niveaux d’une variable déjà existante :
d$qualif <- factor(d$qualif, levels = c(
"Ouvrier specialise", "Ouvrier qualifie",
"Employe", "Technicien", "Profession intermediaire", "Cadre", "Autre"
))
table(d$qualif)
Ouvrier specialise Ouvrier qualifie
203 292
Employe Technicien
594 86
Profession intermediaire Cadre
160 260
Autre
58 L’extension questionr propose une interface interactive pour le réordonnancement des niveaux d’un facteur. Cette fonction, nommée iorder, vous permet de réordonner les modalités de manière graphique et de générer le code R correspondant.
Dans l’exemple précédant, si vous exécutez :
RStudio devrait ouvrir une fenêtre semblable à celle de la figure ci-dessous.
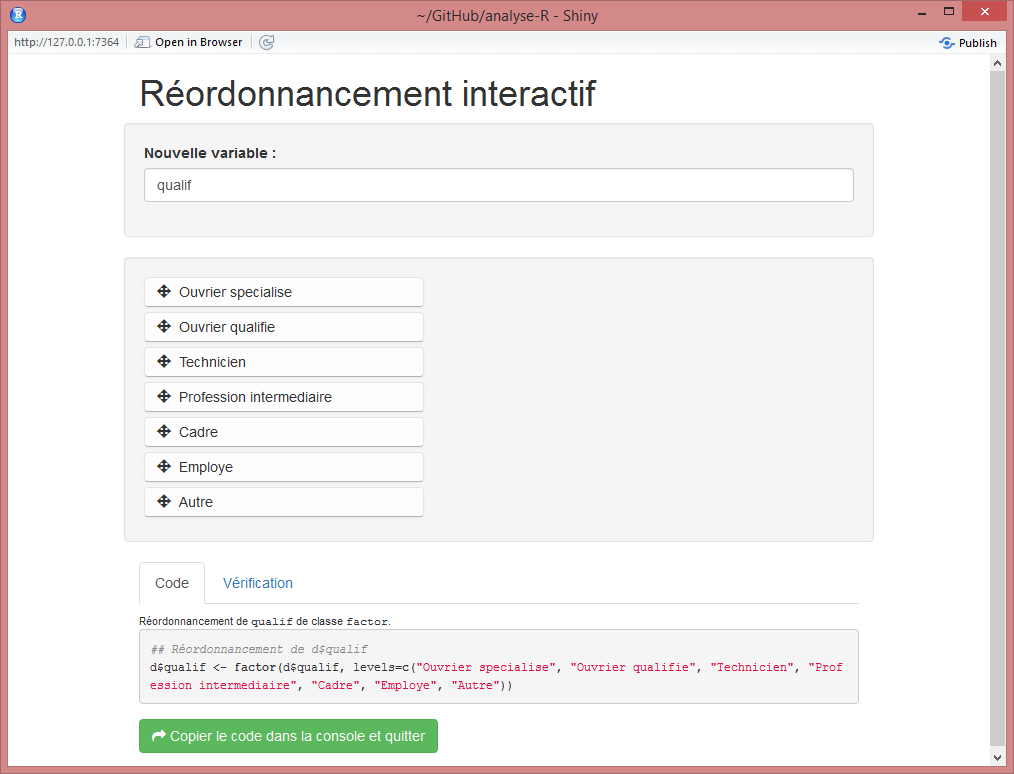
Vous pouvez alors déplacer les modalités par glisser-déposer, vérifier le résultat dans l’onglet Vérification et, une fois le résultat satisfaisant, récupérer le code généré pour l’inclure dans votre script.
On peut également modifier les niveaux eux-mêmes. Imaginons que l’on souhaite créer une nouvelle variable qualif.abr contenant les noms abrégés des catégories socioprofessionnelles de qualif. On peut alors procéder comme suit :
d$qualif.abr <- factor(d$qualif,
levels = c(
"Ouvrier specialise", "Ouvrier qualifie",
"Employe", "Technicien", "Profession intermediaire", "Cadre", "Autre"
),
labels = c("OS", "OQ", "Empl", "Tech", "Interm", "Cadre", "Autre")
)
table(d$qualif.abr)
OS OQ Empl Tech Interm Cadre Autre
203 292 594 86 160 260 58 Dans ce qui précède, le paramètre levels de factor permet de spécifier quels sont les niveaux retenus dans le facteur résultat, ainsi que leur ordre. Le paramètre labels, lui, permet de modifier les noms de ces niveaux dans le facteur résultat. Il est donc capital d’indiquer les noms de labels exactement dans le même ordre que les niveaux de levels. Pour s’assurer de ne pas avoir commis d’erreur, il est recommandé d’effectuer un tableau croisé entre l’ancien et le nouveau facteur :
OS OQ Empl Tech Interm Cadre
Ouvrier specialise 203 0 0 0 0 0
Ouvrier qualifie 0 292 0 0 0 0
Employe 0 0 594 0 0 0
Technicien 0 0 0 86 0 0
Profession intermediaire 0 0 0 0 160 0
Cadre 0 0 0 0 0 260
Autre 0 0 0 0 0 0
Autre
Ouvrier specialise 0
Ouvrier qualifie 0
Employe 0
Technicien 0
Profession intermediaire 0
Cadre 0
Autre 58On a donc ici un premier moyen d’effectuer un recodage des modalités d’une variable de type facteur. D’autres méthodes existent, que nous aborderons dans le chapitre Recodage.
À noter que par défaut, les valeurs manquantes ne sont pas considérées comme un niveau de facteur. On peut cependant les transformer en niveau en utilisant la fonction addNA. Ceci signifie cependant qu’elle ne seront plus considérées comme manquantes par R mais comme une modalité à part entière :
Satisfaction Insatisfaction Equilibre NA's
480 117 451 952 Satisfaction Insatisfaction Equilibre <NA>
480 117 451 952 La fonction addNAstr de l’extension questionr fait la même chose mais permet de spécifier l’étiquette de la modalité des valeurs manquantes.
Satisfaction Insatisfaction Equilibre Manquant
480 117 451 952 Vecteurs labellisés
Nous abordons ici une nouvelle classe de vecteurs, la classe haven_labelled, introduite récemment par l’extension haven (que nous aborderons dans le cadre de l’import de données) et qui peut être manipulée avec l’extension homonyme labelled.
Pour cette section, nous allons utiliser d’autres données d’exemple, également disponibles dans l’extension questionr. Il s’agit d’un ensemble de trois tableaux de données (menages, femmes et enfants) contenant les données d’une enquête de fécondité. Commençons par les charger en mémoire :
Pour ailleurs, nous allons avoir besoin de l’extension labelled qui permet de manipuler ces données labellisées.
Les étiquettes de variable
Les étiquettes de variable permettent de donner un nom long, plus explicite, aux différentes colonnes d’un tableau de données (ou encore directement à un vecteur autonome).
La visonneuse de données de RStudio sait reconnaître et afficher ces étiquettes de variable lorsqu’elles existent. Essayez par exemple la commande suivante :
Les fonctions look_for de l’extension laballed et describe de l’extension questionr affichent également les étiquettes de variables lorsqu’elles existent.
pos variable label col_type values
<chr> <chr> <chr> <chr> <chr>
7 milieu Milieu de résidence dbl+lbl [1] urbain
[2] rural
8 region Région de résidence dbl+lbl [1] Nord
[2] Est
[3] Sud
[4] Ouest[2000 obs.] Identifiant de l'enquêtée
numeric: 391 1643 85 881 1981 1072 1978 1607 738 1656 ...
min: 1 - max: 2000 - NAs: 0 (0%) - 2000 unique valuesPour manipuler les étiquettes de variable, il suffit d’utiliser la fonction var_label de l’extension labelled.
[1] "Identifiant du ménage"[1] "ID du ménage auquel elle appartient"On utilisera la valeur NULL pour supprimer une étiquette :
NULL[1] "Ma variable"NULL[1] "Une autre étiquette"Le fait d’ajouter une étiquette à un vecteur ne modifie en rien son type. Regardons la structure de notre objet v :
num [1:5] 1 5 2 4 1
- attr(*, "label")= chr "Une autre étiquette"Que voit-on ? Notre vecteur possède maintenant ce qu’on appelle un attribut, c’est-à-dire une information supplémentaire qui lui est attachée. Un objet peut avoir plusieurs attributs. Ici, notre étiquette de variable est strocké dans un attribut nommé "label". Cela ne modifie en rien sa nature. Il ne s’agit que d’information en plus. Toutes les fonctions ne tiennent pas compte des étiquettes de variable. Peu importe ! La présence d’un attribut ne les empêchera de fonctionner. De même, même si l’extension labelled n’est pas installée sur votre machine, vous pourrez toujours manipuler vos données comme si de rien n’était.
On peut associer une étiquette de variable à n’importe quel type de variable, qu’elle soit numérique, textuelle, un facteur ou encore des dates.
Les étiquettes de valeur
Les étiquettes de valeur consistent à attribuer une étiquette textuelle à certaines valeurs d’un vecteur. Elles ne peuvent s’appliquer qu’aux vecteurs numériques ou textuels.
Lorsqu’un vecteur possède des étiquettes de valeur, sa classe change et devient labelled. Regardons déjà quelques exemples. Tout d’abord, jetons un apercu au contenu de l’objet femmes grace à la fonction glimpse de l’extension dplyr.
Rows: 2,000
Columns: 17
$ id_femme <dbl> 391, 1643, 85, 881, 1981, 1072, 197…
$ id_menage <dbl> 381, 1515, 85, 844, 1797, 1015, 179…
$ poids <dbl> 1.803150, 1.803150, 1.803150, 1.803…
$ date_entretien <date> 2012-05-05, 2012-01-23, 2012-01-21…
$ date_naissance <date> 1997-03-07, 1982-01-06, 1979-01-01…
$ age <dbl> 15, 30, 33, 43, 25, 18, 45, 23, 49,…
$ milieu <dbl+lbl> 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2…
$ region <dbl+lbl> 4, 4, 4, 4, 4, 3, 3, 3, 3, 3, 3…
$ educ <dbl+lbl> 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0…
$ travail <hvn_lbl_> 1, 1, 0, 1, 1, 0, 1, 0, 1, 1, …
$ matri <dbl+lbl> 0, 2, 2, 2, 1, 0, 1, 1, 2, 5, 2…
$ religion <dbl+lbl> 1, 3, 2, 3, 2, 2, 3, 1, 3, 3, 2…
$ journal <dbl+lbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
$ radio <dbl+lbl> 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1…
$ tv <dbl+lbl> 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1…
$ nb_enf_ideal <hvn_lbl_> 4, 4, 4, 4, 4, 5, 10, 5…
$ test <hvn_lbl_> 0, 9, 0, 0, 1, 0, 0, 0, 0, 1, …Il apparaît que la variable region est de type haven_labelled. On peut le confirmer avec class.
[1] "haven_labelled" "vctrs_vctr" "double" Regardons les premières valeurs prises par cette variable.
<labelled<double>[6]>: Région de résidence
[1] 4 4 4 4 4 3
Labels:
value label
1 Nord
2 Est
3 Sud
4 OuestNous voyons que quatre étiquettes de valeurs ont été associées à notre variable. Le code 1 correspond ainsi à la région Nord
, le code 2 à la région Est
, etc. Laissons de côté pour le moment la colonne is_na que nous aborderons dans une prochaine section.
La liste des étiquettes est également renvoyée par la fonction describe de questionr.
[2000 obs.] Région de résidence
labelled double: 4 4 4 4 4 3 3 3 3 3 ...
min: 1 - max: 4 - NAs: 0 (0%) - 4 unique values
4 value labels: [1] Nord [2] Est [3] Sud [4] Ouest
n %
[1] Nord 707 35.4
[2] Est 324 16.2
[3] Sud 407 20.3
[4] Ouest 562 28.1
Total 2000 100.0L’extension labelled fournit la fonction val_labels qui renvoie la liste des étiquettes de valeurs d’une variable sous la forme d’un vecteur nommé et la fonction val_label (notez l’absence de ‘s’) qui renvoie l’étiquette associée à une valeur particulière. S’il n’y a pas d’étiquette de valeur, ces fonctions renvoient NULL.
Nord Est Sud Ouest
1 2 3 4 [1] "Est"NULLNULLRe-regardons d’un peu plus près les premières valeurs de notre variable region.
<labelled<double>[6]>: Région de résidence
[1] 4 4 4 4 4 3
Labels:
value label
1 Nord
2 Est
3 Sud
4 OuestOn s’aperçoit qu’il s’agit de valeurs numériques. Et l’affichage indique que notre variable est plus précisément du type labelled double. Pour rappel, double est synonyme de numeric. Autrement dit, la classe haven_labelled ne modifie pas le type sous-jacent d’un vecteur, que l’on peut toujours obtenir avec la fonction typeof. Nous pouvons également tester si notre variable est numérique avec la fonction is.numeric.
[1] "double"[1] TRUEÀ la différence des facteurs, le type original d’une variable labellisée n’est pas modifié par la présence d’étiquettes de valeur. Ainsi, il reste possible de calculer une moyenne à partir de notre variable region (même si cela n’est pas pertinent ici d’un point de vue sémantique).
[1] 2.412Avec un facteur, nous aurions eu un bon message d’erreur.
Warning in mean.default(d$nivetud): l'argument n'est ni
numérique, ni logique : renvoi de NA[1] NANous allons voir qu’il est aussi possible d’associer des étiquettes de valeurs à des vecteurs textuels. Créons tout d’abord un vecteur textuel qui nous servira d’exemple.
[1] "f" "f" "h" "f" "h"Le plus facile pour lui associer des étiquettes de valeur est d’utiliser val_label.
<labelled<character>[5]>
[1] f f h f h
Labels:
value label
f femmes
h hommes[1] "character"Notre vecteur v a automatiquement été transformé en un vecteur de la classe labelled. Mais son type sous-jacent est resté "character". Par ailleurs, les données elle-même n’ont pas été modifiées et ont conservé leurs valeurs originales.
Il est également possible de définir/modifier/supprimer l’ensemble des étiquettes de valeur d’une variable avec val_labels en lui assignant un vecteur nommé.
<labelled<character>[5]>
[1] f f h f h
Labels:
value label
h Homme
f Femme
i Valeur indéterminéeComme précédemment, on utilisera NULL pour supprimer une ou toutes les étiquettes.
<labelled<character>[5]>
[1] f f h f h
Labels:
value label
h Homme
f Femme[1] "f" "f" "h" "f" "h"[1] "character"Si l’on supprime toutes les étiquettes de valeur, alors notre vecteur retrouve sa classe initiale.
Assignation et condition
Les étiquettes de valeur sont plus souples que les facteurs, en ce sens qu’il n’est pas obligatoire d’indiquer une étiquette pour chaque valeur prise par une variable. Alors qu’il n’est pas possible avec un facteur d’assigner une valeur qui n’a pas été préalablement définie comme une des modalités possibles du facteur, nous n’avons pas cette limite avec les vecteurs labellisés.
Important : quand on assigne une valeur à un facteur, on doit transmettre le texte correspondant à la modalité, alors que pour un vecteur labellisé on transmettra le code sous-jacent (pour rappel, les étiquettes de valeur ne sont qu’une information additionnelle).
De plus, nous avons vu que les données initiales n’étaient pas modifiées par l’ajout ou la suppression d’étiquettes de valeur, alors que pour les facteurs ce n’est pas vrai. Pour mieux comprendre, essayons la commande suivante :
[1] 1 1 2 1 2
attr(,"levels")
[1] "f" "h"Un facteur stocke de manière interne les valeurs sous la forme d’une suite d’entiers, démarrant toujours par 1, forcément consécutifs, et dont les valeurs dépendent de l’ordre des facteurs. Pour s’en rendre compte :
[1] 2 2 1 2 1
attr(,"levels")
[1] "h" "f"[1] 1 1 2 1 2
attr(,"levels")
[1] "f" "h"Ce qui importe pour un facteur ce sont les modalités de ce dernier tandis que pour un vecteur labellisé ce sont les valeurs du vecteur elles-mêmes. Cela reste vrai pour l’écriture de conditions.
Prenons un premier exemple avec un facteur :
[2000 obs.]
nominal factor: "Homme" "Femme" "Homme" "Homme" "Femme" "Femme" "Femme" "Homme" "Femme" "Homme" ...
2 levels: Homme | Femme
NAs: 0 (0%)
n %
Homme 900 45
Femme 1100 55
Total 2000 100
FALSE TRUE
1100 900
FALSE
2000 La condition valide est celle utilisant "Homme" qui est la valeur de la modalité du facteur.
Et avec un vecteur labellisé ?
[2000 obs.] Milieu de résidence
labelled double: 2 2 2 2 2 2 2 2 2 2 ...
min: 1 - max: 2 - NAs: 0 (0%) - 2 unique values
2 value labels: [1] urbain [2] rural
n %
[1] urbain 912 45.6
[2] rural 1088 54.4
Total 2000 100.0Erreur : Can't combine `..1` <character> and `..2` <double>.
FALSE TRUE
1088 912 Ici, pour être valide, la condition doit porter sur les valeurs de la variable elle-même et non sur les étiquette.
Quelques fonctions supplémentaires
L’extension labelled fournit quelques fonctions supplémentaires qui peuvent s’avérer utiles :
labelledpour créer directement des vecteurs labellisés ;nolabel_to_napour convertir les valeurs n’ayant pas d’étiquette enNA;val_labels_to_naqui, à l’inverse, converti les valeurs avec étiquette enNA;sort_val_labelspour trier l’ordre des étiquettes de valeurs.
On pourra se réferrer à l’aide de chacune de ces fonctions.
L’import de données labellisées et le recodage de variables (dont la conversion d’un vecteur labellisé en facteur) seront quant à eux abordés dans les prochains chapitres.