

Exemples de graphiques avancés
Ce chapitre est évoqué dans le webin-R #13 (exemples de graphiques avancés) sur YouTube.
Ce chapitre est évoqué dans le webin-R #14 (exemples de graphiques avancés - 2) sur YouTube.
Dans ce chapitre, nous présentons plusieurs graphiques avec une mise en forme avancée et détaillons pas à pas leur création.
Chargeons quelques extensions de base.
Questions de connaissance
Pour ce premier exemple, supposons que nous avons réalisé une petite enquête auprès de 500 étudiants pour mesurer leur connaissance du logiciel R. Commençons par charger les données ici purement fictionnelles).
Nous avons maintenant un objet quest en mémoire. Regardons rapidement la forme des données.
Rows: 500
Columns: 15
$ id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13…
$ conn_a <fct> non, non, non, non, NA, non, non, non, no…
$ conn_b <fct> oui, oui, oui, oui, oui, oui, oui, oui, o…
$ conn_c <fct> oui, oui, oui, oui, oui, oui, oui, oui, o…
$ conn_d <fct> non, non, non, NA, NA, NA, NA, NA, non, o…
$ conn_e <fct> oui, oui, oui, oui, NA, oui, oui, oui, NA…
$ conn_f <fct> oui, non, oui, NA, NA, oui, oui, oui, oui…
$ conn_g <fct> non, oui, oui, oui, oui, oui, oui, oui, o…
$ source_a <fct> oui, oui, oui, oui, oui, oui, oui, oui, n…
$ source_b <fct> oui, non, non, non, non, oui, non, oui, n…
$ source_c <fct> oui, non, oui, oui, non, non, non, non, n…
$ source_d <fct> oui, non, non, oui, non, oui, oui, oui, o…
$ source_e <fct> oui, non, non, oui, oui, non, oui, non, o…
$ source_f <fct> non, non, non, non, non, non, non, non, n…
$ source_g <fct> non, non, non, non, non, non, non, non, n… oui non NSP NA's
36 442 1 21 Sept affirmations ont été soumises aux étudiants (variables conn_a à conn_g) et il leur a été demandé, pour chacune, s’il pensait qu’elle était juste. Les réponses possibles étaient “oui”, “non” et “NSP” (ne sait pas).
missing %
conn_d 104 21
conn_a 21 4
conn_e 17 3
conn_g 12 2
conn_f 10 2
id 0 0
conn_b 0 0
conn_c 0 0
source_a 0 0
source_b 0 0
source_c 0 0
source_d 0 0
source_e 0 0
source_f 0 0
source_g 0 0On peut également noter que pour certaines questions il y a plusieurs valeurs manquantes (jusqu’à 104).
Nous souhaiterions représenter les réponses sous la forme d’un graphique en barres cumulées. Cependant, un tel graphique ne peut pour le moment être réalisé car les réponses sont stockées dans 7 variables différentes. Pour réaliser le graphique, il nous faut un tableau de données avec une colonne qui contiendrait le nom de la question et une colonne avec les réponses. Cela peut se faire facilement avec la fonction pivot_longer de l’extension tidyr (voir le chapitre dédié).
conn <- quest %>%
select(starts_with("conn_")) %>%
pivot_longer(
cols = starts_with("conn_"),
names_to = "question",
values_to = "reponse"
)
glimpse(conn)Rows: 3,500
Columns: 2
$ question <chr> "conn_a", "conn_b", "conn_c", "conn_d", "…
$ reponse <fct> non, oui, oui, non, oui, oui, non, non, o…Nous pouvons maintenant réaliser une première ébauche avec geom_bar et position = "fill".
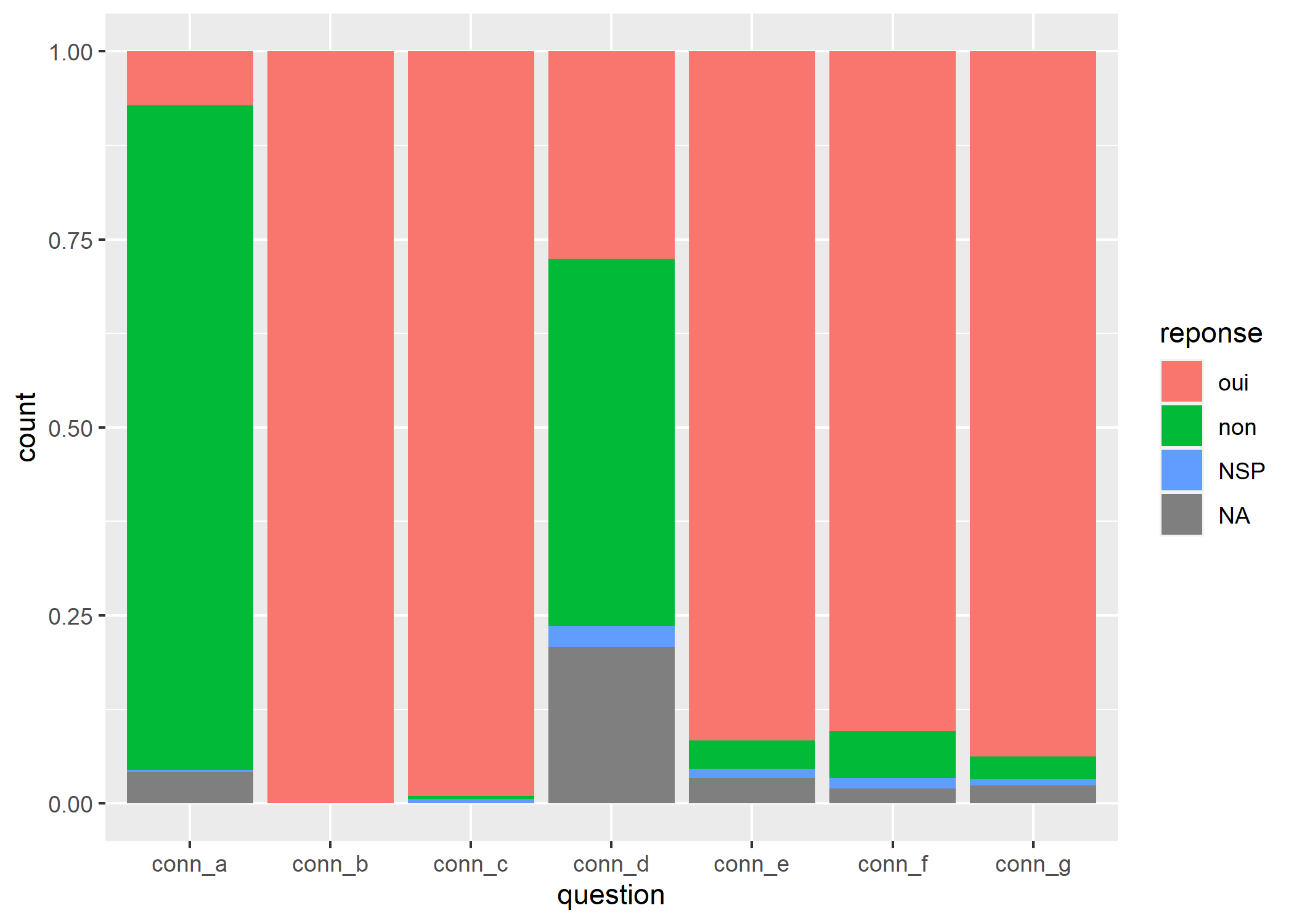 Pour simplifier le graphique, nous allons regrouper les manquants avec les NSP avec
Pour simplifier le graphique, nous allons regrouper les manquants avec les NSP avec fct_explicit_na, changer l’ordre des modalités en mettant les NSP entre les oui et les non avec fct_relevel et remplacer “NSP” par sa version longue avec fct_recode. En effet, il est toujours préférable, pour la lisibilité du graphique, d’éviter un acronyme lorsque ce n’est pas nécessaire.
Nous allons également en profiter pour déplacer la légende sous le graphique avec l’option legend.position = "bottom" passée à theme.
conn$reponse <- conn$reponse %>%
fct_explicit_na("NSP") %>%
fct_relevel("non", "NSP", "oui") %>%
fct_recode("ne sait pas / manquant" = "NSP")Warning: `fct_explicit_na()` was deprecated in forcats 1.0.0.
ℹ Please use `fct_na_value_to_level()` instead.ggplot(conn) +
aes(x = question, fill = reponse) +
geom_bar(position = "fill") +
theme(legend.position = "bottom")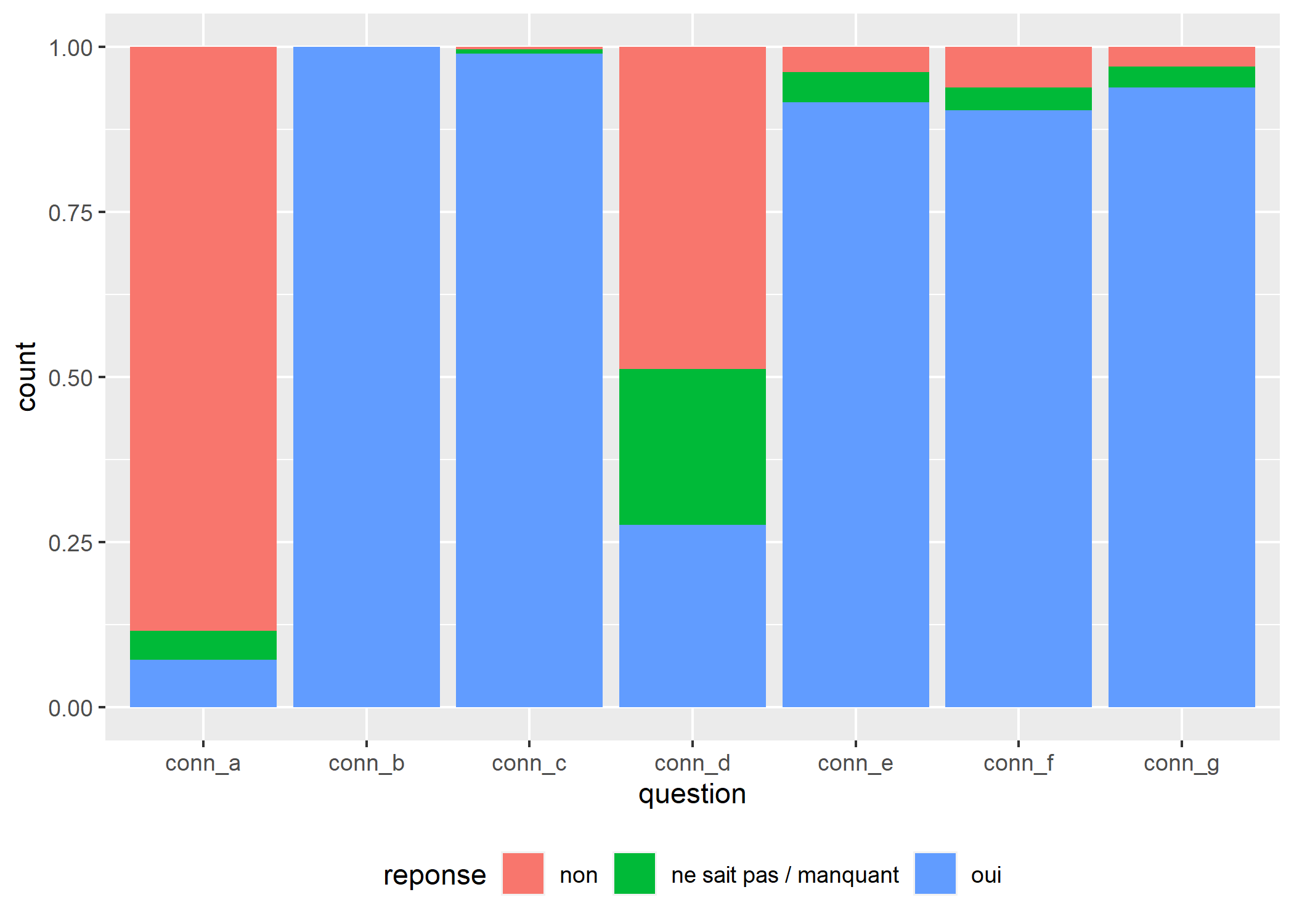
Votre lectorat ne sait probablement pas à quoi correspond les variables conn_a à conn_g. Il est donc préférable de les remplacer par des étiquettes plus explicites. Souvent, on a tendance à vouloir mettre des étiquettes courtes, quitte à reformuler le questionnaire d’origine. Ceci dit, il est pourtant préférable d’utiliser, quand cela est possible et pertinent, la formulation exacte du questionnaire. Ici nous allons créer une nouvelle variable etiquette et nous allons mettre à jour la définition de l’axe des x dans aes.
conn$etiquette <- conn$question %>%
fct_recode(
"R est disponible seulement pour Windows" = "conn_a",
"R possède un puissant moteur graphique" = "conn_b",
"Il est possible de réaliser des modèles mixtes avec R" = "conn_c",
"Le package 'foreign' est le seul permettant d'importer des fichiers de données SPSS" = "conn_d",
"Il n'est pas possible de produire un rapport PDF avec R" = "conn_e",
"R peut gérer des données d'enquêtes avec un plan d'échantillonnage complexe" = "conn_f",
"R est utilisée par des scientifiques de toutes disciplines, y compris des sciences sociales" = "conn_g"
)
ggplot(conn) +
aes(x = etiquette, fill = reponse) +
geom_bar(position = "fill") +
theme(legend.position = "bottom")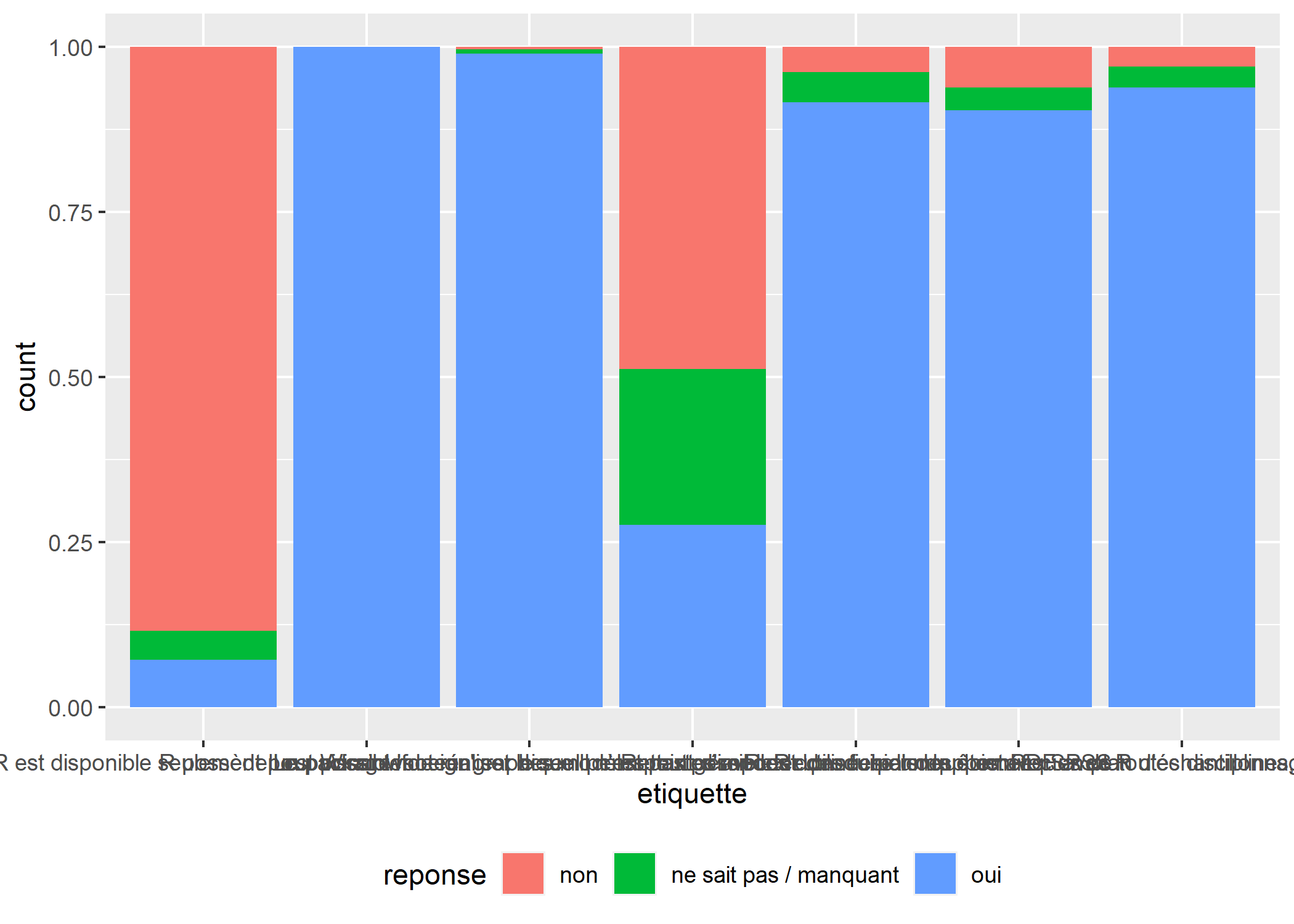
Malheureusement, avec un graphique en barres verticales, les étiquettes de l’axe des X sont tout bonnement illisibles. Mais nous pouvons facilement transformer notre graphique en barres horizontales avec coord_flip. Une autre solution consiste à appliquer une rotation de 90 degrés aux étiquettes de l’axe des x, mais cette approche est moins lisible que le passage à des barres horizontales.
ggplot(conn) +
aes(x = etiquette, fill = reponse) +
geom_bar(position = "fill") +
coord_flip() +
theme(legend.position = "bottom")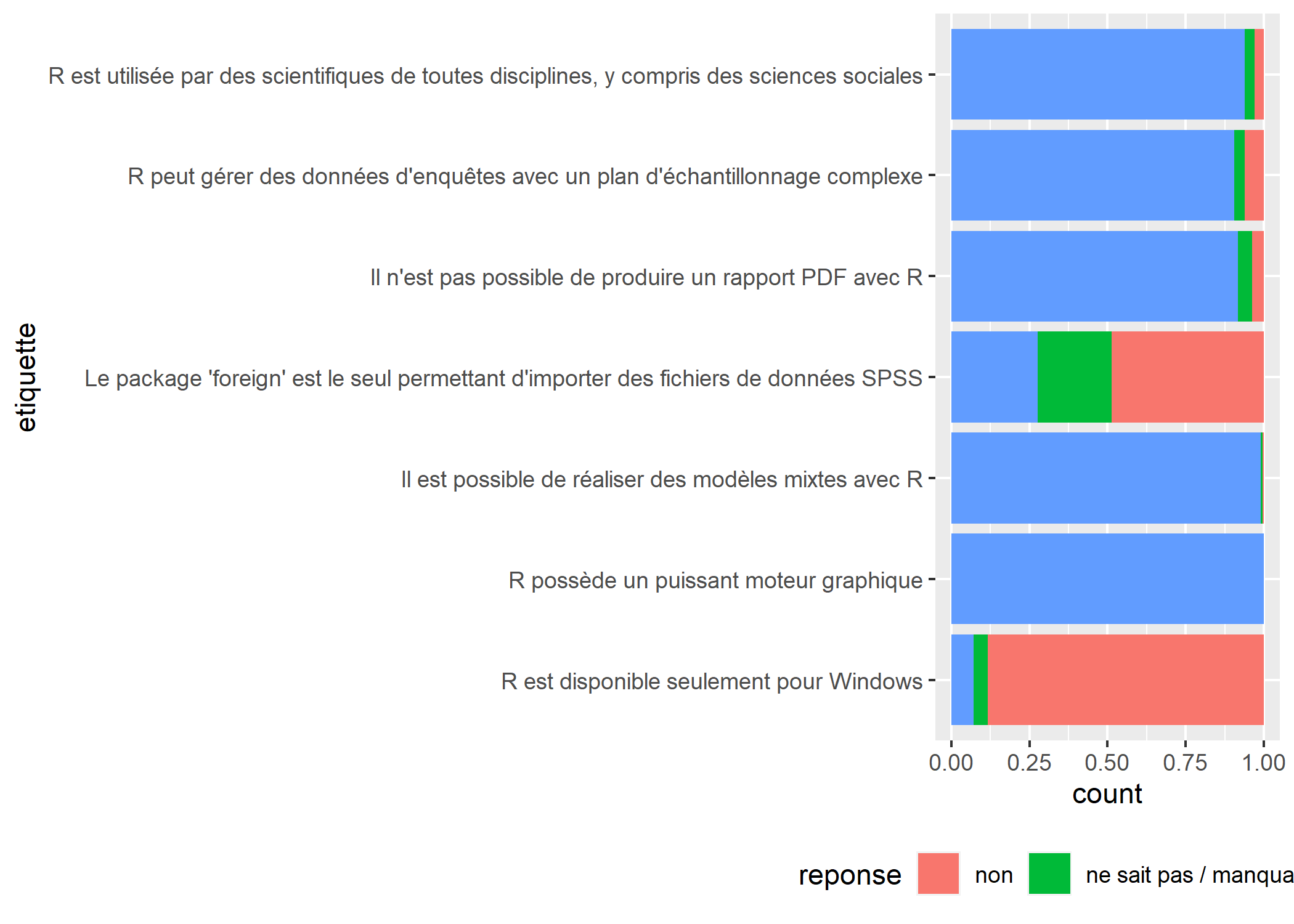
C’est déjà mieux. Cependant, comme certaines étiquettes sont très longues, l’espace restant pour le graphique est réduit. Nous allons donc afficher ces étiquettes trop longues sur plusieurs lignes, grace à la fonction label_wrap de l’extension scales que nous allons appeler à l’intérieur de scale_x_discrete. Le nombre passé à label_wrap indique le nombre de caractères à afficher avant retour à la ligne.
Nous allons également faire deux petites améliorations à notre graphique : (i) nous allons réduire l’épaisseur des barres en ajoutant width = .66 à geom_bar ; (ii) nous allons éviter que l’axe des y (devenu l’axe horizontal) se soit étendu grâce à la commande scale_y_continuous(expand = c(0, 0)).
ggplot(conn) +
aes(x = etiquette, fill = reponse) +
geom_bar(position = "fill", width = .66) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
coord_flip() +
theme(legend.position = "bottom")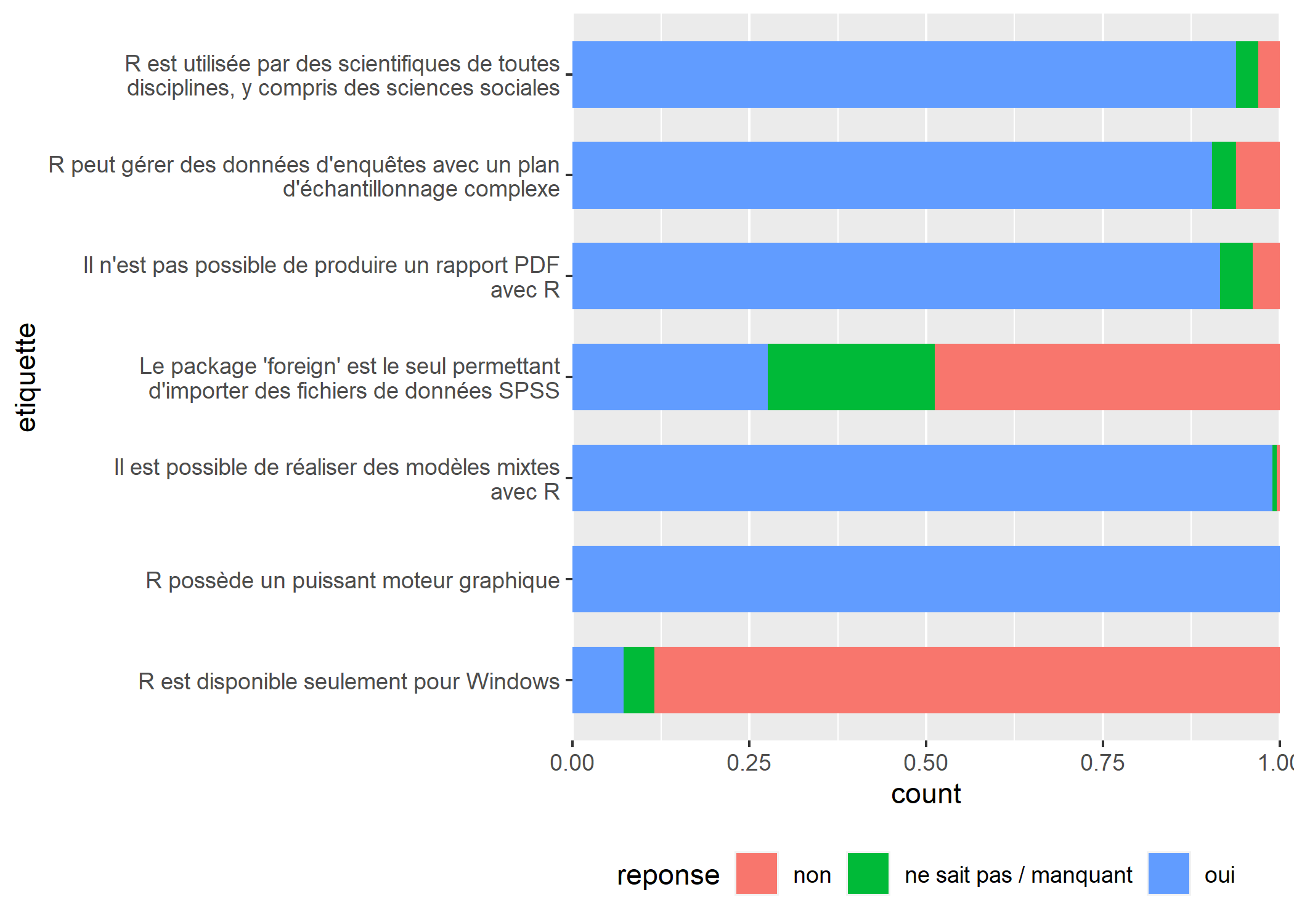 Pour améliorer la lisibilité du graphique, nous allons ajouter des étiquettes avec les pourcentages calculés (voir le chapitre sur les graphiques bivariés). Pour cela, nous aurons besoin de l’extension
Pour améliorer la lisibilité du graphique, nous allons ajouter des étiquettes avec les pourcentages calculés (voir le chapitre sur les graphiques bivariés). Pour cela, nous aurons besoin de l’extension GGally qui fournie la statistique stat_prop.
Nous allons donc appeler geom_text avec cette statistique. Dans l’appel à aes, nous devons ajouter by = etiquette pour indiquer que nous voulons que nos pourcentages soit calculés pour chaque valeur de la variable etiquette. Dans l’appel à geom_text, nous allons préciser position = position_fill(.5) pour que nos étiquettes soit positionnées au milieu des rectangles. colour = "white" permet de préciser la couleur des étiquettes, fontface = "bold" pour les afficher en gras et size = 3.5 pour contrôler leur taille.
library(GGally)
ggplot(conn) +
aes(x = etiquette, fill = reponse, by = etiquette) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
coord_flip() +
theme(legend.position = "bottom")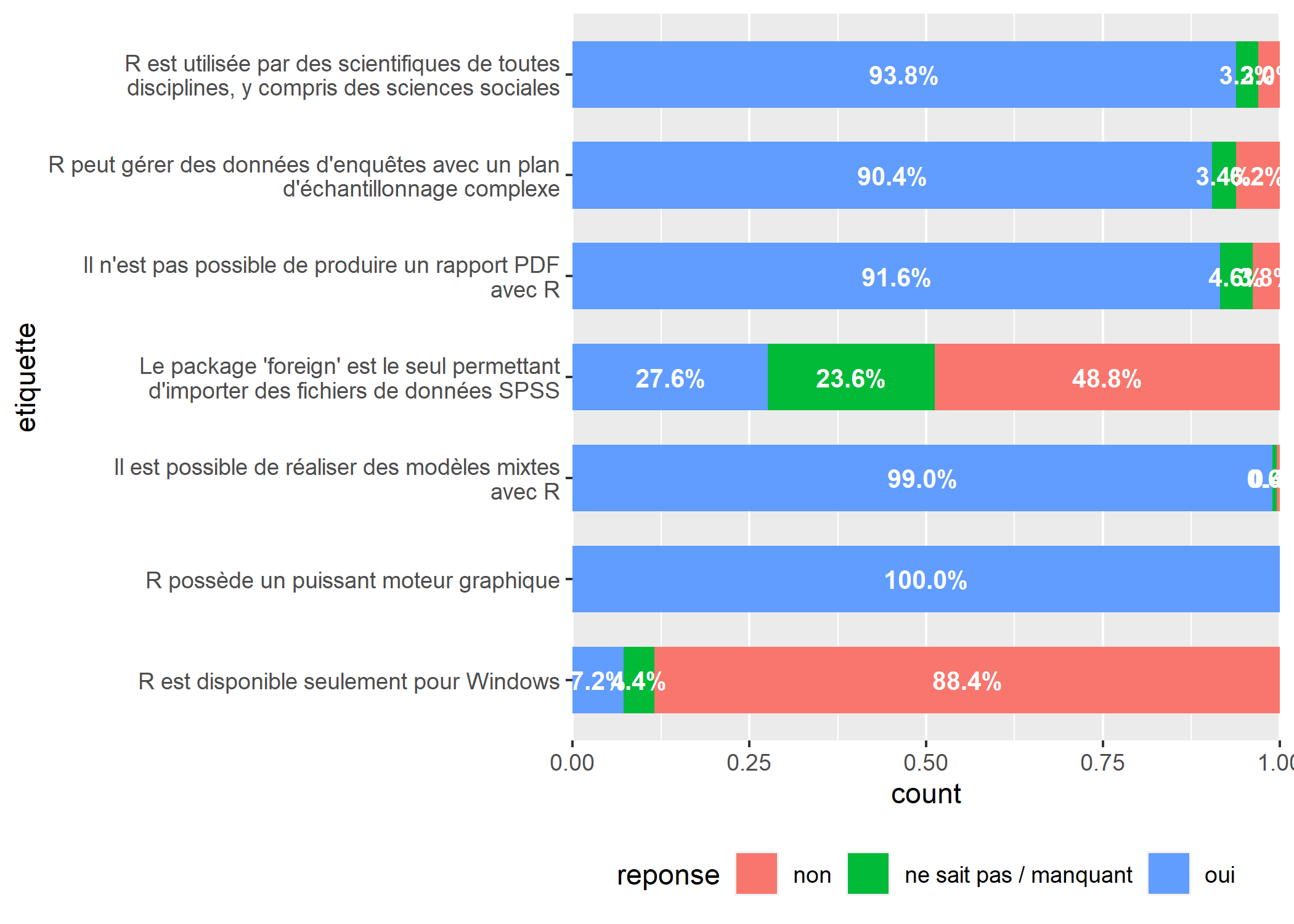
Les résultat est encourageant mais certaines étiquettes sont pas ou peu lisibles. Tout d’abord, nous n’allons pas afficher de décimale car c’est une précision inutile. Pour cela, nous allons utiliser la fonction percent de scales qui permet de mettre en forme des pourcentages. Nous allons préciser accuracy = 1 pour indiquer que nous souhaitons arrondir à l’unité (pour une précision de deux décimales, nous aurions donc indiqué accuracy = .01).
De plus, pour les valeurs inférieures à 5% nous allons masquer le symbole % et pour les valeurs inférieures à 1% nous n’allons rien afficher. L’astuce consiste à créer une petite fonction personnalisée, que nous allons appeler f et qui va s’occuper de la mise en forme. Puis, dans aes, l’esthétique label sera définie comme égale à f(after_stat(prop)) (note : after_stat permet d’appeler la variable prop calculée par stat_prop).
f <- function(x) {
res <- scales::percent(x, accuracy = 1)
res[x < .05] <- scales::percent(x[x < .05], accuracy = 1, suffix = "")
res[x < .01] <- ""
res
}
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
coord_flip() +
theme(legend.position = "bottom")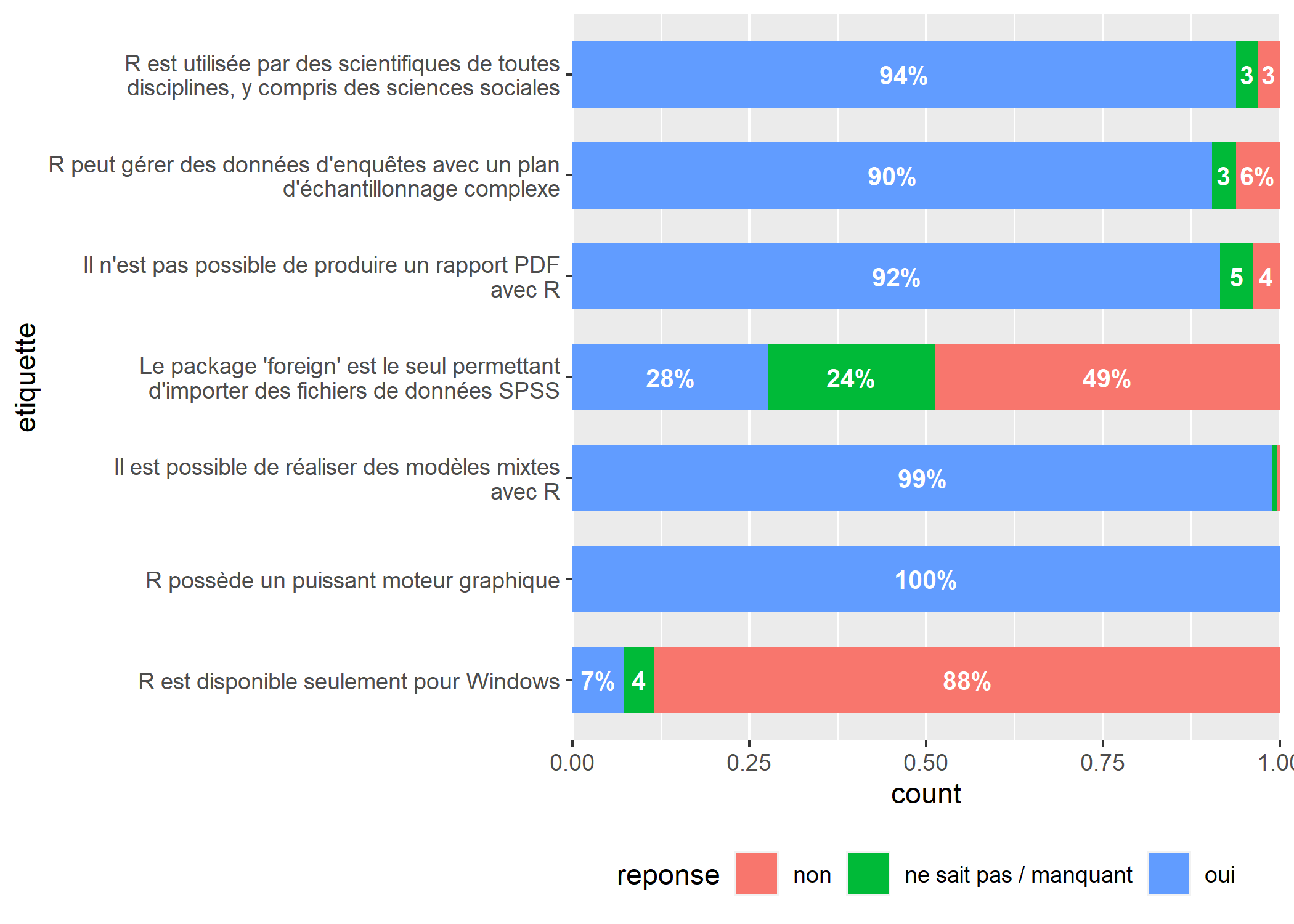
Nous commencons à avoir tous les éléments de notre graphique. Il est temps de faire un peu de nettoyage. Appliquons déjà theme_minimal pour alléger le graphique et supprimer les titres des axes et de la légende avec labs.
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
coord_flip() +
labs(x = "", y = "", fill = "") +
theme_minimal() +
theme(legend.position = "bottom")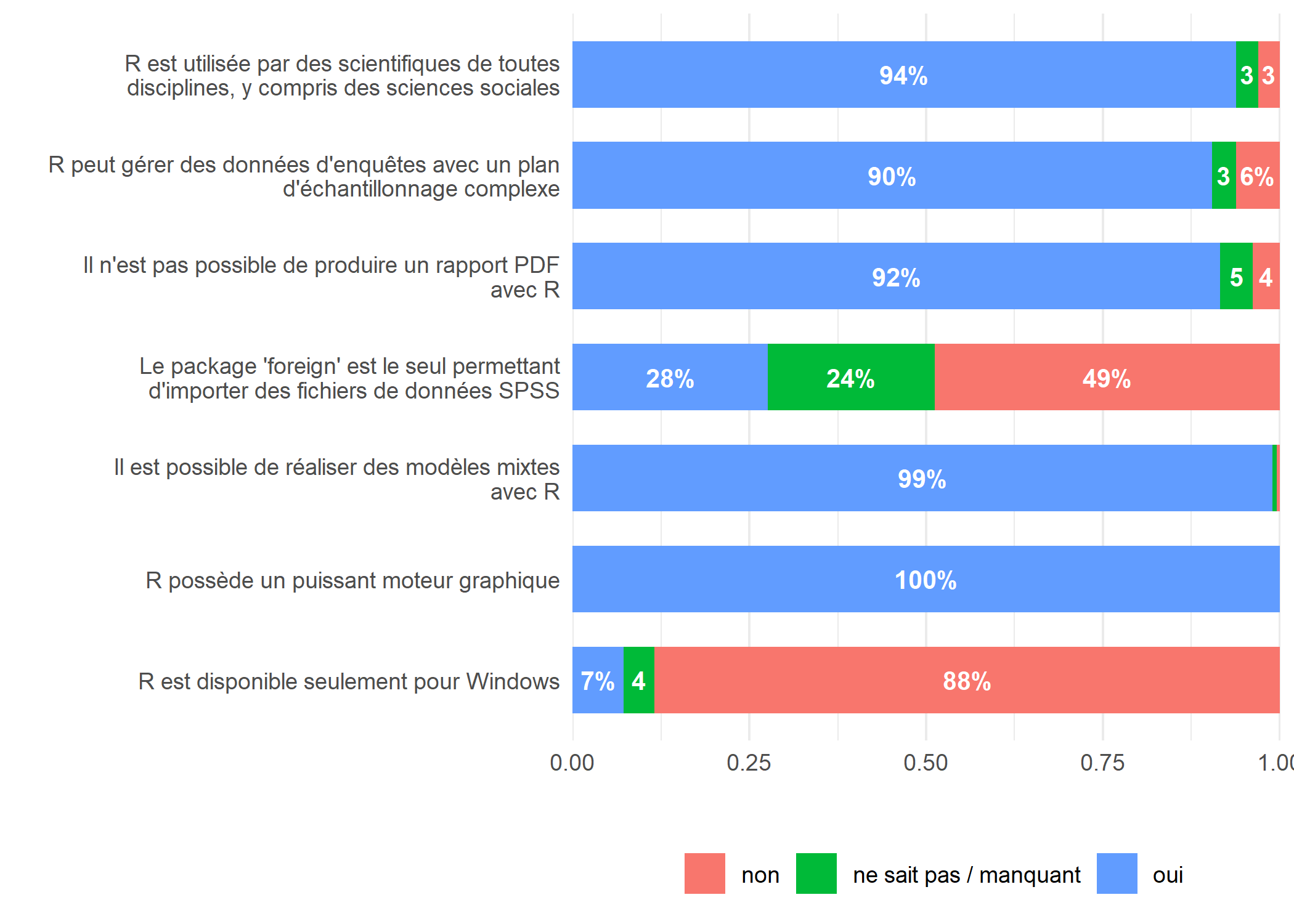
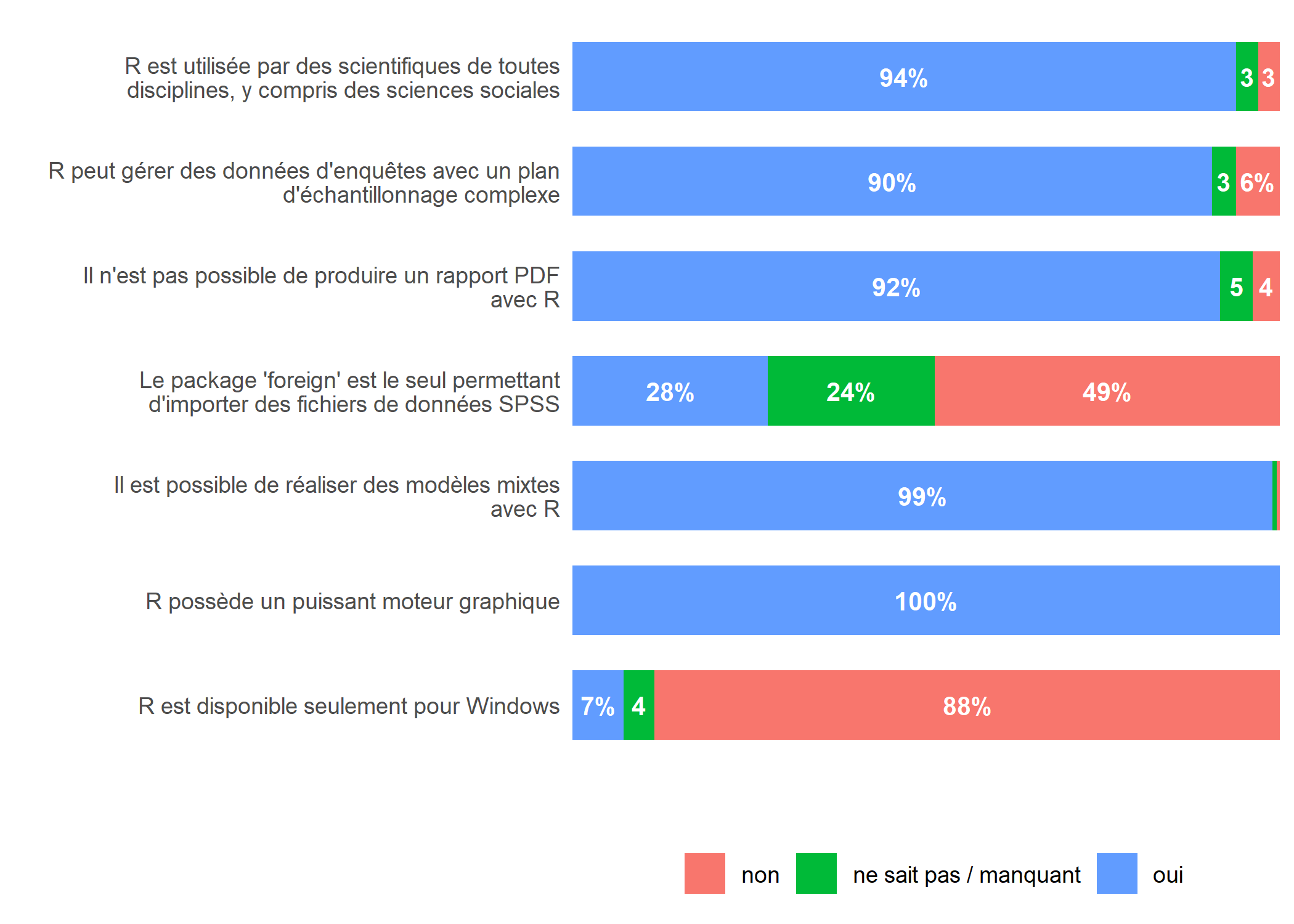
Comme les valeurs sont directement affichées sur le graphique, il est encore possible de l’alléger en supprimant la grille (avec panel.grid = element_blank()) et les étiquettes de l’axe horizontal (avec axis.text.x = element_blank()) via la fonction theme.
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
coord_flip() +
labs(x = "", y = "", fill = "") +
theme_minimal() +
theme(
legend.position = "bottom",
panel.grid = element_blank(),
axis.text.x = element_blank()
)
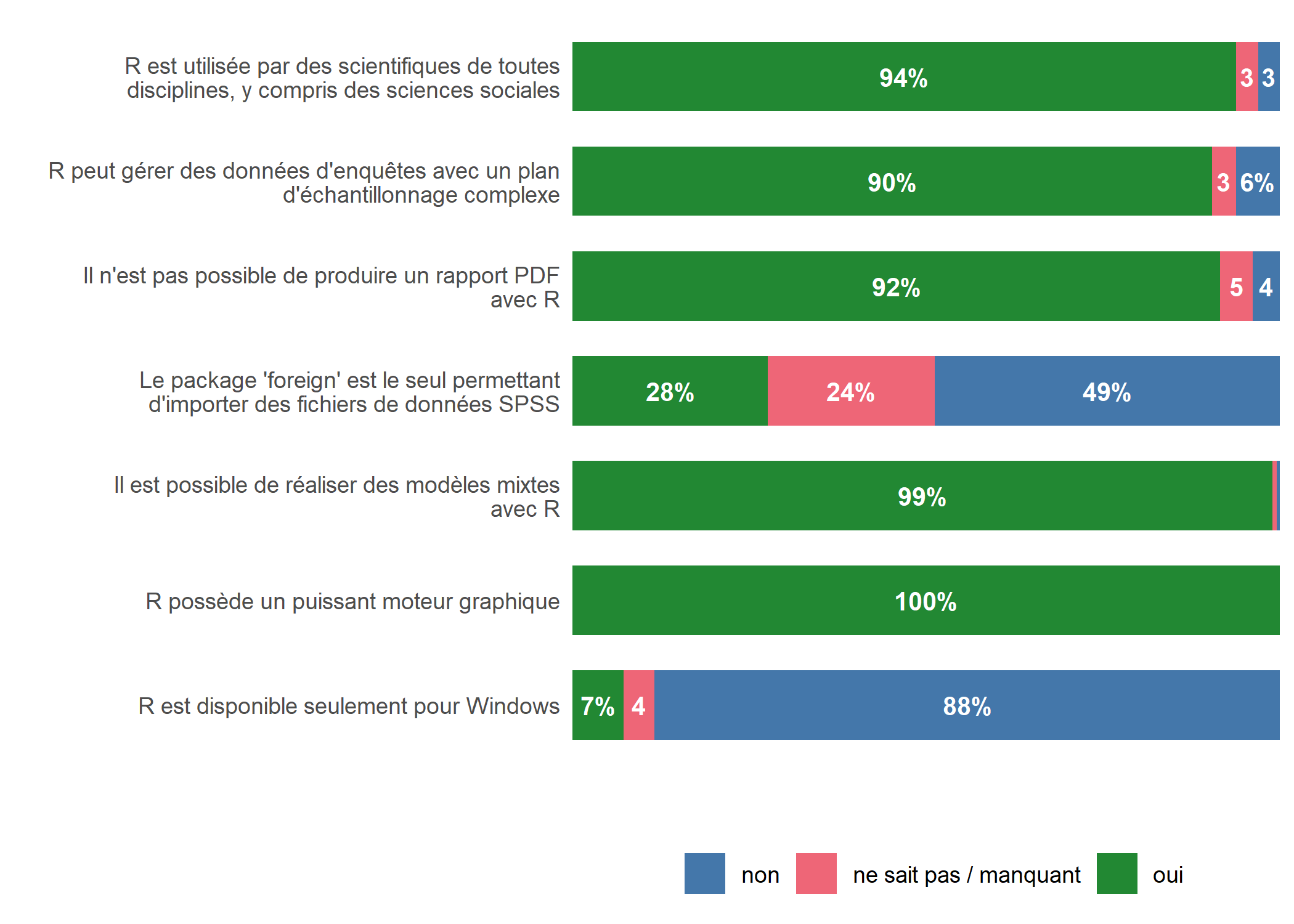
Nous allons également personnaliser la palette de couleur pour adopter une palette adaptée aux personnes daltoniennes. Il en existe plusieurs, dont celles développées par Paul Tol et disponibles dans l’extension khroma (voir aussi le chapitre sur les palettes de couleurs). On peut appliquer cette palette avec scale_fill_bright.
library(khroma)
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
scale_fill_bright() +
coord_flip() +
labs(x = "", y = "", fill = "") +
theme_minimal() +
theme(
legend.position = "bottom",
panel.grid = element_blank(),
axis.text.x = element_blank()
)
Cependant, ce choix de couleur n’est peut-être pas optimal. Une couleur neutre (proche du gris) serait peut être plus appropriée pour les “ne sait pas / manquant”. Regardons les codes couleurs de la palette bright.
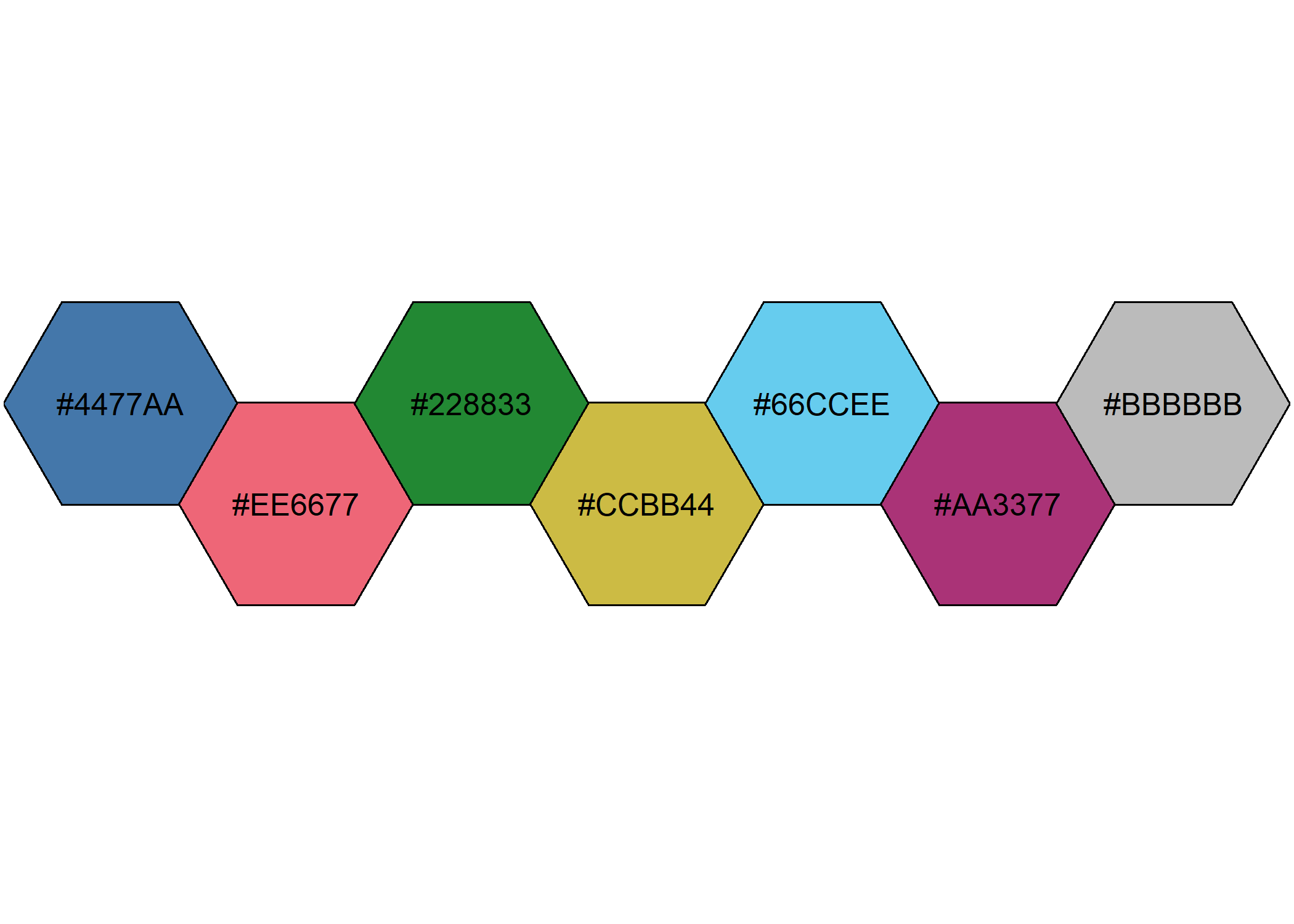
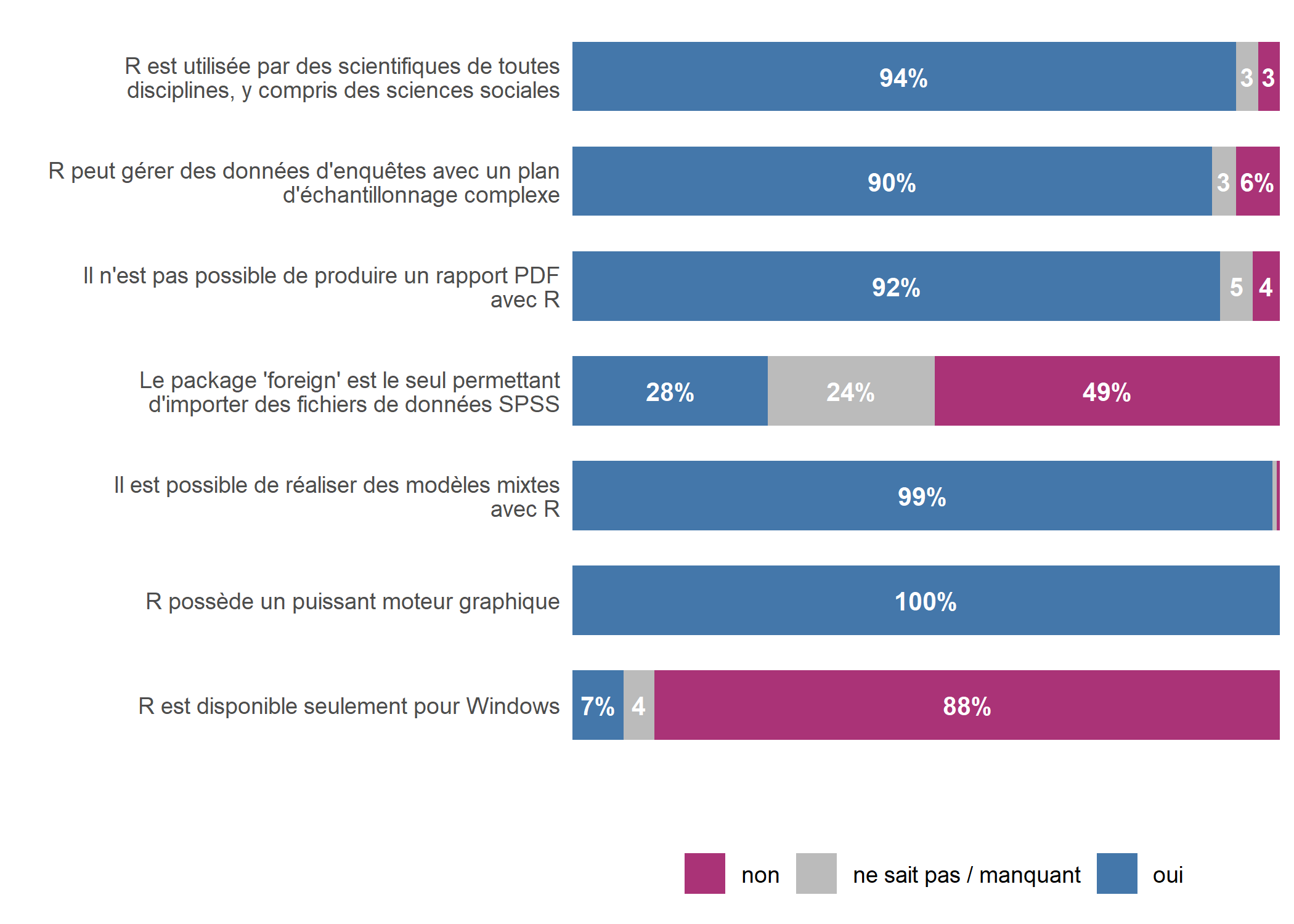
Nous allons donc choisir des couleurs plus pertinentes et les définir manuellement avec scale_fill_manual.
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
scale_fill_manual(values = c("#AA3377", "#BBBBBB", "#4477AA")) +
coord_flip() +
labs(x = "", y = "", fill = "") +
theme_minimal() +
theme(
legend.position = "bottom",
panel.grid = element_blank(),
axis.text.x = element_blank()
)
Pour faciliter la lecture, il serait pertinent que la légende soit dans le même ordre que le graphique (i.e. “oui” à gauche et “non” à droite). Nous allons donc inverser l’ordre de la légence en passant fill = guide_legend(reverse = TRUE) à guides.
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
scale_fill_manual(values = c("#AA3377", "#BBBBBB", "#4477AA")) +
coord_flip() +
labs(x = "", y = "", fill = "") +
guides(fill = guide_legend(reverse = TRUE)) +
theme_minimal() +
theme(
legend.position = "bottom",
panel.grid = element_blank(),
axis.text.x = element_blank()
)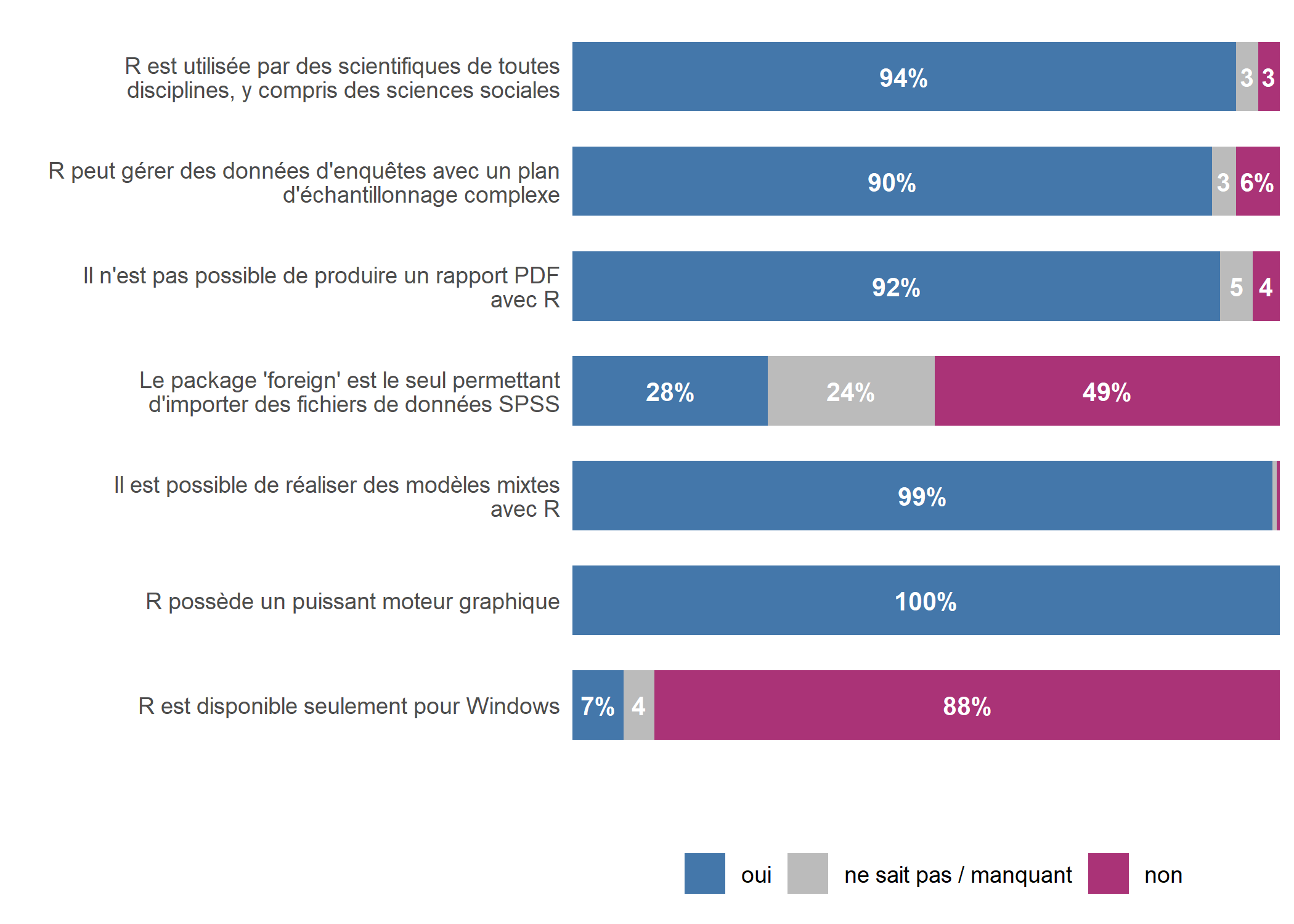
Il n’est pas évident de repérer ici au premier coup d’oeil quelle est la question qui a eu le plus de “oui”. Nous allons donc ordonner les questions en fonction du pourcentage de “oui” grâce à la fonction fct_reorder.
conn$etiquette <- conn$etiquette %>%
fct_reorder(conn$reponse == "oui", .fun = "sum")
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
scale_fill_manual(values = c("#AA3377", "#BBBBBB", "#4477AA")) +
coord_flip() +
labs(x = "", y = "", fill = "") +
guides(fill = guide_legend(reverse = TRUE)) +
theme_minimal() +
theme(
legend.position = "bottom",
panel.grid = element_blank(),
axis.text.x = element_blank()
)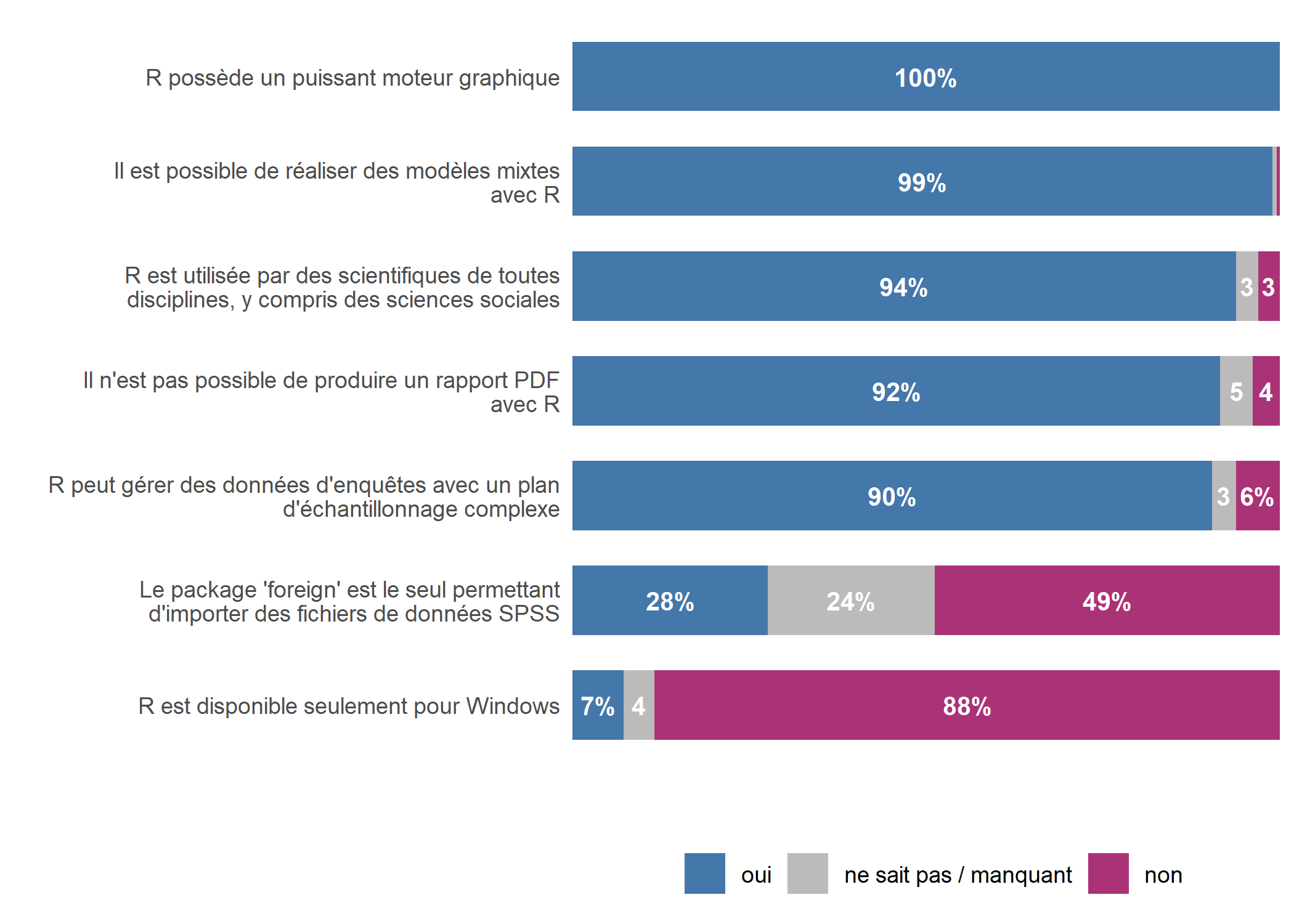
Toutes ces affirmations ne sont pas justes. Il serait donc pertinent de distinguer les affirmations justes (pour lesquelles la bonne réponse est “oui” des autres). Nous allons donc créer une nouvelle variable pour séparer ensuite les réponses avec facet_grid (attention : il est important de préciser scales = "free", space = "free").
conn$correcte <- conn$question %>%
fct_recode(
"bonne réponse : non" = "conn_a",
"bonne réponse : oui" = "conn_b",
"bonne réponse : oui" = "conn_c",
"bonne réponse : non" = "conn_d",
"bonne réponse : non" = "conn_e",
"bonne réponse : oui" = "conn_f",
"bonne réponse : oui" = "conn_g"
) %>%
fct_relevel("bonne réponse : oui")
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
scale_fill_manual(values = c("#AA3377", "#BBBBBB", "#4477AA")) +
coord_flip() +
labs(x = "", y = "", fill = "") +
guides(fill = guide_legend(reverse = TRUE)) +
facet_grid(rows = vars(correcte), scales = "free", space = "free") +
theme_minimal() +
theme(
legend.position = "bottom",
panel.grid = element_blank(),
axis.text.x = element_blank()
)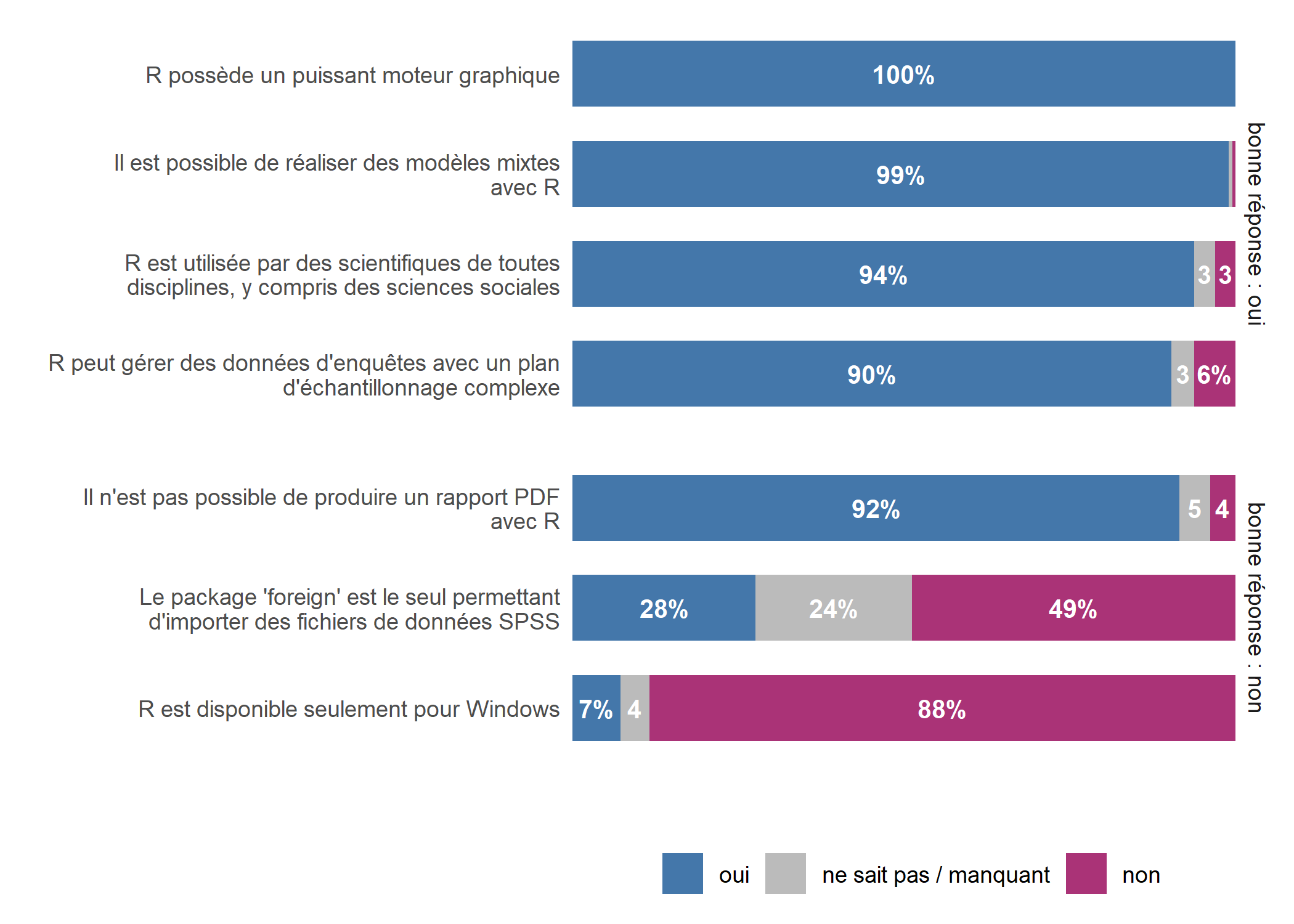
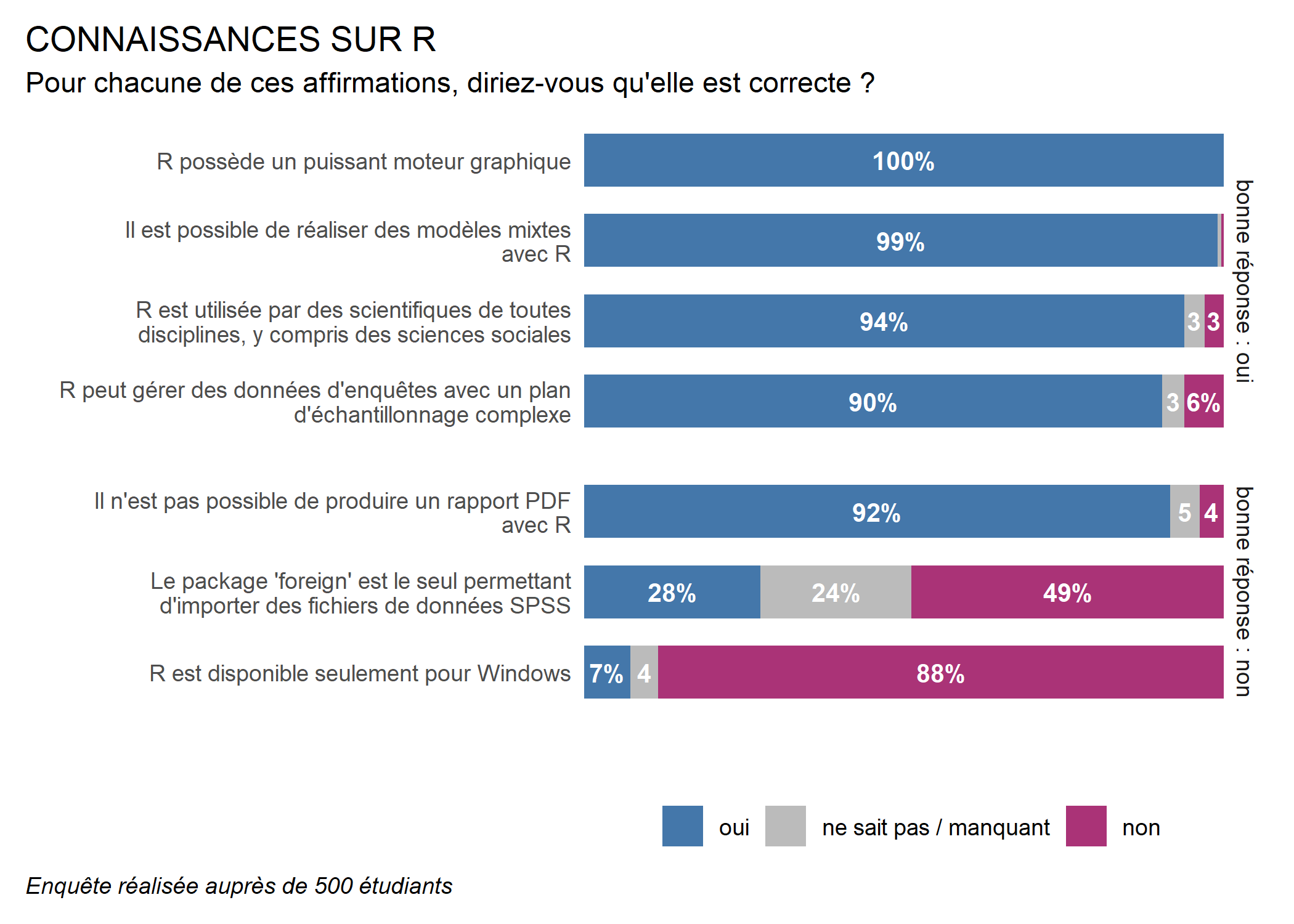
Il est maintenant bien visible que les étudiants ont en général bien répondu aux affirmations, mais qu’ils ont une connaissance erronnée concernant la possibilité de réaliser des rapports automatisés en PDF avec R.
Ajoutons maintenant un titre et un sous-titre avec ggtitle et une note avec l’option caption de labs.
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
scale_fill_manual(values = c("#AA3377", "#BBBBBB", "#4477AA")) +
coord_flip() +
labs(
x = "", y = "", fill = "",
caption = "Enquête réalisée auprès de 500 étudiants"
) +
ggtitle(
"CONNAISSANCES SUR R",
subtitle = "Pour chacune de ces affirmations, diriez-vous qu'elle est correcte ?"
) +
guides(fill = guide_legend(reverse = TRUE)) +
facet_grid(rows = vars(correcte), scales = "free", space = "free") +
theme_minimal() +
theme(
legend.position = "bottom",
panel.grid = element_blank(),
axis.text.x = element_blank()
)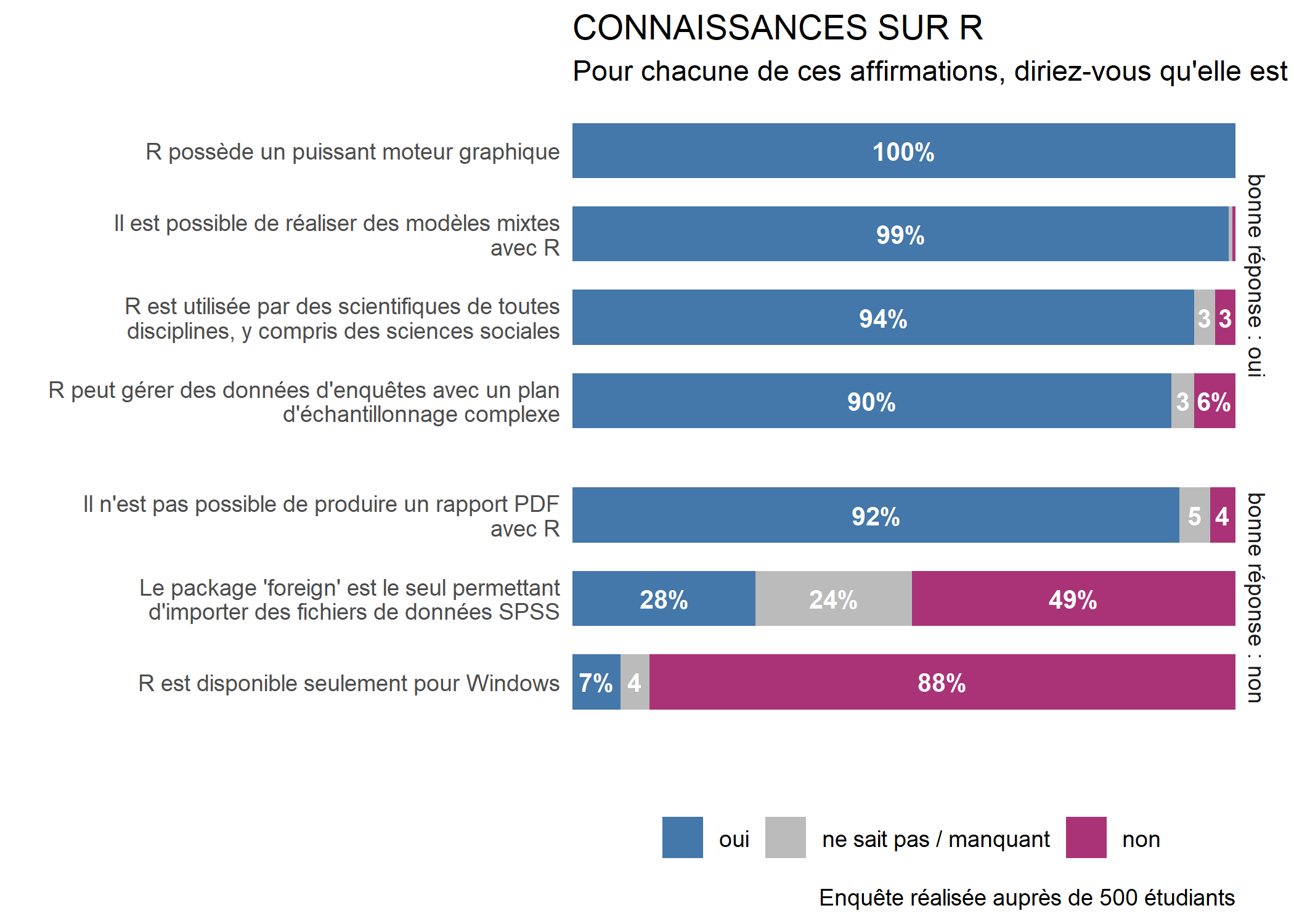
Nous pouvons procéder à quelques derniers ajustements (position du titre et de la note, note en italique, marges du graphique) an ajoutant quelques arguments additionnels à theme.
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
scale_fill_manual(values = c("#AA3377", "#BBBBBB", "#4477AA")) +
coord_flip() +
labs(
x = "", y = "", fill = "",
caption = "Enquête réalisée auprès de 500 étudiants"
) +
ggtitle(
"CONNAISSANCES SUR R",
subtitle = "Pour chacune de ces affirmations, diriez-vous qu'elle est correcte ?"
) +
guides(fill = guide_legend(reverse = TRUE)) +
facet_grid(rows = vars(correcte), scales = "free", space = "free") +
theme_minimal() +
theme(
legend.position = "bottom",
panel.grid = element_blank(),
axis.text.x = element_blank(),
plot.title.position = "plot",
plot.caption.position = "plot",
plot.caption = element_text(face = "italic", hjust = 0),
plot.margin = margin(10, 10, 10, 10)
)
Enfin, pour un rendu un peu plus moderne, nous allons opter pour une autre police de caractères, ici “Arial Narrow”. Afin de pouvoir utiliser des polices systèmes, nous aurons besoin de l’extension extrafont. La police doit être précisée à la fois dans theme_minimal et dans geom_text.
library(extrafont)
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5,
family = "Arial Narrow"
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
scale_fill_manual(values = c("#AA3377", "#BBBBBB", "#4477AA")) +
coord_flip() +
labs(
x = "", y = "", fill = "",
caption = "Enquête réalisée auprès de 500 étudiants"
) +
ggtitle(
"CONNAISSANCES SUR R",
subtitle = "Pour chacune de ces affirmations, diriez-vous qu'elle est correcte ?"
) +
guides(fill = guide_legend(reverse = TRUE)) +
facet_grid(rows = vars(correcte), scales = "free", space = "free") +
theme_minimal(base_family = "Arial Narrow") +
theme(
legend.position = "bottom",
panel.grid = element_blank(),
axis.text.x = element_blank(),
plot.title.position = "plot",
plot.caption.position = "plot",
plot.caption = element_text(face = "italic", hjust = 0),
plot.margin = margin(10, 10, 10, 10)
)Warning in grid.Call(C_stringMetric,
as.graphicsAnnot(x$label)): famille de police introuvable
dans la base de données des polices Windows
Warning in grid.Call(C_stringMetric,
as.graphicsAnnot(x$label)): famille de police introuvable
dans la base de données des polices WindowsWarning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices WindowsWarning in grid.Call(C_stringMetric,
as.graphicsAnnot(x$label)): famille de police introuvable
dans la base de données des polices WindowsWarning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices WindowsWarning in grid.Call.graphics(C_text,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call.graphics(C_text,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call.graphics(C_text,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call.graphics(C_text,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call.graphics(C_text,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices WindowsWarning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows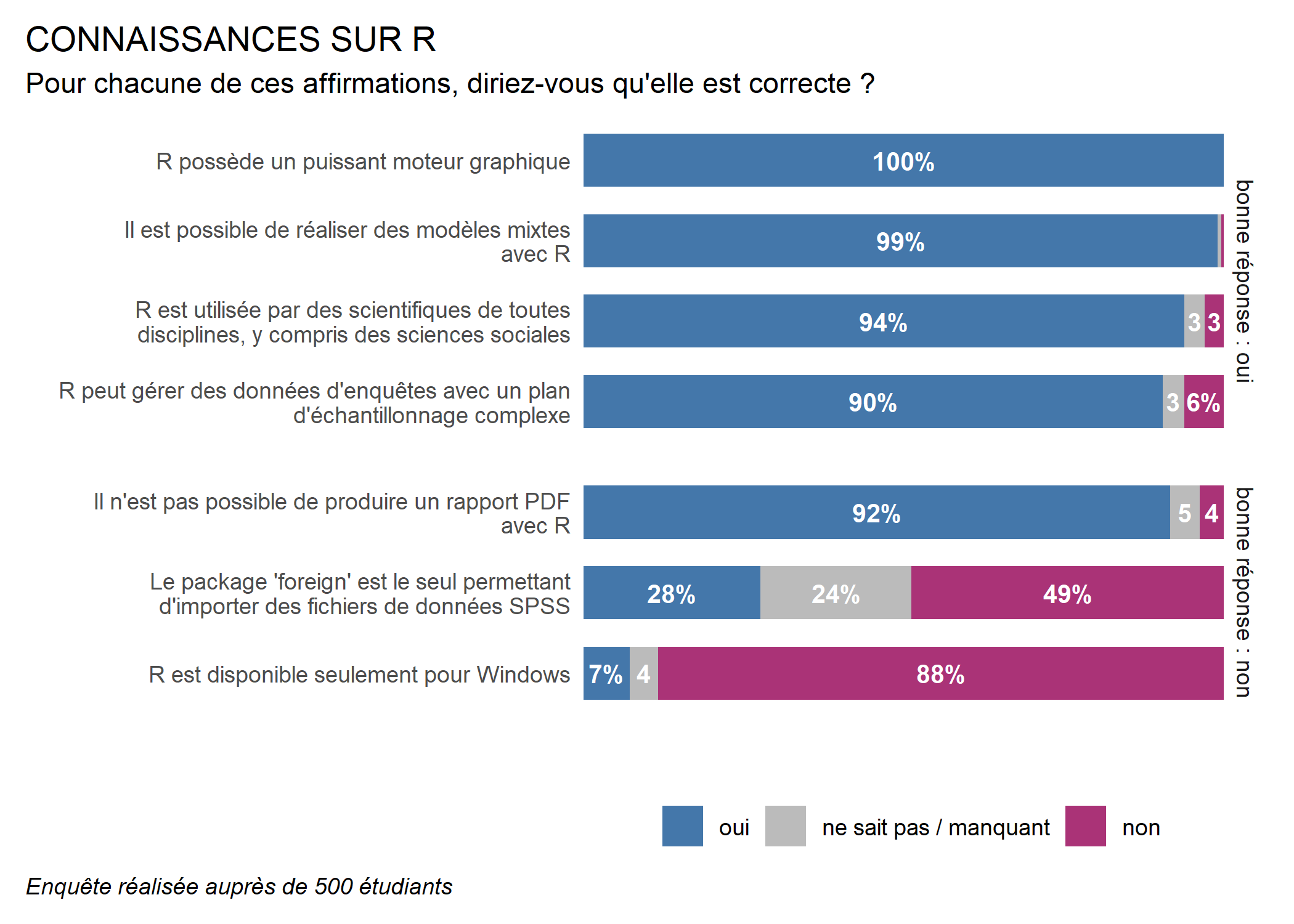
Code final du graphique
Nous y voilà !
library(tidyverse)
library(GGally)
library(extrafont)
conn <- quest %>%
select(starts_with("conn_")) %>%
pivot_longer(
cols = starts_with("conn_"),
names_to = "question",
values_to = "reponse"
)
conn$reponse <- conn$reponse %>%
fct_explicit_na("NSP") %>%
fct_relevel("non", "NSP", "oui") %>%
fct_recode("ne sait pas / manquant" = "NSP")
conn$etiquette <- conn$question %>%
fct_recode(
"R est disponible seulement pour Windows" = "conn_a",
"R possède un puissant moteur graphique" = "conn_b",
"Il est possible de réaliser des modèles mixtes avec R" = "conn_c",
"Le package 'foreign' est le seul permettant d'importer des fichiers de données SPSS" = "conn_d",
"Il n'est pas possible de produire un rapport PDF avec R" = "conn_e",
"R peut gérer des données d'enquêtes avec un plan d'échantillonnage complexe" = "conn_f",
"R est utilisée par des scientifiques de toutes disciplines, y compris des sciences sociales" = "conn_g"
) %>%
fct_reorder(conn$reponse == "oui", .fun = "sum")
conn$correcte <- conn$question %>%
fct_recode(
"bonne réponse : non" = "conn_a",
"bonne réponse : oui" = "conn_b",
"bonne réponse : oui" = "conn_c",
"bonne réponse : non" = "conn_d",
"bonne réponse : non" = "conn_e",
"bonne réponse : oui" = "conn_f",
"bonne réponse : oui" = "conn_g"
) %>%
fct_relevel("bonne réponse : oui")
f <- function(x) {
res <- scales::percent(x, accuracy = 1)
res[x < .05] <- scales::percent(x[x < .05], accuracy = 1, suffix = "")
res[x < .01] <- ""
res
}
ggplot(conn) +
aes(
x = etiquette, fill = reponse,
by = etiquette, label = f(after_stat(prop))
) +
geom_bar(position = "fill", width = .66) +
geom_text(
stat = "prop", position = position_fill(.5),
colour = "white", fontface = "bold", size = 3.5,
family = "Arial Narrow"
) +
scale_x_discrete(labels = scales::label_wrap(50)) +
scale_y_continuous(expand = c(0, 0)) +
scale_fill_manual(values = c("#AA3377", "#BBBBBB", "#4477AA")) +
coord_flip() +
labs(
x = "", y = "", fill = "",
caption = "Enquête réalisée auprès de 500 étudiants"
) +
ggtitle(
"CONNAISSANCES SUR R",
subtitle = "Pour chacune de ces affirmations, diriez-vous qu'elle est correcte ?"
) +
guides(fill = guide_legend(reverse = TRUE)) +
facet_grid(rows = vars(correcte), scales = "free", space = "free") +
theme_minimal(base_family = "Arial Narrow") +
theme(
legend.position = "bottom",
panel.grid = element_blank(),
axis.text.x = element_blank(),
plot.title.position = "plot",
plot.caption.position = "plot",
plot.caption = element_text(face = "italic", hjust = 0),
plot.margin = margin(10, 10, 10, 10)
)Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices WindowsWarning in grid.Call.graphics(C_text,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call.graphics(C_text,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call.graphics(C_text,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call.graphics(C_text,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call.graphics(C_text,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices WindowsWarning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows
Warning in grid.Call(C_textBounds,
as.graphicsAnnot(x$label), x$x, x$y, : famille de police
introuvable dans la base de données des polices Windows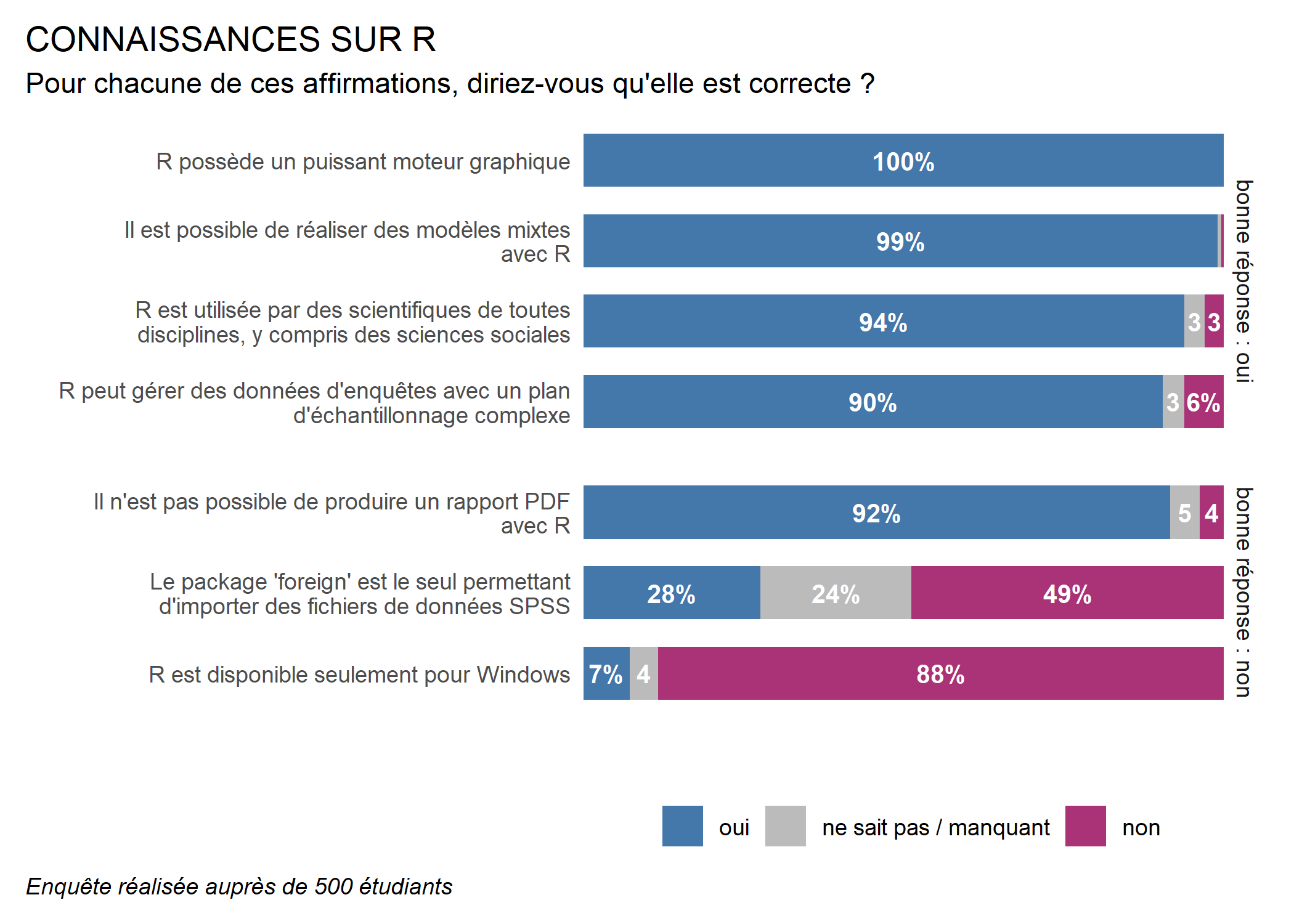
Évolutions temporelles
Pour cet exemple, nous allons utiliser des données fictives. Dans les années 1950, au sortir de la guerre, la Syldavie et la Bordurie (deux pays fictifs inventés par Hergé) ont décidé de mettre un programme de distribution de bandes dessinées de Tintin dans des écoles et des collèges afin de motiver les élèves à lire plus. Nous disposons des rapports d’activités des différents agents du programme qui indident, par mois et par type d’établissement, le nombre d’élèves rencontrés et le nombre de bandes dessinées distribués.
Commençons par importer les données, qui sont au format Excel. Nous utiliserons donc la fonction read_excel de l’extension readxl. Profitons-en pour charger également en mémoire le tidyverse ainsi que l’extension lubridate qui nous servira pour la gestion des dates.
library(readxl)
library(tidyverse)
library(lubridate)
url <- "https://larmarange.github.io/analyse-R/data/bandes_dessinees_tintin.xlsx"
destfile <- "bandes_dessinees_tintin.xlsx"
curl::curl_download(url, destfile)
bd <- read_excel(destfile)Rows: 4,331
Columns: 6
$ annee <dbl> 1950, 1950, 1951, 1951, 1951, 1…
$ mois <dbl> 9, 10, 4, 2, 4, 5, 5, 3, 2, 5, …
$ pays <chr> "Bordurie", "Bordurie", "Bordur…
$ type_etablissement <chr> "école primaire", "école primai…
$ eleves_rencontres <dbl> 2, 3, 6, 16, 1, 5, 6, 3, 5, 3, …
$ bd_distribuees <dbl> 3, 3, 6, 16, 1, 5, 12, 4, 6, 5,…Bandes dessinées distribuées par mois
En premier lieu, nous souhaiterions représenter le nombre de bandes dessinées distribuées par mois. Comme on peut le voir, nous n’avons pas directement une variable date, l’année et le mois étant indiqués dans deux variables différentes. Nous allons donc commencer par créer une telle variable, qui correspondra au premier jour du mois.
Nous allons utiliser la fonction paste0 qui permets de concaténer du texte pour créer des chaines de texte au format ANNEE-MOIS-JOUR puis transformer cela en objet Date avec ymd de l’extension lubridate.
Min. 1st Qu. Median Mean
"1949-12-01" "1950-07-01" "1950-12-01" "1950-11-13"
3rd Qu. Max.
"1951-04-01" "1951-07-01" Nous pouvons maintenant commencer à réaliser notre graphique. Nous allons compter le nombre de BD distribuées par mois et représenter cela sous forme d’un graphique en barres. geom_bar utilise la statistique stat_count pour compter le nombre d’observations. Cependant, le nombre de BD distribuées varie d’une ligne du fichier à l’autre. Nous allons donc utiliser l’esthétique weight pour pondérer le calcul et obtenir le total de bandes dessinées distribuées. Nous allons également utiliser l’esthétique fill pour distinguer les écoles primaires et les collèges.
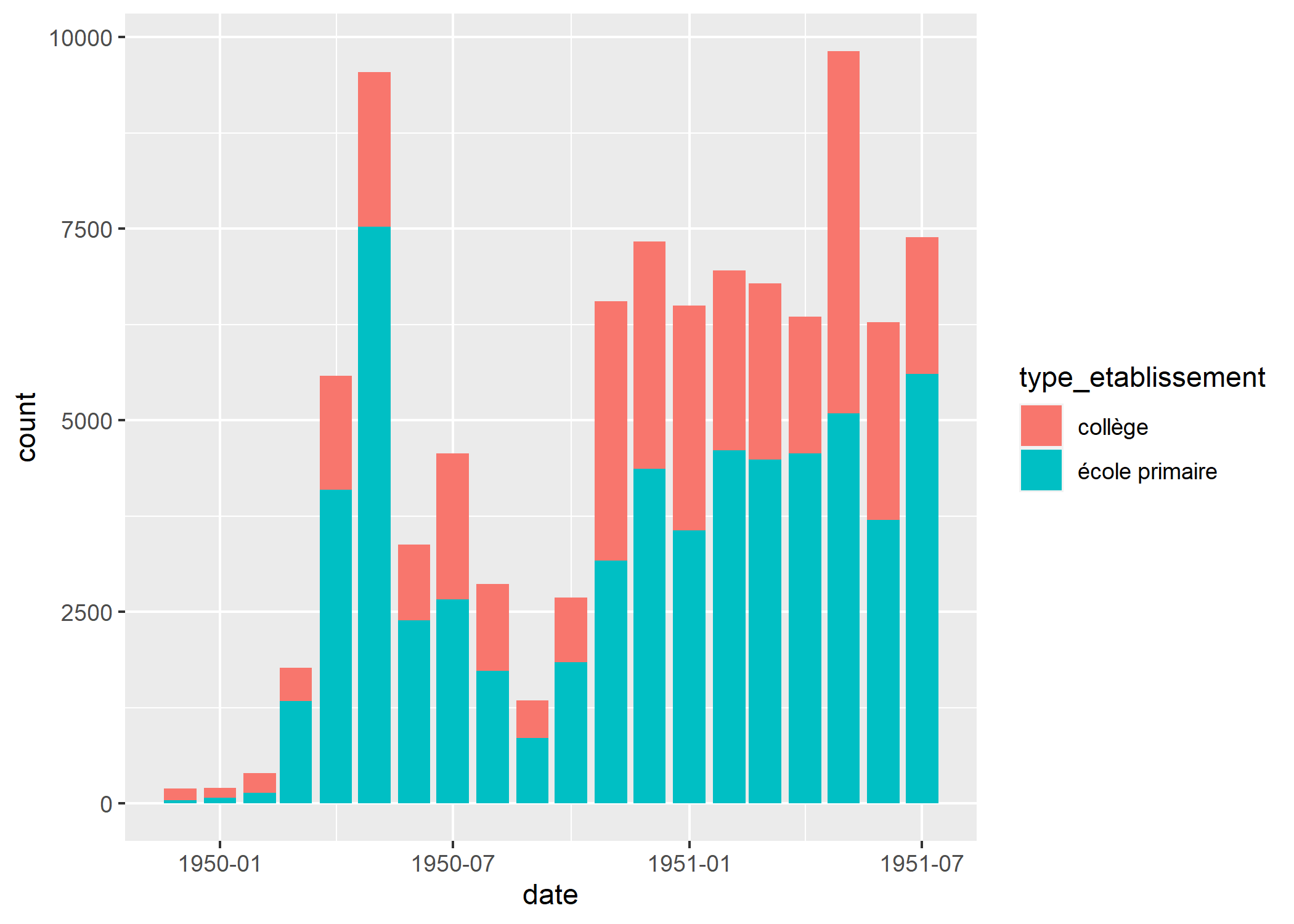
Avec facet_grid nous pouvons comparer la Syldavie et la Bordurie.
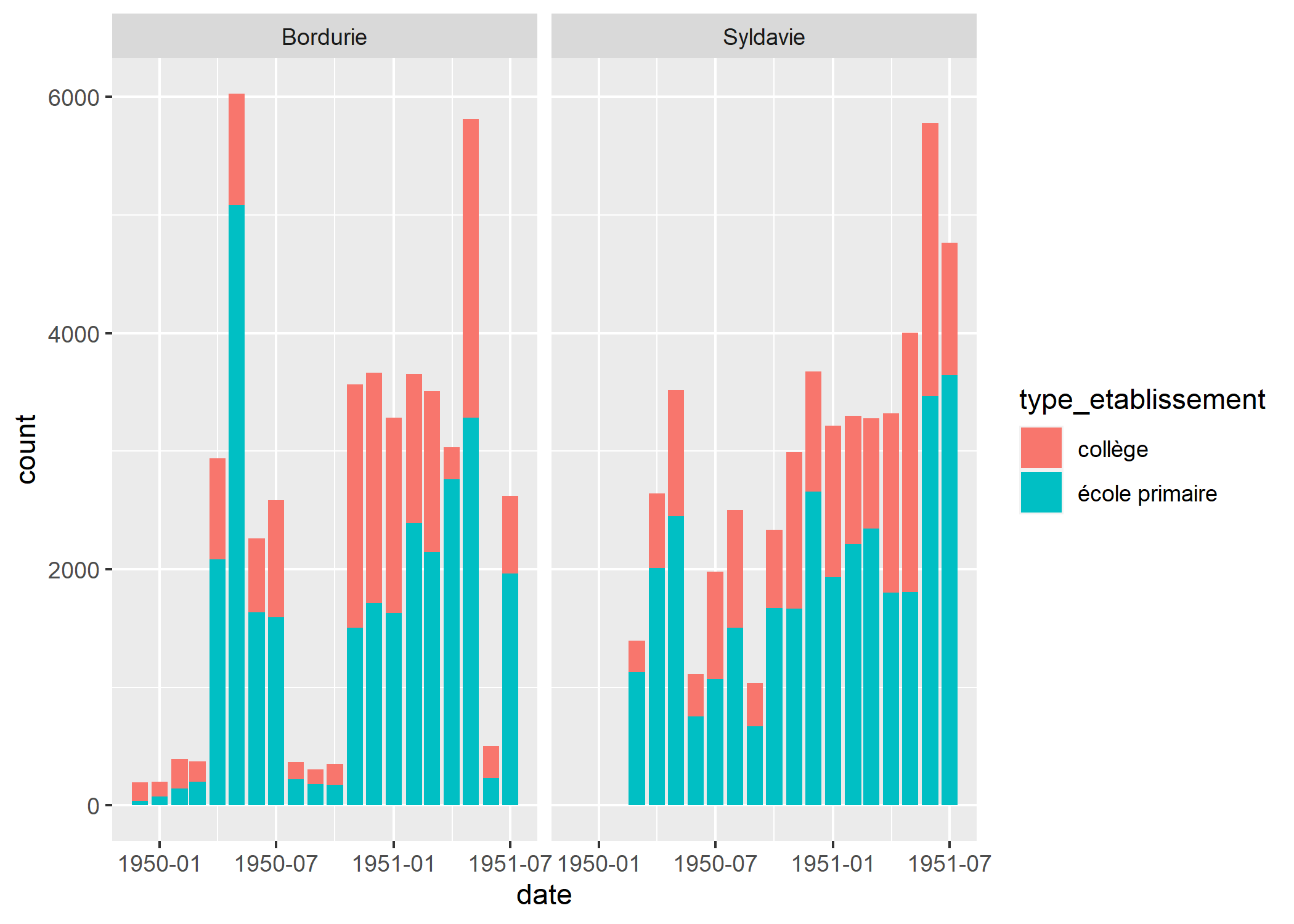
Essayons de faire un peu mieux en répétant l’axe des y sur le graphique de droite, ce qui peut être fait avec la fonction facet_rep_grid de l’extension lemon.
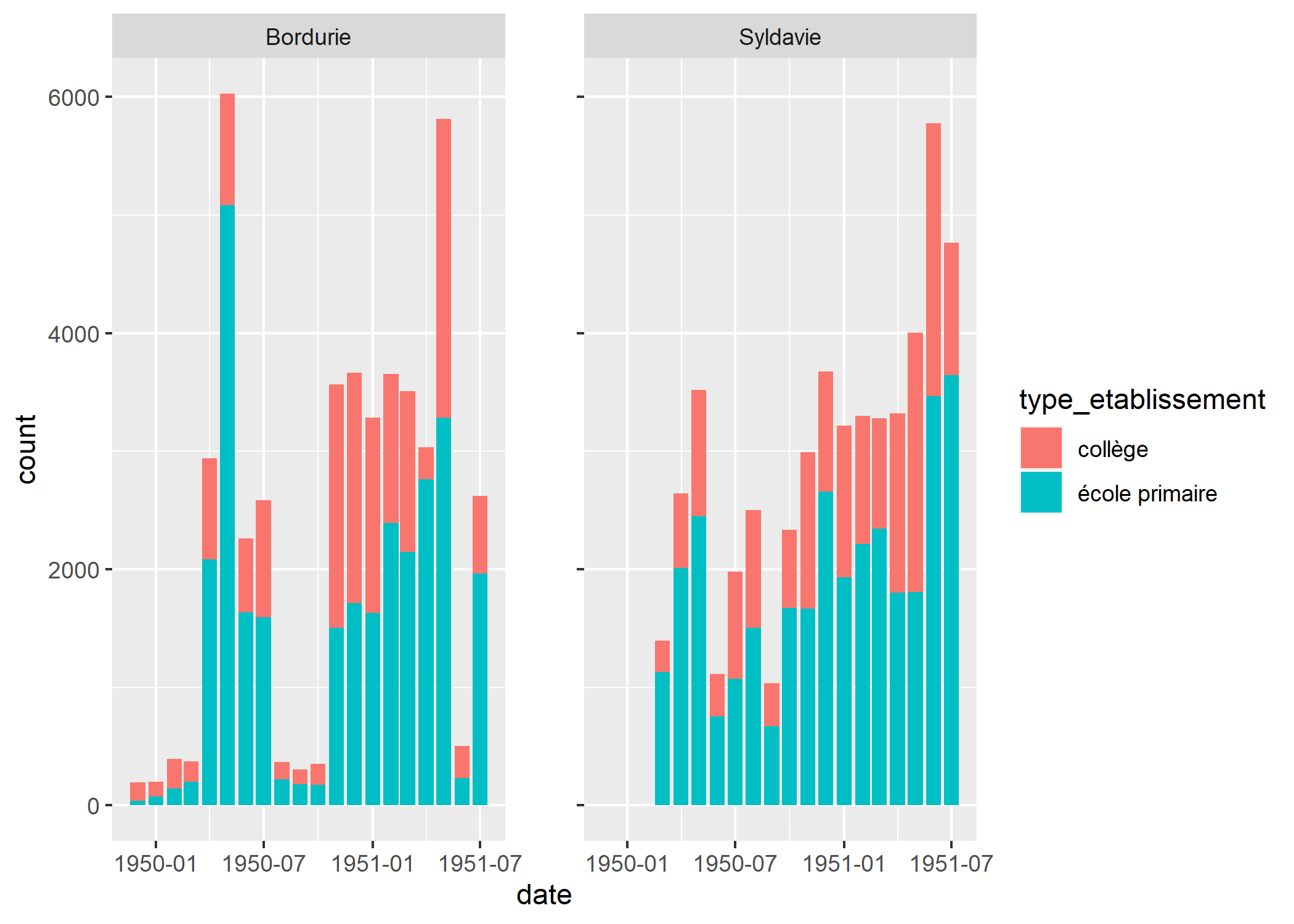
Cela a répété les encoches (ticks). Pour répéter également les étiquettes, il nous faut ajouter l’option repeat.tick.labels = TRUE.
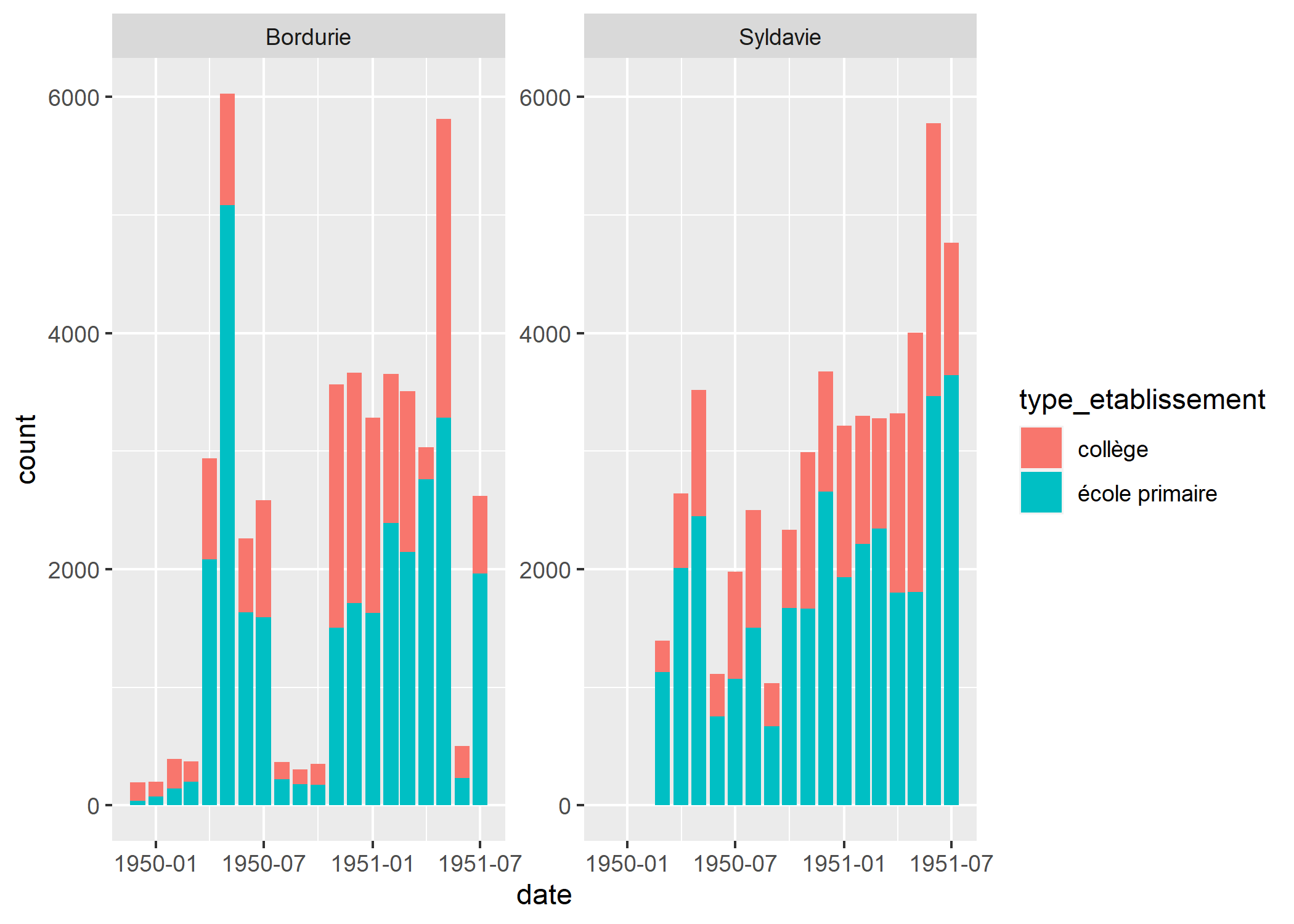
Allégeons un peu le graphique (voir exemple précédent). Pour cela, nous allons utiliser le thème theme_clean fourni par ggthemes.
library(ggthemes)
p <- p +
xlab("") + ylab("") + labs(fill = "") +
ggtitle("Bandes dessinées distribuées par mois") +
theme_clean() +
theme(
legend.position = "bottom"
)
p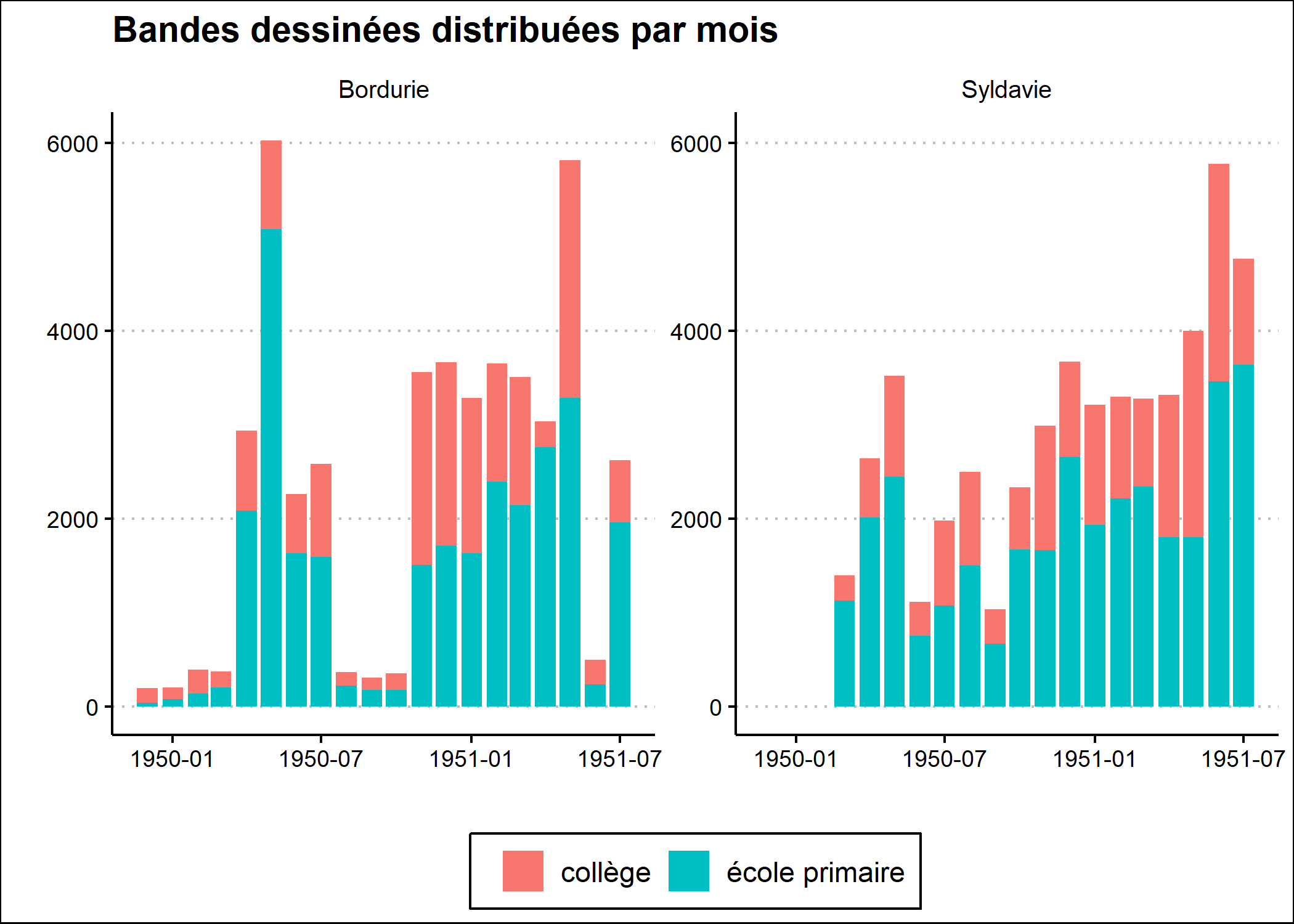
De même, nous allons utiliser une palette de couleurs adaptées aux personnes daltoniennes, en s’appuyant sur scale_fill_bright disponible avec khroma.
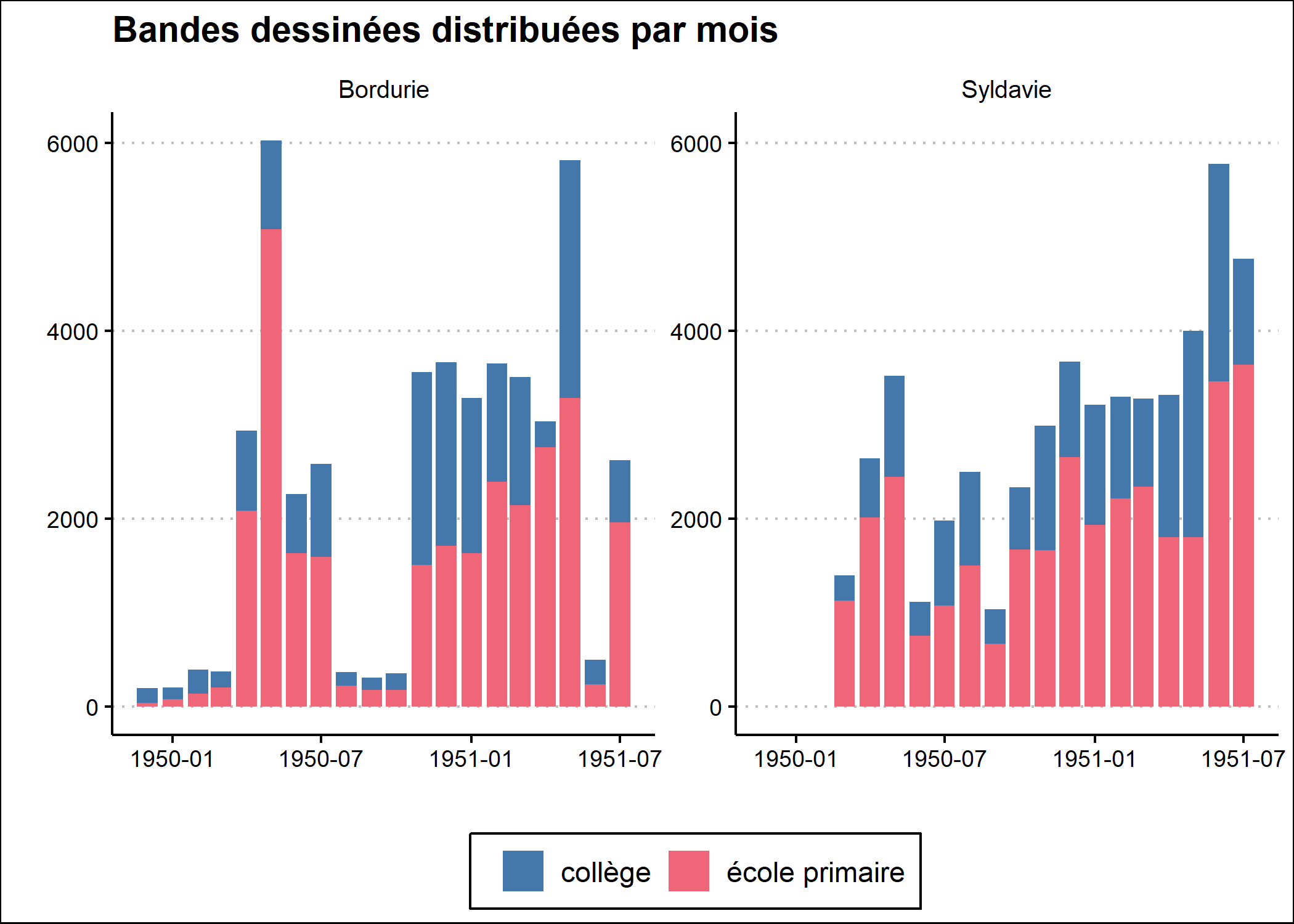
Reste à améliorer la présentation de l’axe des x avec scale_x_date{data-pkg=“ggplot2}. L’option date_labels permet de personnaliser l’affichage des dates via des raccourcis décrits dans l’aide de la fonction strptime. Ainsi, %b correspond au mois écrit textuellement de manière abrégée et %Y à l’année sur 4 chiffres. \n est utilisé pour indiquer un retour à la ligne. L’option date_breaks permet d’indiquer de manière facilitée la durée attendue entre deux étiquettes, ici trois mois.
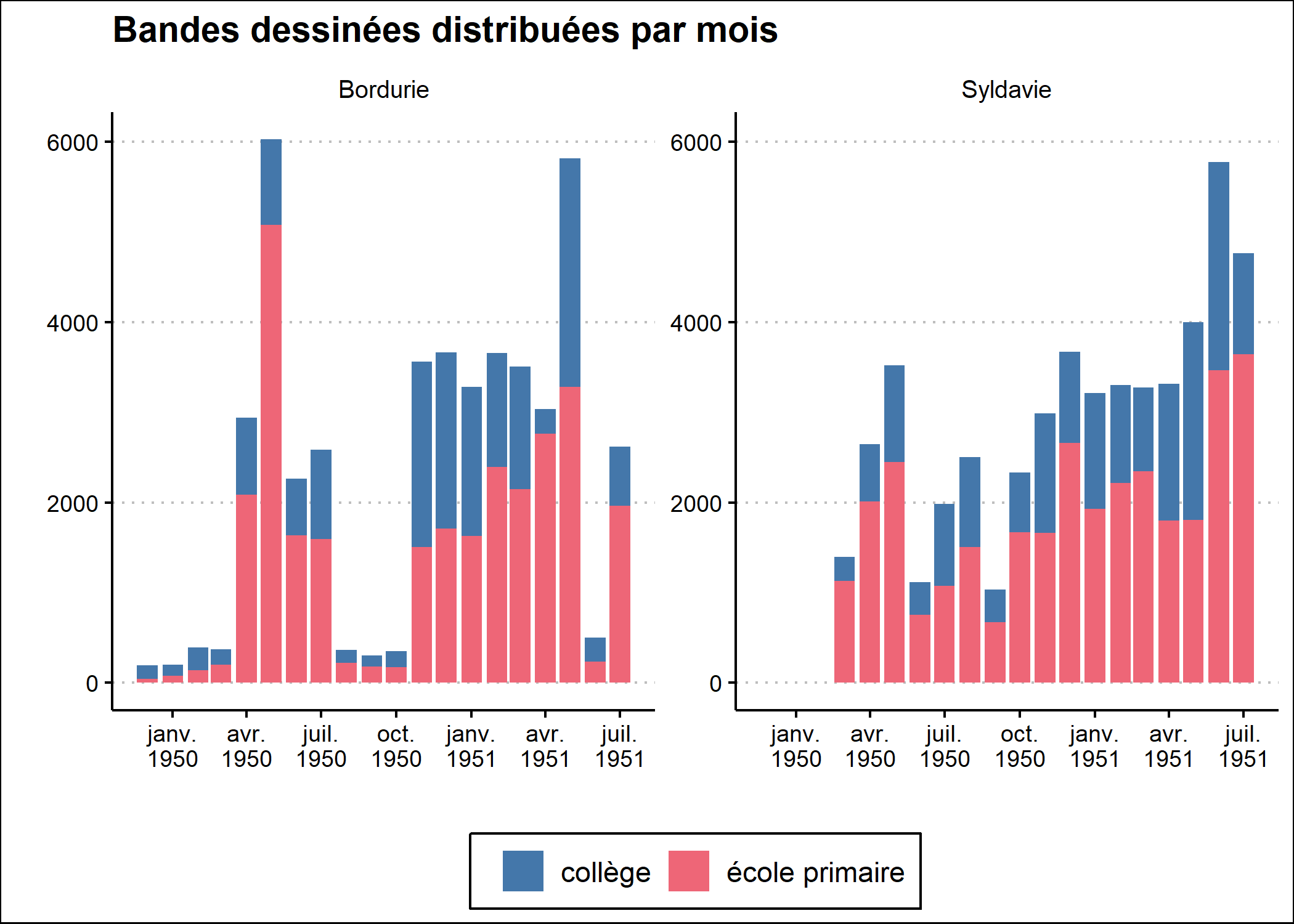
Pour améliorer le graphique, nous aimerions rajouter une encoche sous chaque mois. Ceci est rendu possible avec la fonction guide_axis_minor de ggh4x.
library(ggh4x)
p <- p + scale_x_date(
date_labels = "%b\n%Y",
date_breaks = "3 months",
date_minor_breaks = "1 month",
guide = guide_axis_minor()
)Scale for x is already present.
Adding another scale for x, which will replace the existing
scale.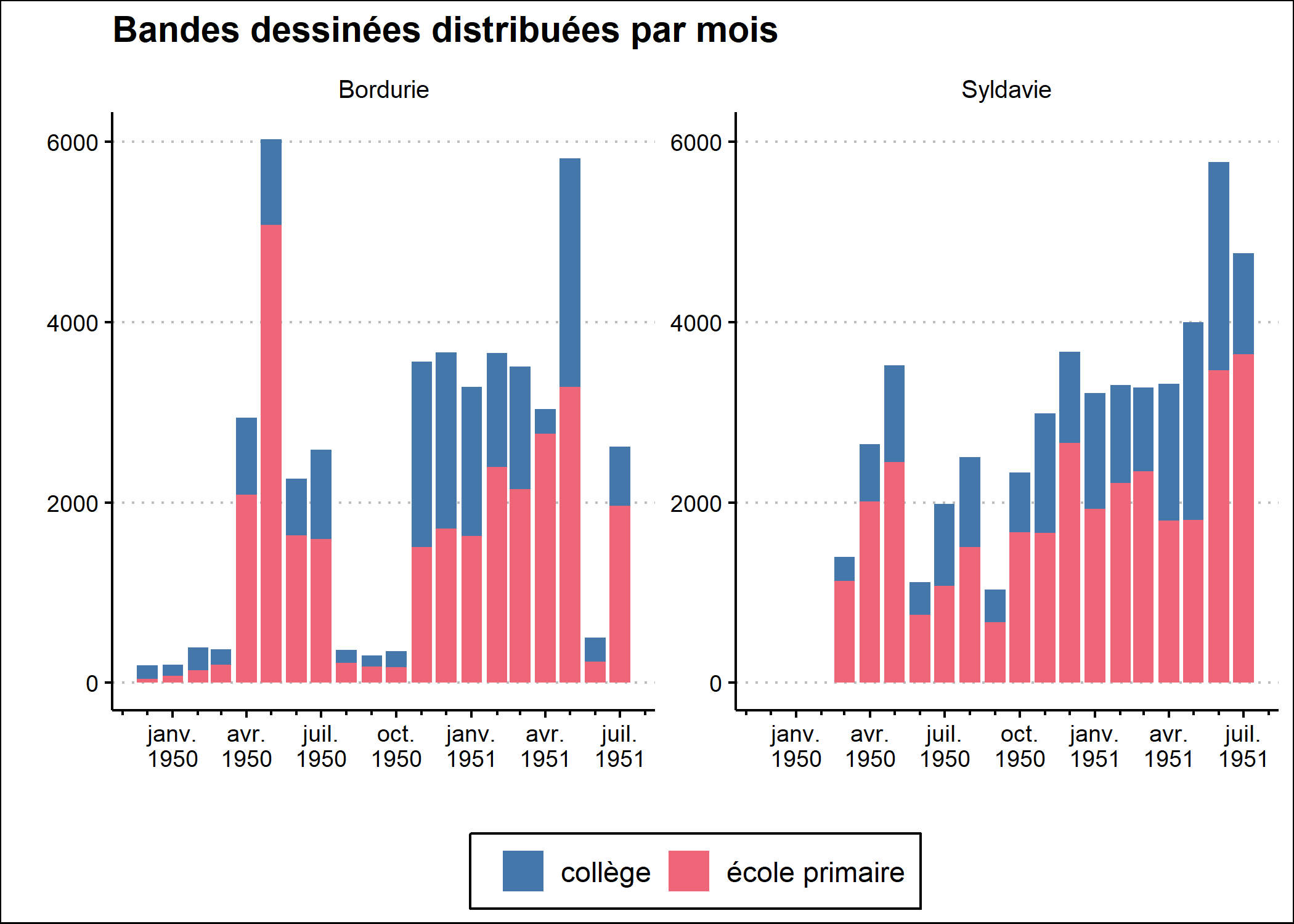
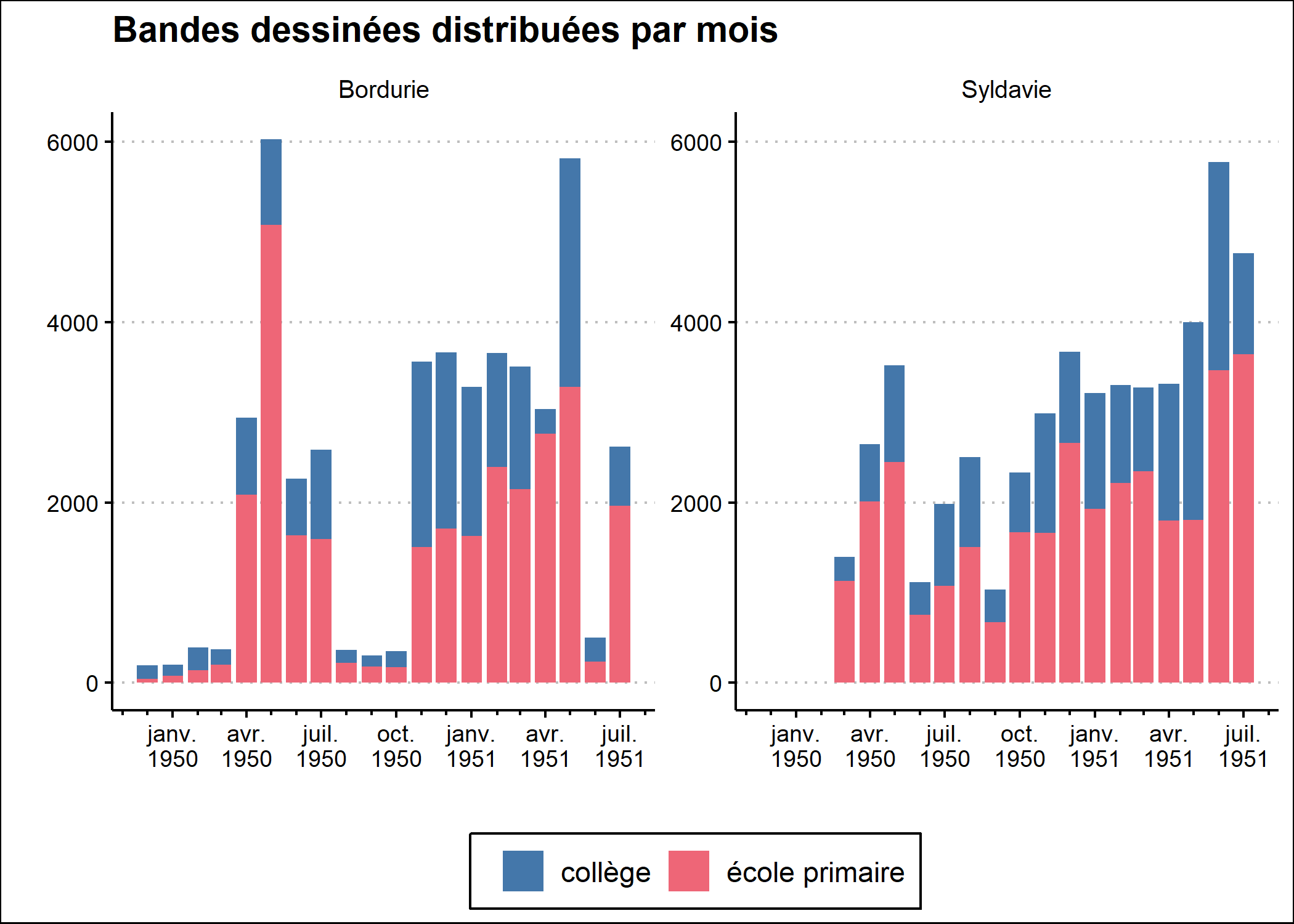
Le code complet de ce graphique est donc :
library(ggthemes)
library(khroma)
library(ggh4x)
library(lemon)
ggplot(bd) +
aes(x = date, weight = bd_distribuees, fill = type_etablissement) +
geom_bar() +
facet_rep_grid(cols = vars(pays), repeat.tick.labels = TRUE) +
xlab("") +
ylab("") +
labs(fill = "") +
ggtitle("Bandes dessinées distribuées par mois") +
scale_x_date(
date_labels = "%b\n%Y",
date_breaks = "3 months",
date_minor_breaks = "1 month",
guide = guide_axis_minor()
) +
scale_fill_bright() +
theme_clean() +
theme(
legend.position = "bottom"
)
Évolution du nombre moyen de bandes dessinées remises par élève
Nous disposons dans les rapports d’activités du nombre de bandes dessinées distribuées et du nombre d’élèves rencontrés. Nous pouvons donc regarder comment à évaluer au cours du temps le nombre moyen de bandes dessinées distribuées par élève, à savoir l’évolution du ratio bd_distribuees / eleves_rencontres.
ggplot(bd) +
aes(x = date, y = bd_distribuees / eleves_rencontres, colour = type_etablissement) +
geom_point()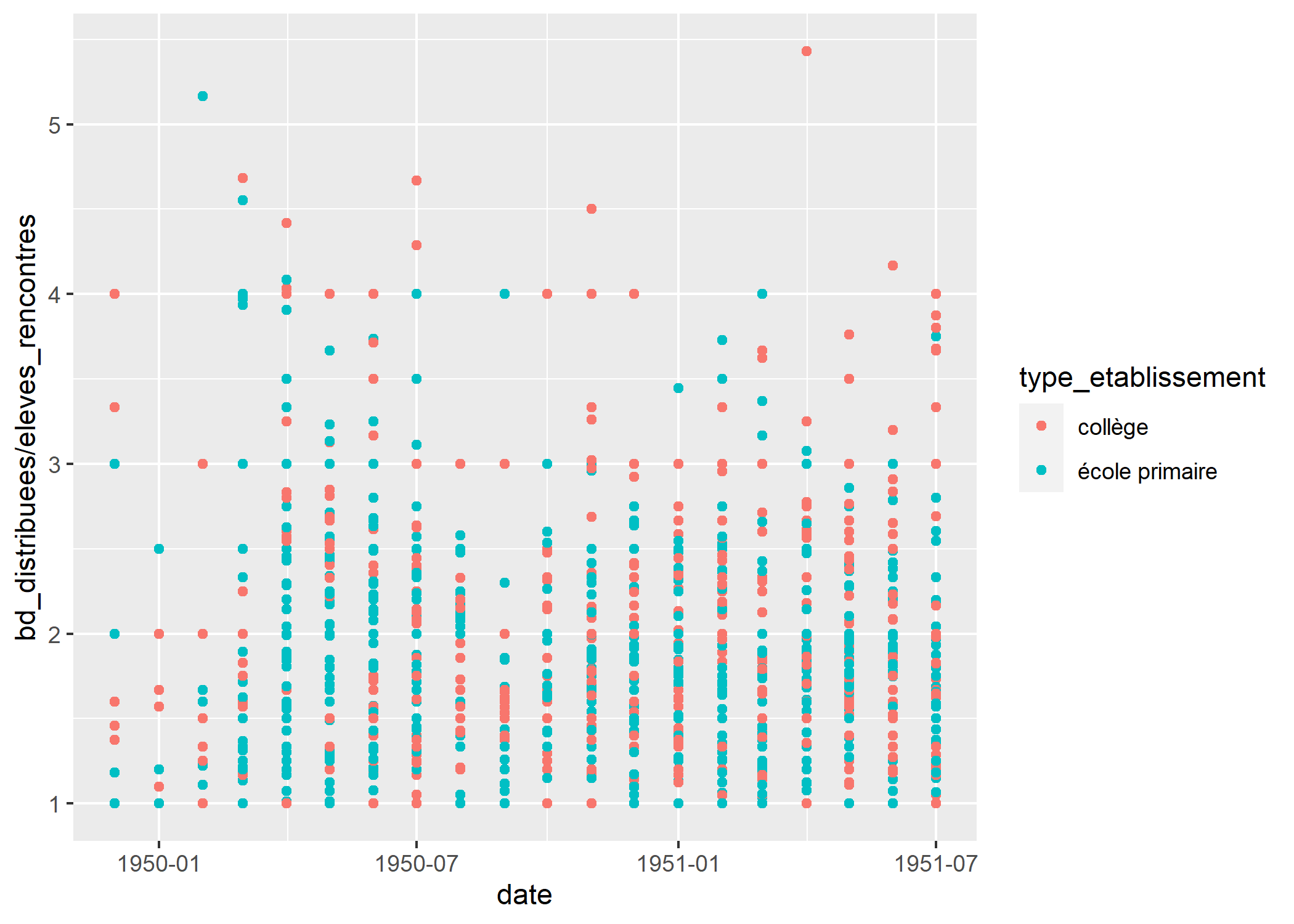
Comme on le voit sur la figure précédente, si l’on représente directement cet indicateur, nous obtenons plusieurs points pour chaque date. En effet, nous avons plusieurs observations par date et nous obtenons donc un point pour chacune de ces observations. Nous souhaiterions avoir la moyenne pour chaque date. Cela est possible en ayant recours à stat_weighted_mean de l’extension GGally. Pour que le calcul soit correct, il faut réaliser une moyenne pondérée par le dénominateur, à savoir ici le nombre d’élèves.
library(GGally)
ggplot(bd) +
aes(
x = date, y = bd_distribuees / eleves_rencontres,
weight = eleves_rencontres, colour = type_etablissement
) +
geom_point(stat = "weighted_mean")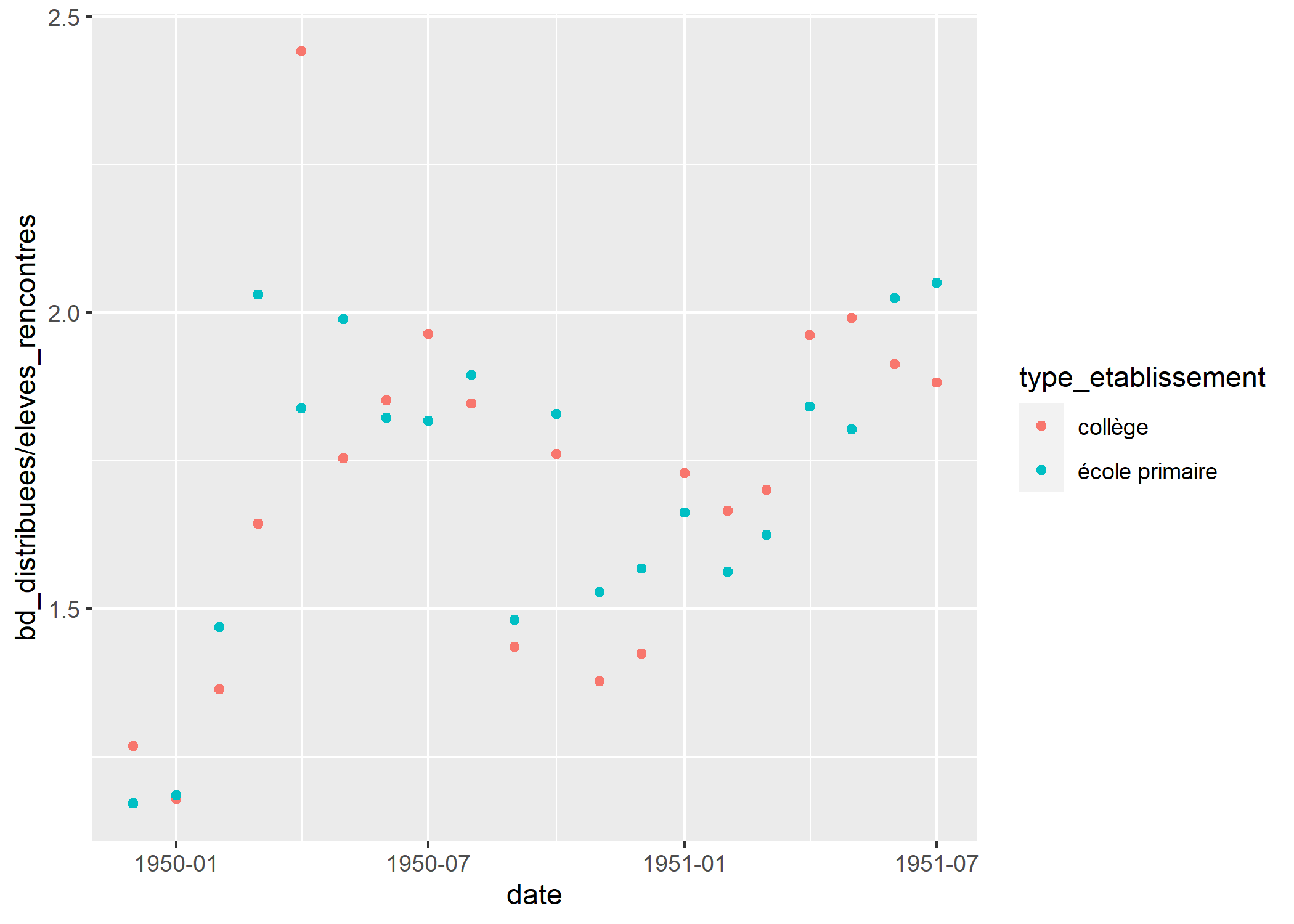
Le graphique sera plus lisible si nous représentons des lignes.
library(GGally)
ggplot(bd) +
aes(
x = date, y = bd_distribuees / eleves_rencontres,
weight = eleves_rencontres, colour = type_etablissement
) +
geom_line(stat = "weighted_mean")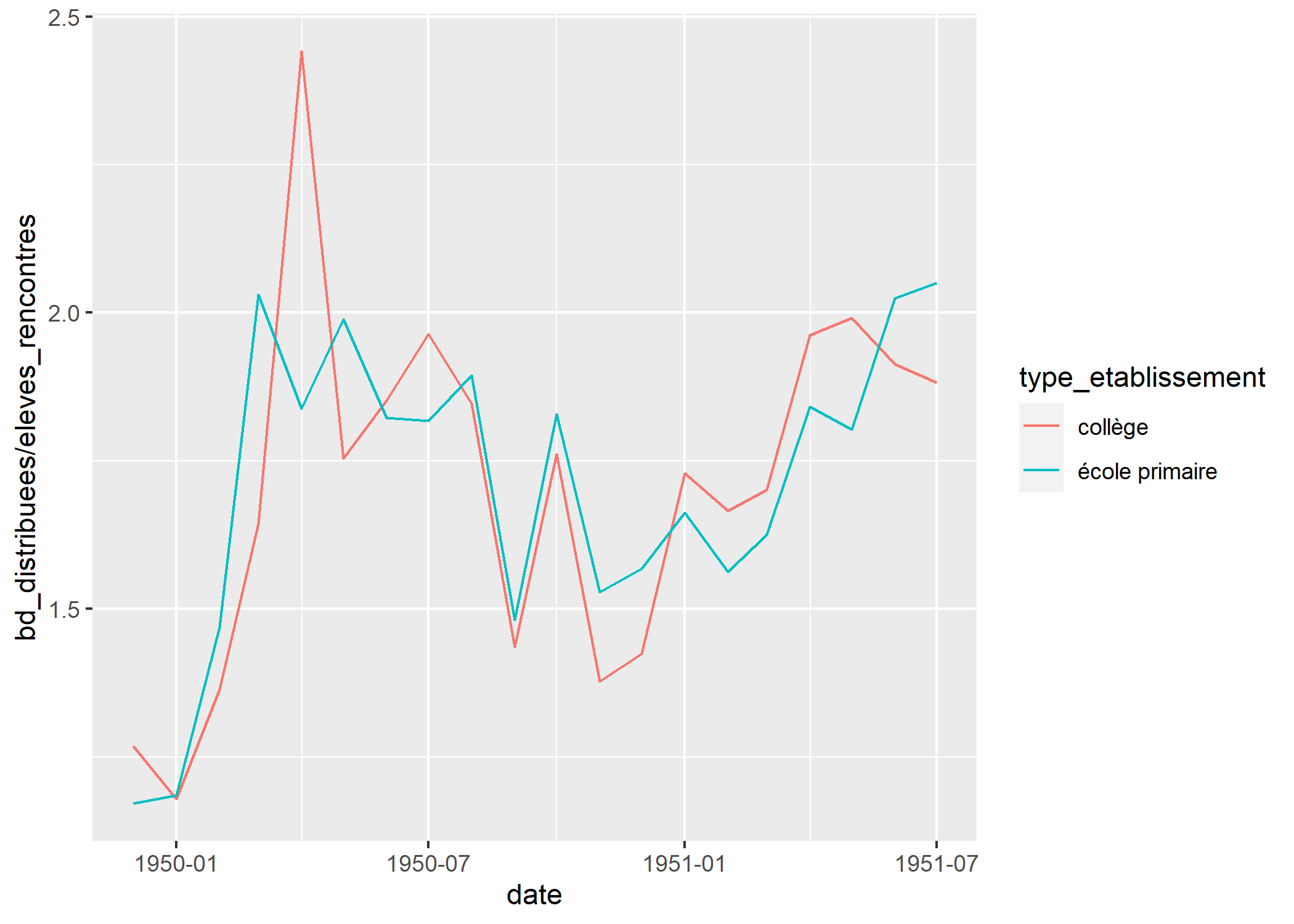
Pour améliorer la comparaison, il serait pertinent d’ajouter les intervalles de confiance sur le graphique. Cela peut être réalisé par exemple avec des rubans de couleur. Mais pour cela, il va falloir avoir recours à quelques astuces pour permettre le calcul de ces intervalles de confiance à la volée.
Tout d’abord, pour calculer l’intervalle de confiance d’un ratio de nombres entiers, nous pouvons utiliser un test de Poisson avec poisson.test auquel nous devons transmettre le numérateur et le dénominateur. Par exemple, pour 48 bandes dessinées distribuées à 27 élèves :
Exact Poisson test
data: 48 time base: 27
number of events = 48, time base = 27, p-value =
0.0002246
alternative hypothesis: true event rate is not equal to 1
95 percent confidence interval:
1.310793 2.357075
sample estimates:
event rate
1.777778 List of 9
$ statistic : Named num 48
..- attr(*, "names")= chr "number of events"
$ parameter : Named num 27
..- attr(*, "names")= chr "time base"
$ p.value : num 0.000225
$ conf.int : num [1:2] 1.31 2.36
..- attr(*, "conf.level")= num 0.95
$ estimate : Named num 1.78
..- attr(*, "names")= chr "event rate"
$ null.value : Named num 1
..- attr(*, "names")= chr "event rate"
$ alternative: chr "two.sided"
$ method : chr "Exact Poisson test"
$ data.name : chr "48 time base: 27"
- attr(*, "class")= chr "htest"Comme nous le montre str, poisson.test renvoie une liste avec différents éléments et l’intervalle de confiance est disponible dans le sous-objet "conf.int". Il est possible d’y accéder avec l’opérateur $ ou bien avec la fonction pluck de l’extension purrr chargée par défaut avec le tidyverse.
[1] 1.310793 2.357075
attr(,"conf.level")
[1] 0.95[1] 1.310793 2.357075
attr(,"conf.level")
[1] 0.95Pour obtenir la borne inférieure de l’intervalle de confiance, il nous faut maintenant extraire le premier élément.
[1] 1.310793[1] 1.310793Nous avons trouvé la manière de calculer la borne inférieure de l’intervalle de confiance pour une ligne d’observations. Mais comment procéder pour plusieurs observations. Supposons que nous ayons 4 observations :
Si nous passons ces vecteurs de données à poisson.test, nous obtenons un message d’erreur car poisson.test ne permets de calculer qu’un seul test à la fois.
Error in poisson.test(num, denom) : le cas k > 2 n'est pas implémentéDans notre cas, nous souhaitons exécuter poisson.test ligne à ligne. Cela peut être réalisée avec la famille de fonctions map fournies par l’extension purrr. Plus précisément, dans notre situation, nous allons avoir recours à map2 qui permet de fournir deux vecteurs en entrée et d’appliquer une fonction ligne à ligne. On passera à map2 soit une fonction à utiliser telle quelle ou bien une formule décrivant une fonction personnalisée à la levée, ce que nous allons faire. Dans cette formule décrivant le calcul à effectuer, on utilisera .x pour se référer à l’élément du premier vecteur et à .y pour se référer au deuxième vecteur.
[[1]]
[1] 1.484439
[[2]]
[1] 0.9516872
[[3]]
[1] 0.8755191
[[4]]
[1] 1.141658Le résultat obtenu est une liste de 4 éléments, chaque élément contenu la borne inférieur des intervalles. Nous préférerions que la fonction nous retourne un vecteur de valeurs numériques (double) plutôt qu’une liste. Nous allons donc utiliser map2_dbl plutôt que map2.
[1] 1.4844385 0.9516872 0.8755191 1.1416584Nous y sommes presque. Il nous reste plus qu’à avoir recours à after_stat pour avoir accès aux numérateurs et dénominateurs calculés par stat_weighted_mean.
ggplot(bd) +
aes(
x = date, y = bd_distribuees / eleves_rencontres, weight = eleves_rencontres,
ymin = map2_dbl(after_stat(numerator), after_stat(denominator), ~ poisson.test(.x, .y) %>% pluck("conf.int", 1)),
ymax = map2_dbl(after_stat(numerator), after_stat(denominator), ~ poisson.test(.x, .y) %>% pluck("conf.int", 2)),
colour = type_etablissement, fill = type_etablissement
) +
geom_ribbon(stat = "weighted_mean", alpha = .5) +
geom_line(stat = "weighted_mean")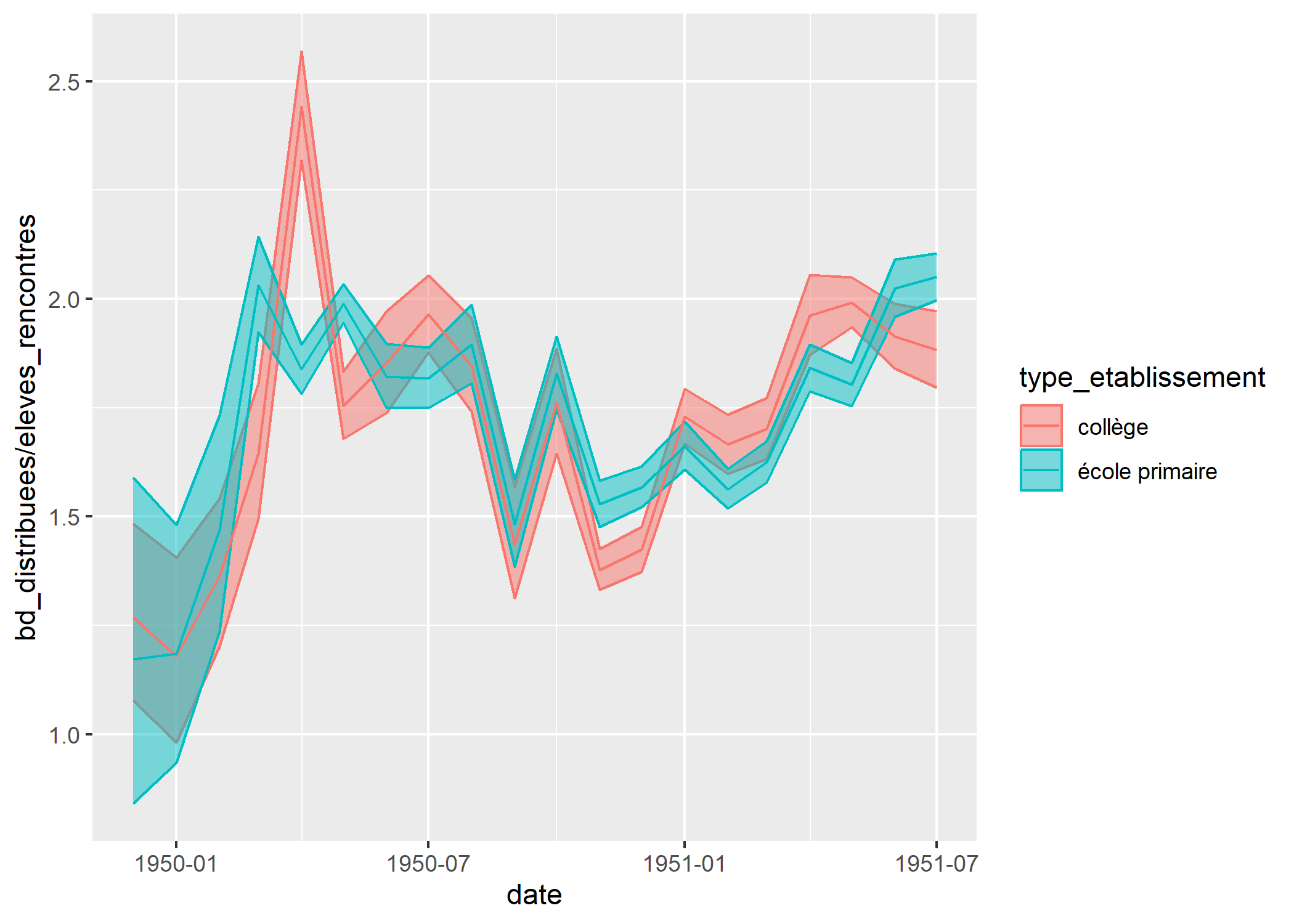
Faisons quelques ajustements pour une meilleur lisibilité : effaçons les limites supérieures et inférieures des rubans avec color = "transparent", augmentons la transparence des rubans avec alpha = .2 et épaississons les courbes principales avec size = 1.
p <- ggplot(bd) +
aes(
x = date, y = bd_distribuees / eleves_rencontres, weight = eleves_rencontres,
ymin = map2_dbl(after_stat(numerator), after_stat(denominator), ~ poisson.test(.x, .y) %>% pluck("conf.int", 1)),
ymax = map2_dbl(after_stat(numerator), after_stat(denominator), ~ poisson.test(.x, .y) %>% pluck("conf.int", 2)),
colour = type_etablissement, fill = type_etablissement
) +
geom_ribbon(stat = "weighted_mean", alpha = .25, color = "transparent") +
geom_line(stat = "weighted_mean", size = 1)
p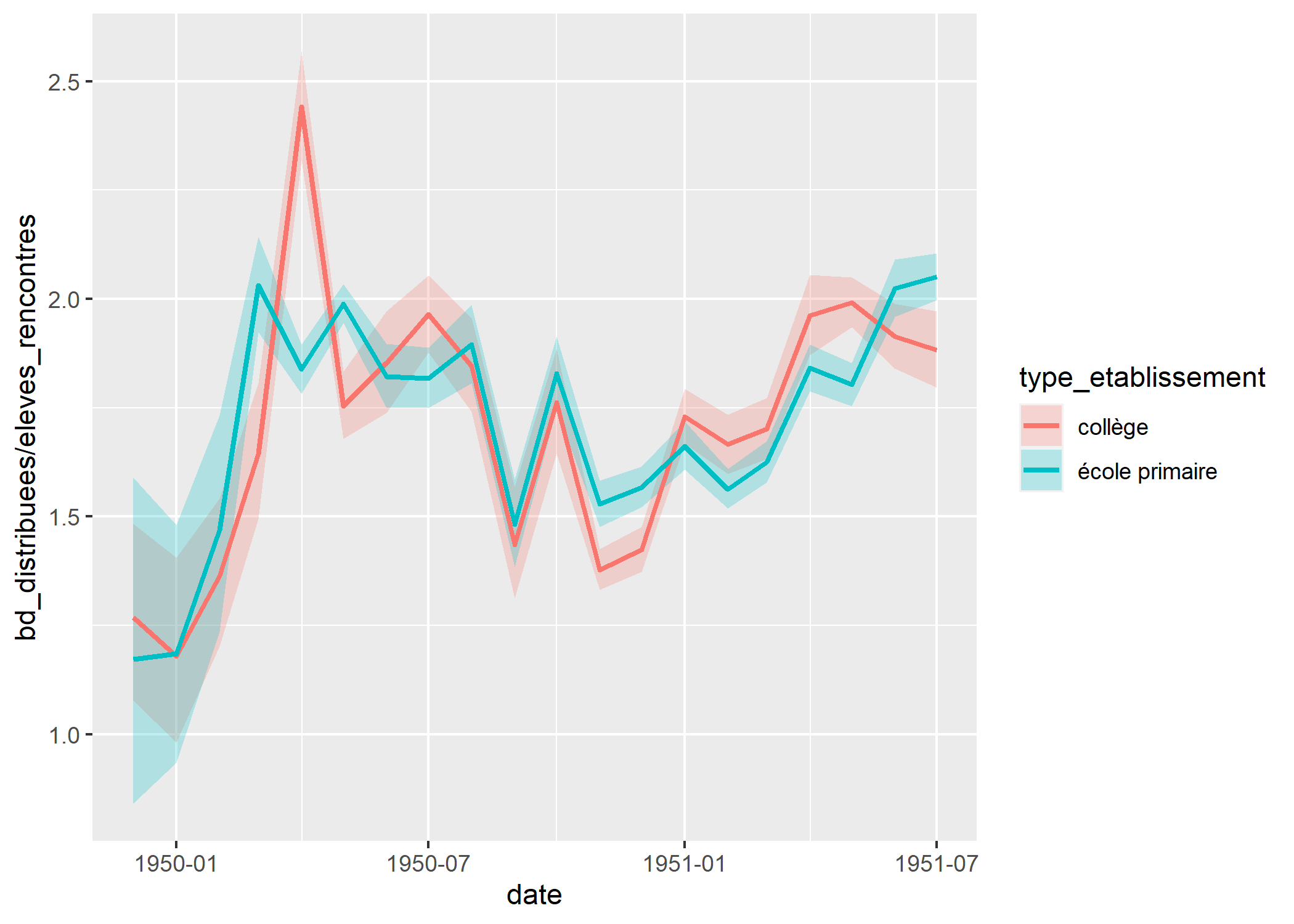
Comme tous les calculs sont réalisés à la volée, il est possible de définir simplement et rapidement des facettes pour séparer les résultats par pays.
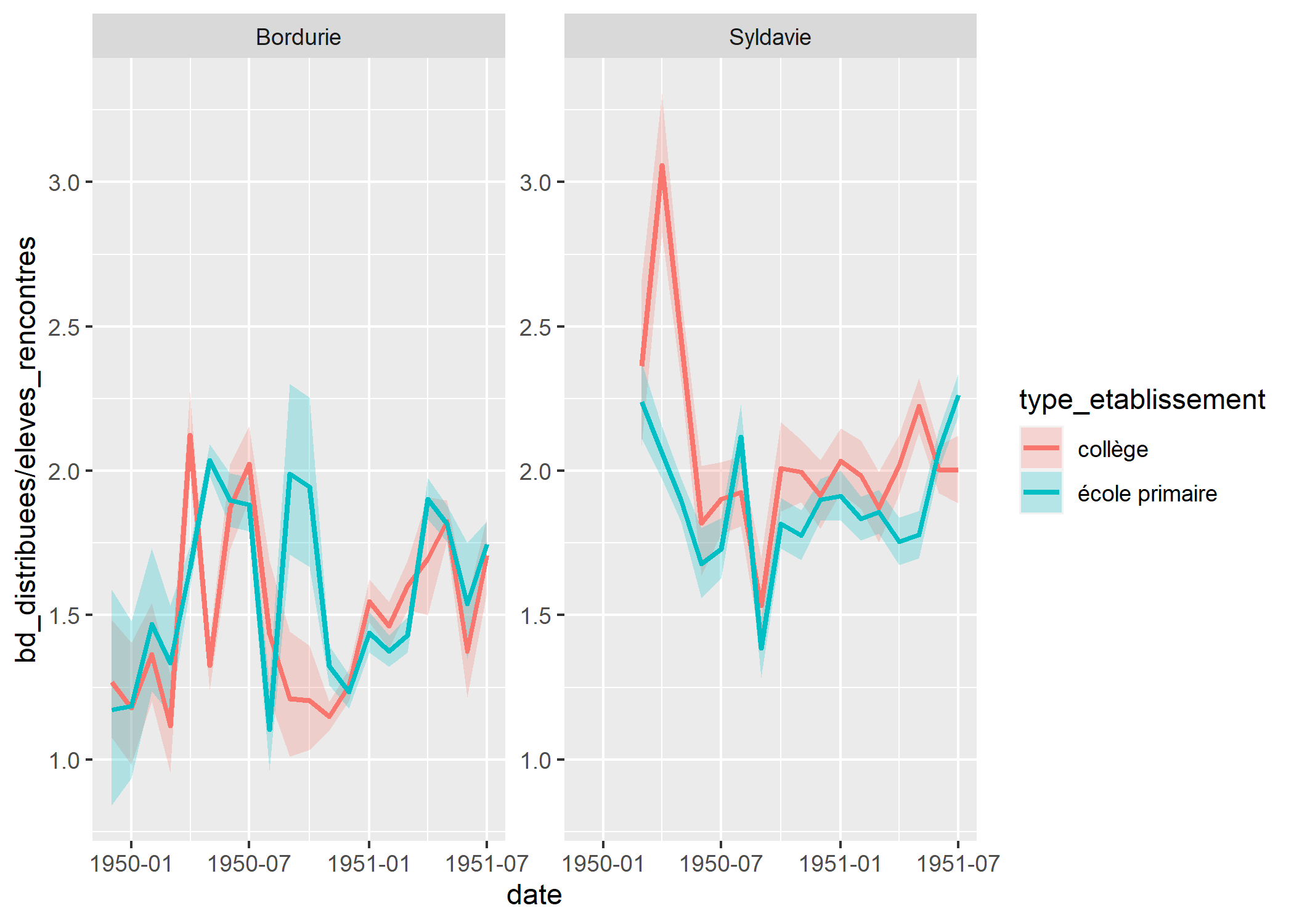
Faisons un peu d’habillage :
p <- p +
xlab("") + ylab("") + labs(fill = "", colour = "") +
ggtitle(
"Nombre moyen de bandes dessinées distribuées par élève",
subtitle = "par mois, type d'établissement et pays"
) +
scale_x_date(
date_labels = "%b\n%Y",
date_breaks = "3 months",
date_minor_breaks = "1 month",
guide = guide_axis_minor()
) +
scale_fill_bright() +
scale_colour_bright() +
theme_clean() +
theme(
legend.position = "bottom"
)
p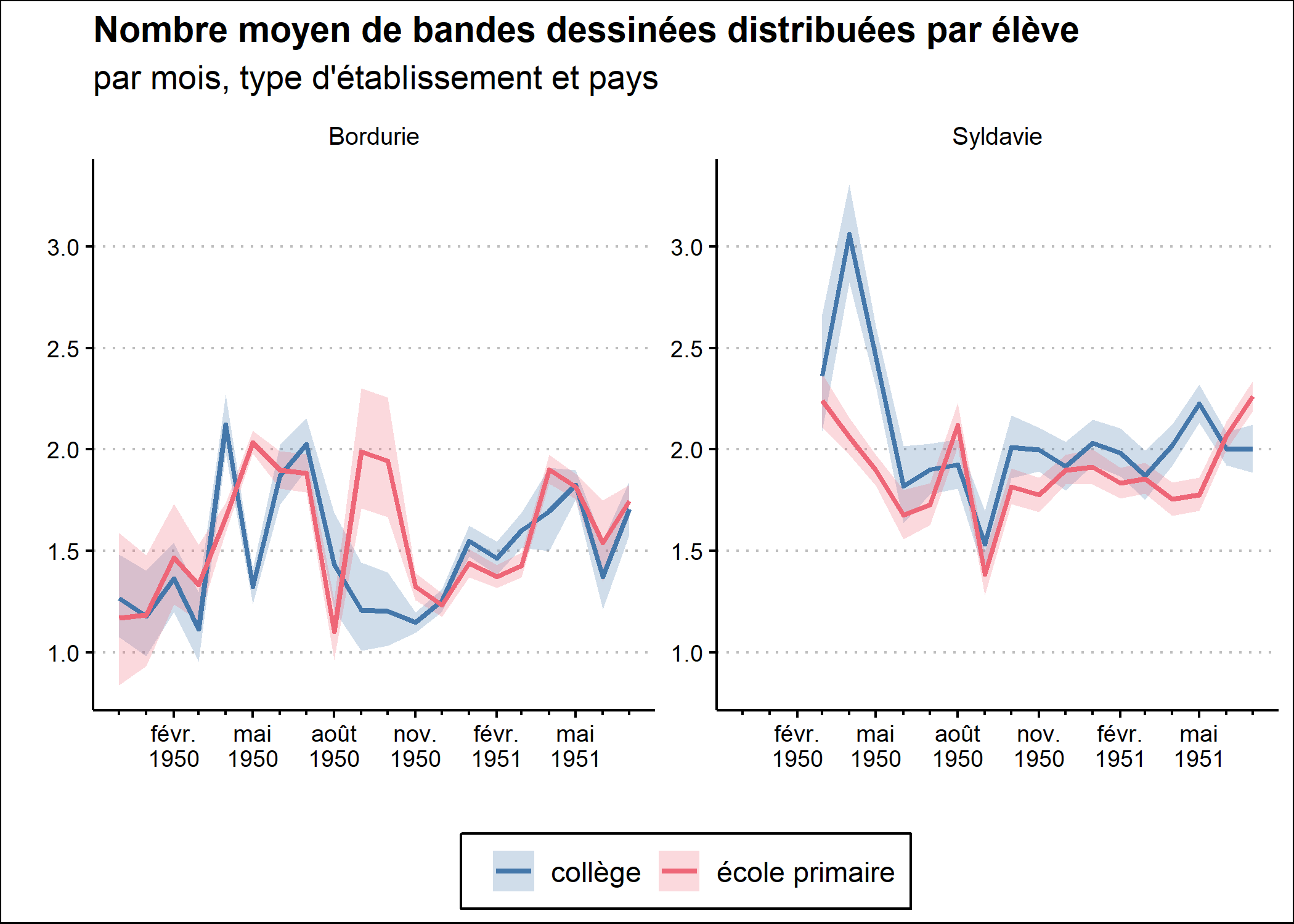
Voilà !
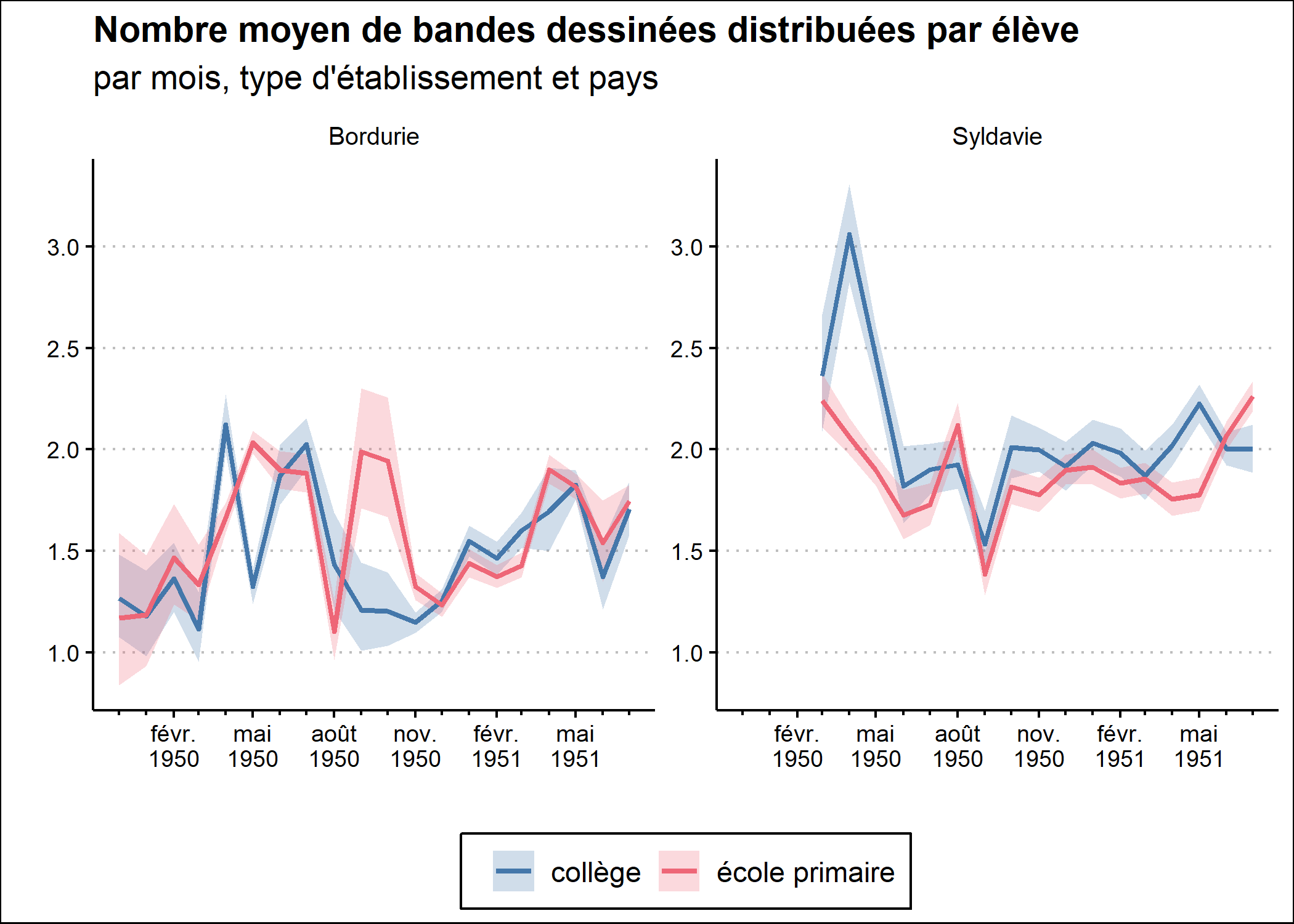
Le code final de notre graphique est donc :
library(ggthemes)
library(khroma)
library(ggh4x)
library(GGally)
library(lemon)
ggplot(bd) +
aes(
x = date, y = bd_distribuees / eleves_rencontres, weight = eleves_rencontres,
ymin = map2_dbl(after_stat(numerator), after_stat(denominator), ~ poisson.test(.x, .y) %>% pluck("conf.int", 1)),
ymax = map2_dbl(after_stat(numerator), after_stat(denominator), ~ poisson.test(.x, .y) %>% pluck("conf.int", 2)),
colour = type_etablissement, fill = type_etablissement
) +
geom_ribbon(stat = "weighted_mean", alpha = .25, color = "transparent") +
geom_line(stat = "weighted_mean", size = 1) +
facet_rep_grid(cols = vars(pays), repeat.tick.labels = TRUE) +
xlab("") +
ylab("") +
labs(fill = "", colour = "") +
ggtitle(
"Nombre moyen de bandes dessinées distribuées par élève",
subtitle = "par mois, type d'établissement et pays"
) +
scale_x_date(
date_labels = "%b\n%Y",
date_breaks = "3 months",
date_minor_breaks = "1 month",
guide = guide_axis_minor()
) +
scale_fill_bright() +
scale_colour_bright() +
theme_clean() +
theme(
legend.position = "bottom"
)
Pour aller plus loin
On pourra jeter un œil au chapitre Étendre ggplot2.