

Analyse des correspondances multiples (ACM)
Une version actualisée de ce chapitre est disponible sur guide-R : Analyse factorielle
Ce chapitre est évoqué dans le webin-R #11 (Analyse des Correspondances Multiples sur YouTube.
Il existe plusieurs techniques d’analyse factorielle dont les plus courantes sont l’analyse en composante principale (ACP) portant sur des variables quantitatives, l’analyse factorielle des correspondances (AFC) portant sur deux variables qualitatives et l’analyse des correspondances multiples (ACM) portant sur plusieurs variables qualitatives (il s’agit d’une extension de l’AFC). Pour combiner des variables à la fois quantitatives et qualitatives, on pourra avoir recours à l’analyse factorielle avec données mixtes.
Bien que ces techniques soient disponibles dans les extensions standards de R, il est souvent préférable d’avoir recours à deux autres extensions plus complètes, ade4 et FactoMineR, chacune ayant ses avantages et des possibilités différentes. Voici les fonctions les plus fréquentes :
| Analyse | Variables | Fonction standard | Fonction ade4 |
Fonctions FactoMineR |
|---|---|---|---|---|
| ACP | plusieurs variables quantitatives | princomp |
dudi.pca |
PCA |
| AFC | deux variables qualitatives | corresp |
dudi.coa |
CA |
| ACM | plusieurs variables qualitatives | mca |
dudi.acm |
MCA |
| Analyse mixte | plusieurs variables quantitatives et/ou qualitatives | — | dudi.mix |
FAMD |
Dans la suite de ce chapitre, nous n’arboderons que l’analyse des correspondances multiples (ACM).
On trouvera également de nombreux supports de cours en français sur l’analyse factorielle sur le site de François Gilles Carpentier : http://geai.univ-brest.fr/~carpenti/.
Principe général
L’analyse des correspondances multiples est une technique descriptive visant à résumer l’information contenu dans un grand nombre de variables afin de faciliter l’interprétention des corrélations existantes entre ces différentes variables. On cherche à savoir quelles sont les modalités corrélées entre elles.
L’idée générale est la suivante1. L’ensemble des individus peut être représenté dans un espace à plusieurs dimensions où chaque axe représente les différentes variables utilisées pour décrire chaque individu. Plus précisément, pour chaque variable qualitative, il y a autant d’axes que de modalités moins un. Ainsi il faut trois axes pour décrire une variable à quatre modalités. Un tel nuage de points est aussi difficile à interpréter que de lire directement le fichier de données. On ne voit pas les corrélations qu’il peut y avoir entre modalités, par exemple qu’aller au cinéma est plus fréquent chez les personnes habitant en milieu urbain. Afin de mieux représenter ce nuage de points, on va procéder à un changement de systèmes de coordonnées. Les individus seront dès lors projetés et représentés sur un nouveau système d’axe. Ce nouveau système d’axes est choisis de telle manière que la majorité des variations soit concentrées sur les premiers axes. Les deux-trois premiers axes permettront d’expliquer la majorité des différences observées dans l’échantillon, les autres axes n’apportant qu’une faible part additionnelle d’information. Dès lors, l’analyse pourra se concentrer sur ses premiers axes qui constitueront un bon résumé des variations observables dans l’échantillon.
Avant toute ACM, il est indispensable de réaliser une analyse préliminaire de chaque variable, afin de voir si toutes les classes sont aussi bien représentées ou s’il existe un déséquilibre. L’ACM est sensible aux effectifs faibles, aussi il est préférable de regrouper les classes peu représentées le cas échéant.
ACM avec ade4
Si l’extension ade4 n’est pas présente sur votre PC, il vous faut l’installer :
Dans tous les cas, il faut penser à la charger en mémoire :
Comme précédemment, nous utiliserons le fichier de données hdv2003 fourni avec l’extension questionr.
En premier lieu, comme dans le chapitre sur la régression logistique, nous allons créer une variable groupe d’âges et regrouper les modalités de la variable « niveau d’étude ».
d$grpage <- cut(d$age, c(16, 25, 45, 65, 93), right = FALSE, include.lowest = TRUE)
d$etud <- d$nivetud
levels(d$etud) <- c(
"Primaire", "Primaire", "Primaire", "Secondaire", "Secondaire",
"Technique/Professionnel", "Technique/Professionnel", "Supérieur"
)Ensuite, nous allons créer un tableau de données ne contenant que les variables que nous souhaitons prendre en compte pour notre analyse factorielle.
d2 <- d[, c("grpage", "sexe", "etud", "peche.chasse", "cinema", "cuisine", "bricol", "sport", "lecture.bd")]Le calcul de l’ACM se fait tout simplement avec la fonction dudi.acm.
Par défaut, la fonction affichera le graphique des valeurs propres de chaque axe (nous y reviendrons) et vous demandera le nombre d’axes que vous souhaitez conserver dans les résultats. Le plus souvent, cinq axes seront largement plus que suffisants. Vous pouvez également éviter cette étape en indiquant directement à dudi.acm de vous renvoyer les cinq premiers axes ainsi :
Si vous souhaitez explorer visuellement et interacticement les résultats, vous pouvez utiliser l’extension explor et sa fonction homonyme explor.
Le graphique des valeurs propres peut être reproduit avec screeplot :
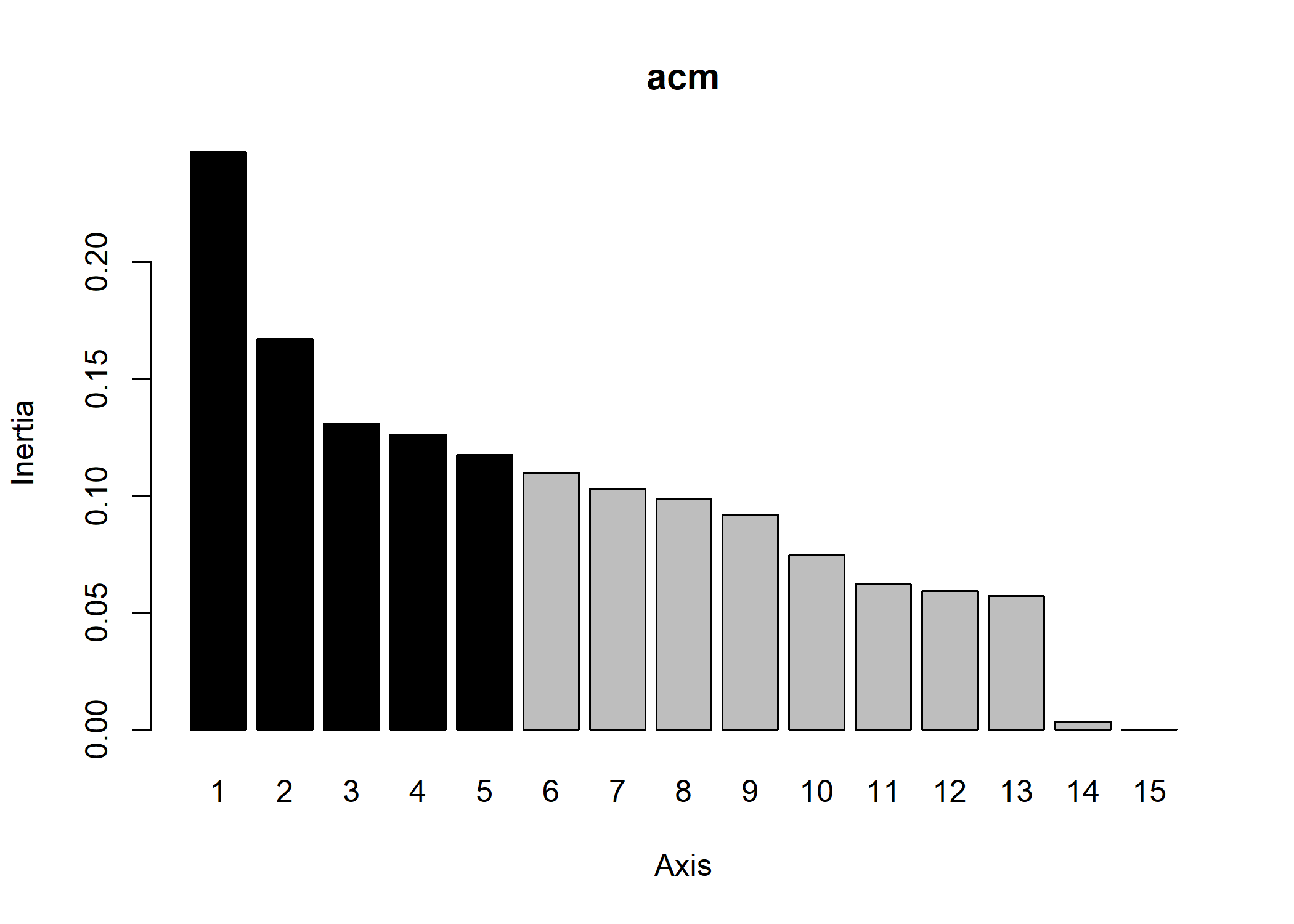
Pour des grahiques reposant sur ggplot2, on pourra avoir recours à l’extension factoextra qui fournit plusieurs fonctions graphiques dont fviz_screeplot
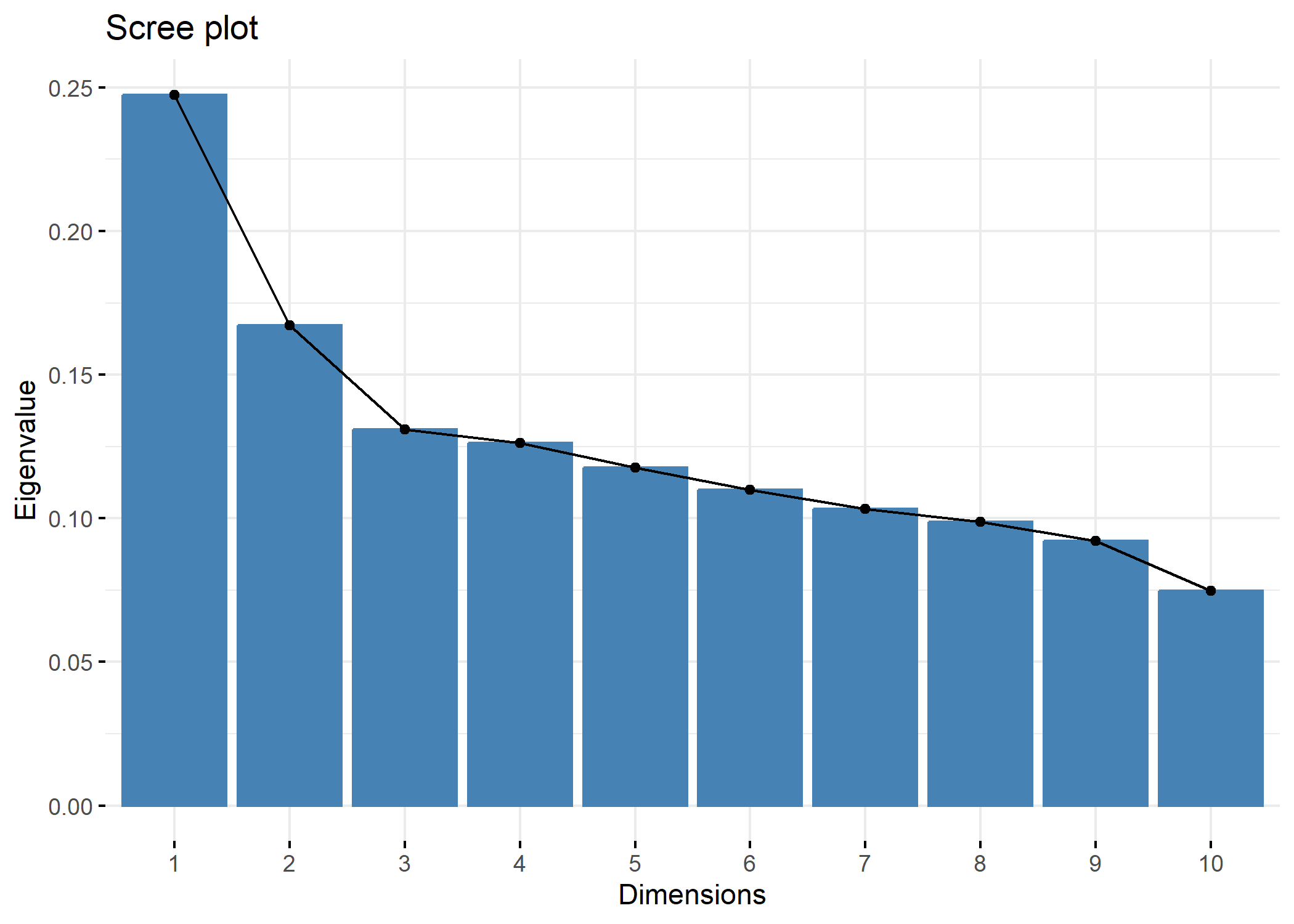
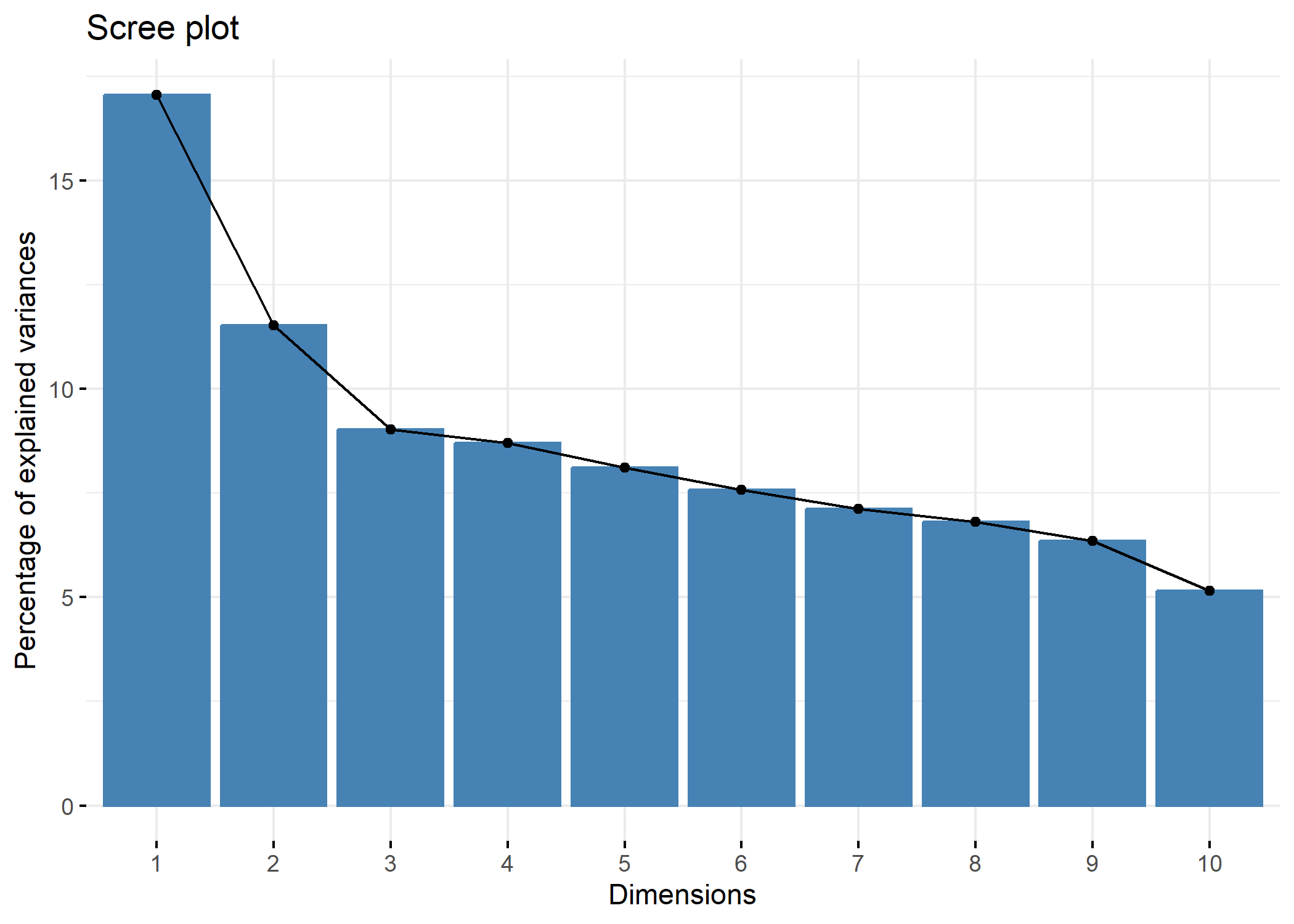
Les mêmes valeurs pour les premiers axes s’obtiennent également avec summary. On pourra également avoir recours à la fonction inertia.dudi pour l’ensemble des axes.
Class: acm dudi
Call: dudi.acm(df = d2, scannf = FALSE, nf = 5)
Total inertia: 1.451
Eigenvalues:
Ax1 Ax2 Ax3 Ax4 Ax5
0.2474 0.1672 0.1309 0.1263 0.1176
Projected inertia (%):
Ax1 Ax2 Ax3 Ax4 Ax5
17.055 11.525 9.022 8.705 8.109
Cumulative projected inertia (%):
Ax1 Ax1:2 Ax1:3 Ax1:4 Ax1:5
17.06 28.58 37.60 46.31 54.42
(Only 5 dimensions (out of 15) are shown)Inertia information:
Call: inertia.dudi(x = acm)
Decomposition of total inertia:
inertia cum cum(%)
Ax1 0.2474360 0.2474 17.06
Ax2 0.1671951 0.4146 28.58
Ax3 0.1308832 0.5455 37.60
Ax4 0.1262915 0.6718 46.31
Ax5 0.1176380 0.7894 54.42
Ax6 0.1099985 0.8994 62.00
Ax7 0.1032282 1.0027 69.11
Ax8 0.0986748 1.1013 75.91
Ax9 0.0920695 1.1934 82.26
Ax10 0.0747282 1.2681 87.41
Ax11 0.0623488 1.3305 91.71
Ax12 0.0593251 1.3898 95.80
Ax13 0.0573240 1.4471 99.75
Ax14 0.0035264 1.4507 99.99
Ax15 0.0001104 1.4508 100.00L’inertie totale est de 1,451 et l’axe 1 en explique 0,1474 soit 17 %. L’inertie projetée cumulée nous indique que les deux premiers axes expliquent à eux seuls 29 % des variations observées dans notre échantillon.
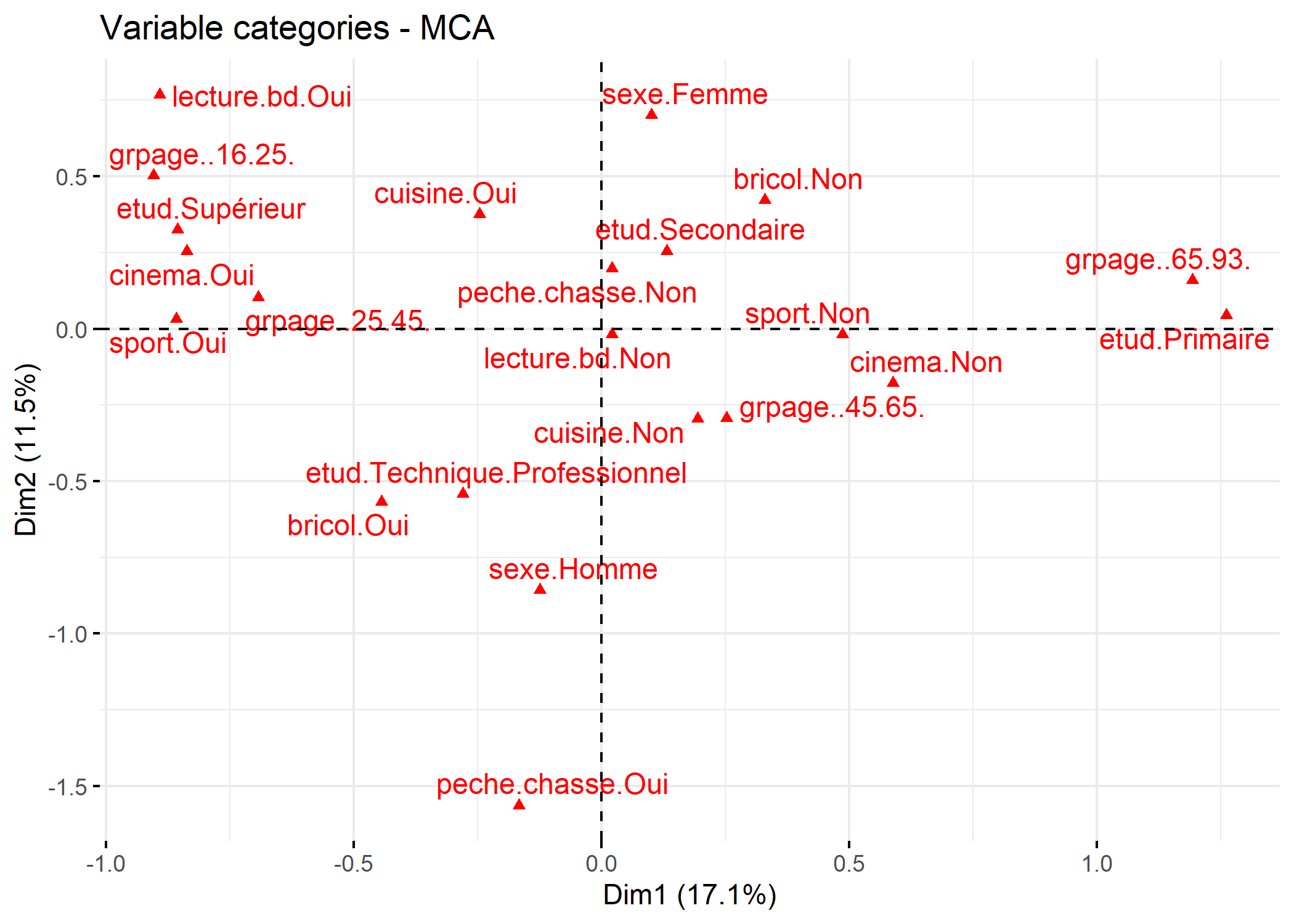
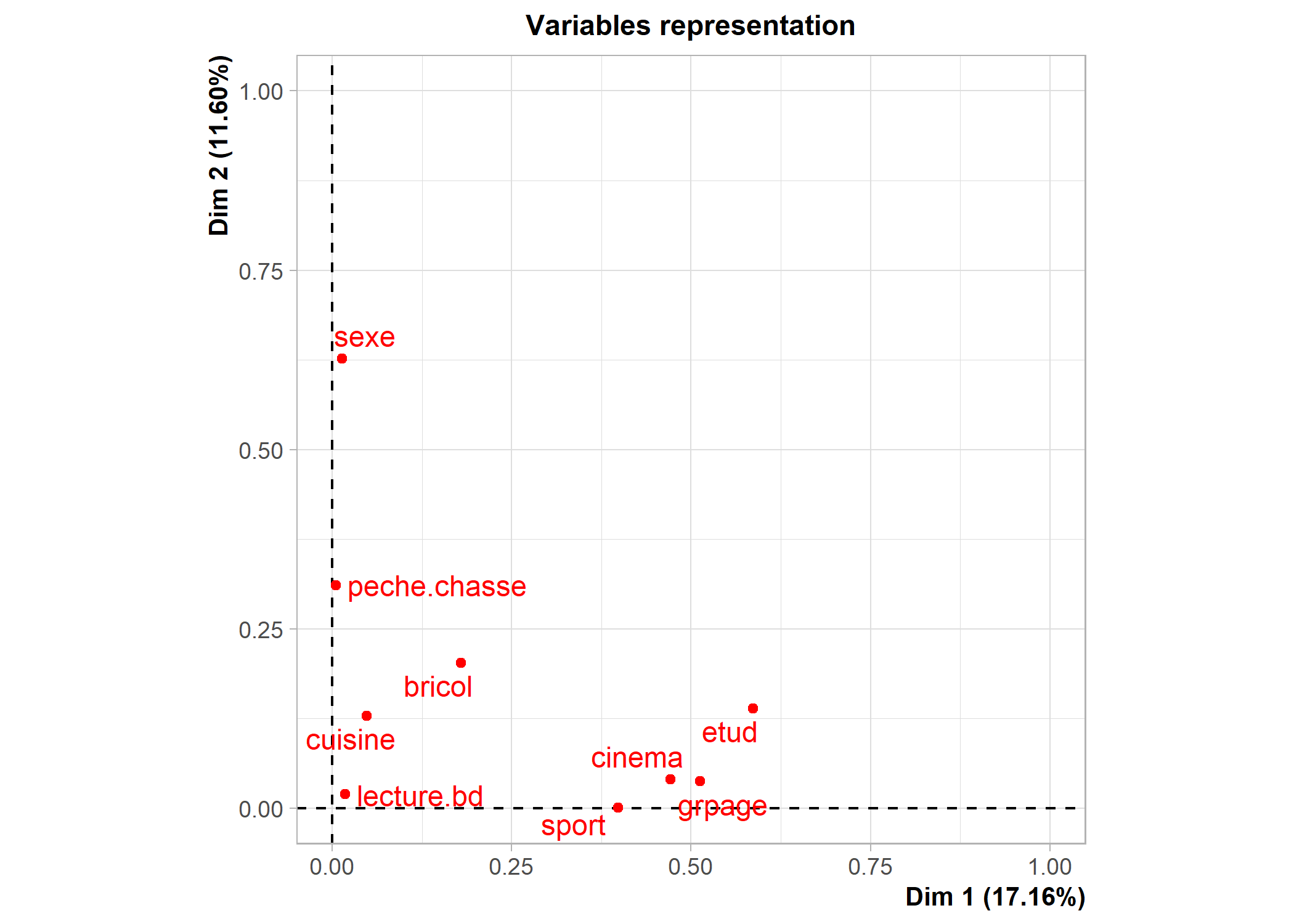
Pour comprendre la signification des différents axes, il importe d’identifier quelles sont les variables/ modalités qui contribuent le plus à chaque axe. Une première représentation graphique est le cercle de corrélation des modalités. Pour cela, on aura recours à s.corcicle. On indiquera d’abord acm$co si l’on souhaite représenter les modalités ou acm$li si l’on souhaite représenter les individus. Les deux chiffres suivant indiquent les deux axes que l’on souhaite afficher (dans le cas présent les deux premiers axes). Enfin, le paramètre clabel permet de modifier la taille des étiquettes.
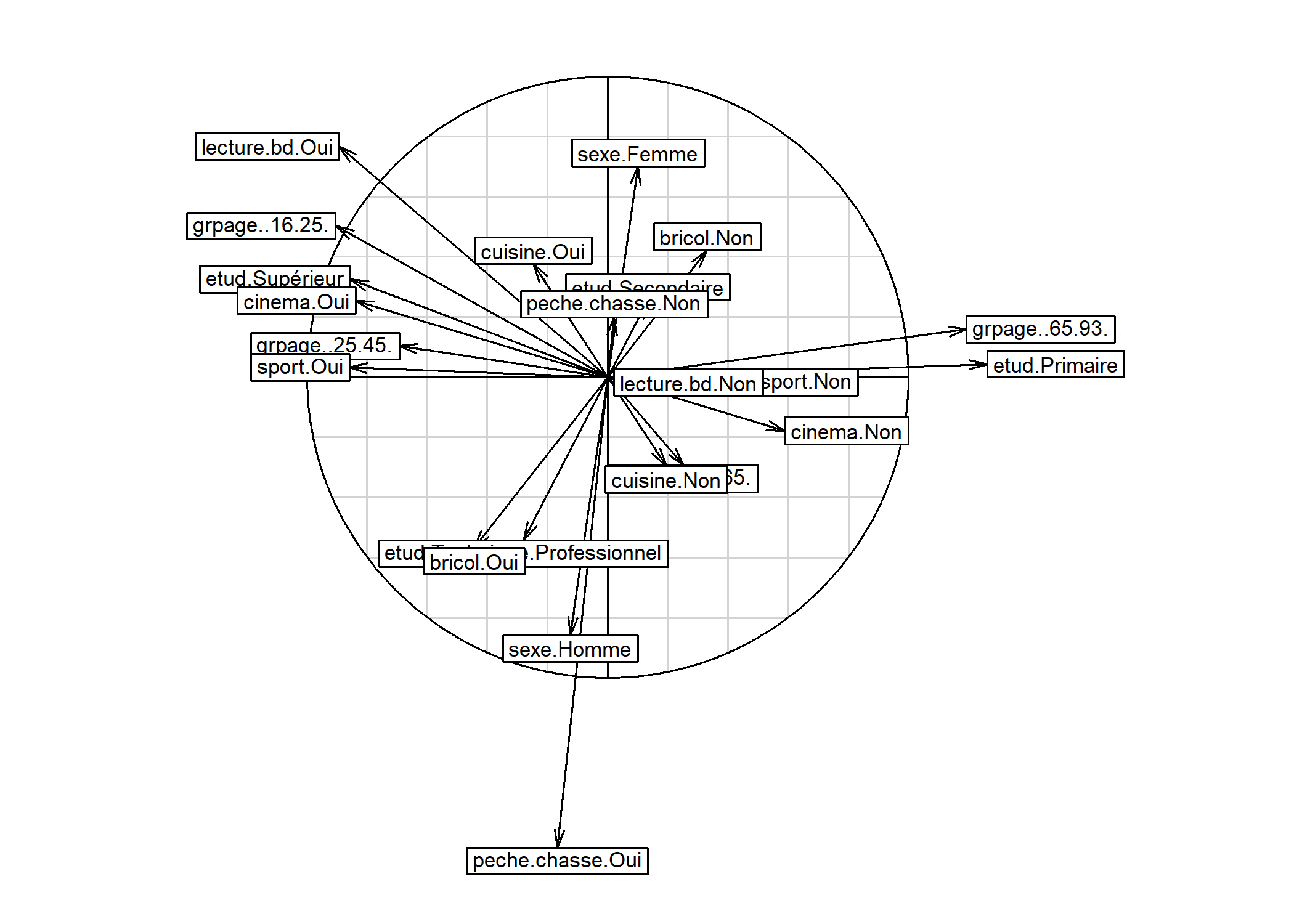
Il est aussi possible d’utiliser fviz_mca_var de factoextra. L’option repel = TRUE permets d’éviter que les étiquettes ne se superposent.
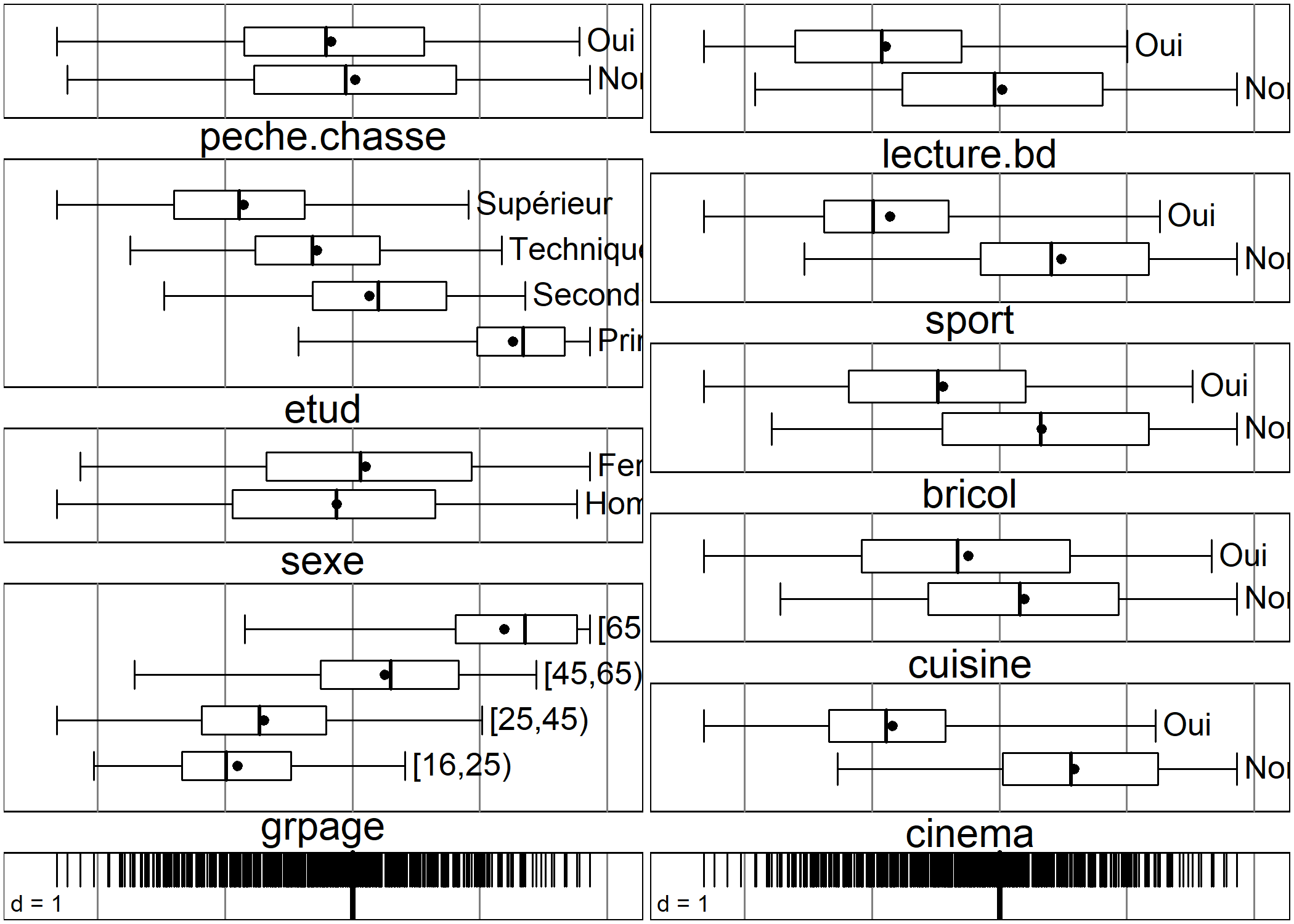
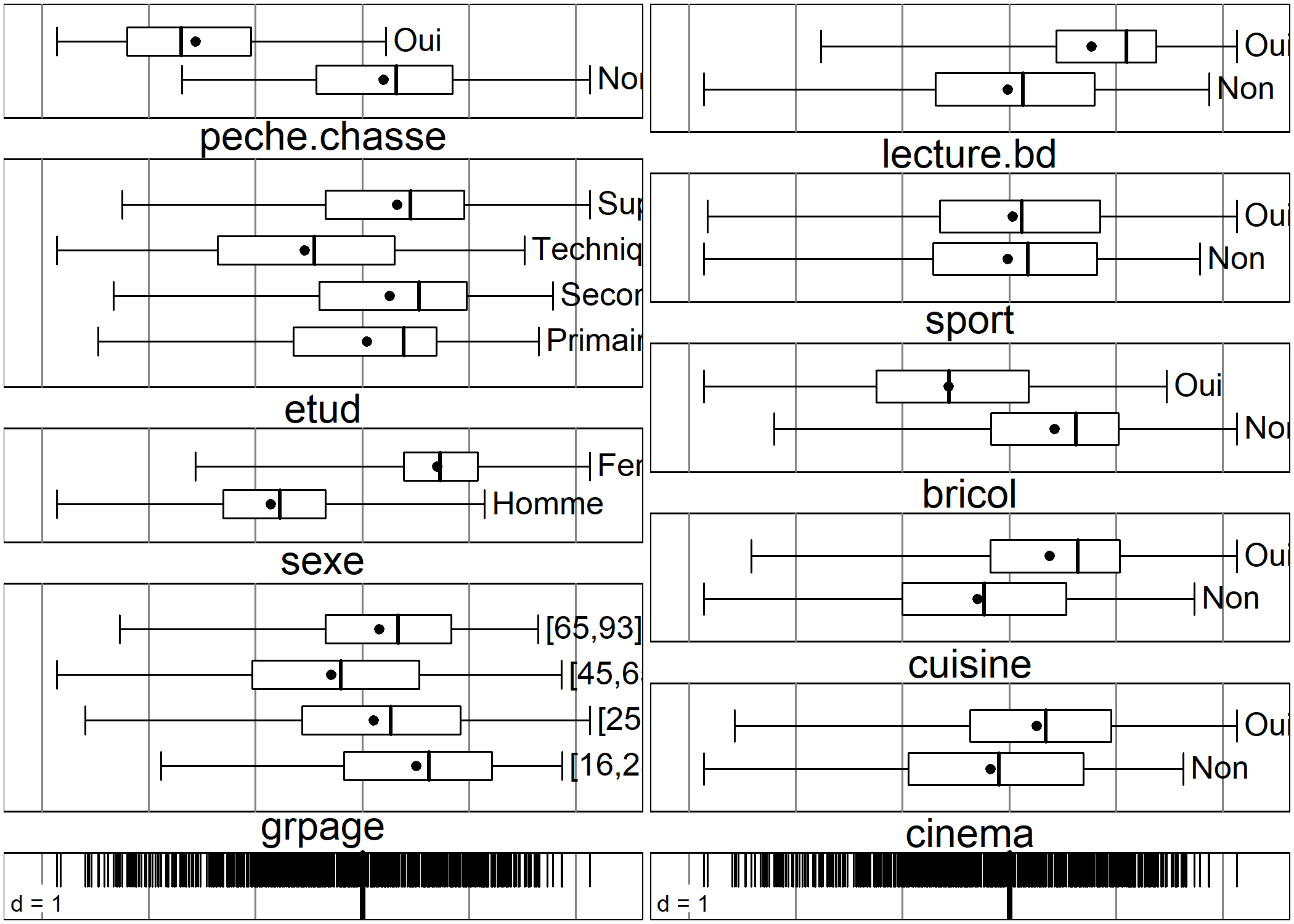
On pourra avoir également recours à boxplot pour visualiser comment se répartissent les modalités de chaque variable sur un axe donné2.
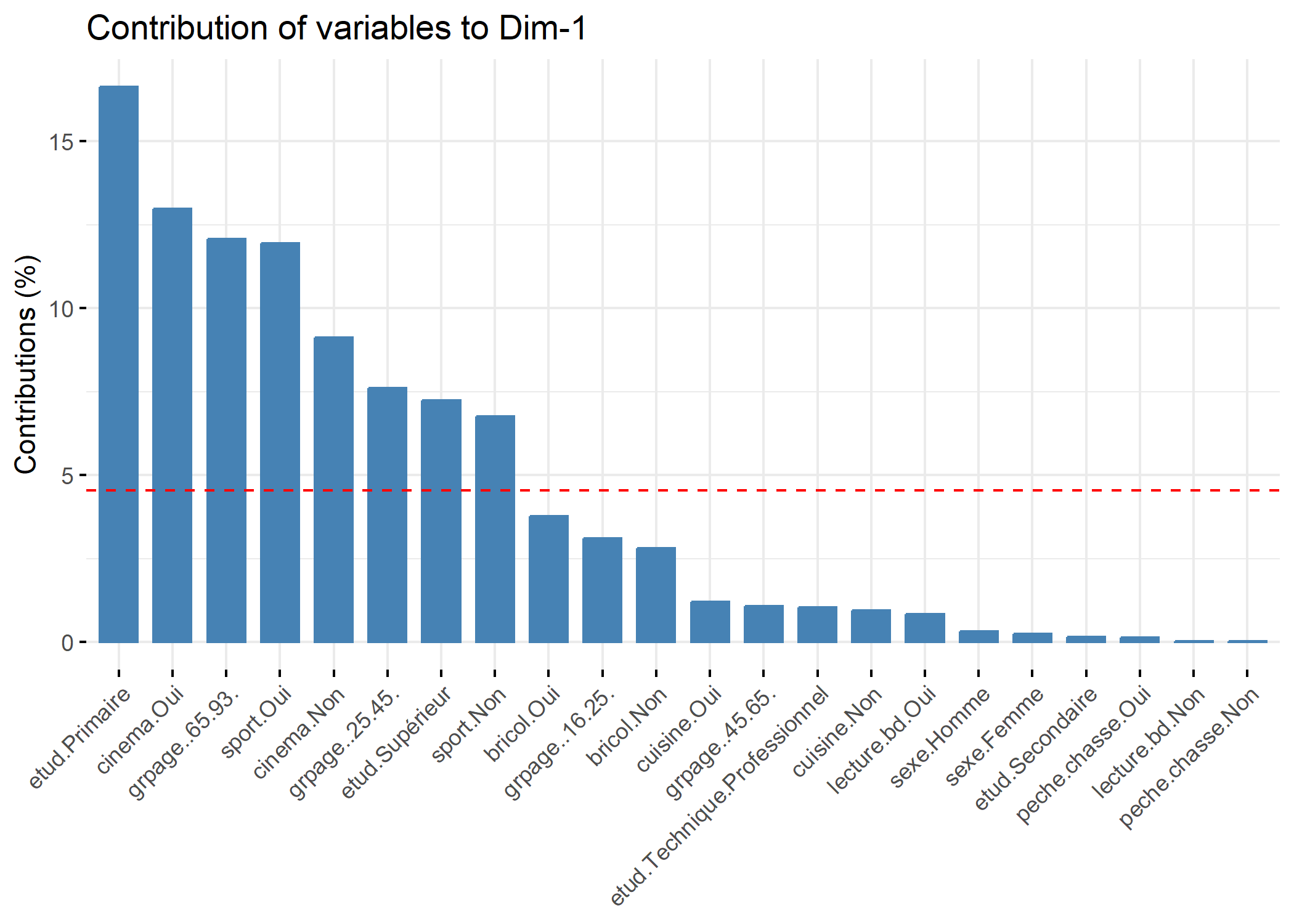
La fonction fviz_contrib de factoextra peut être utilisée pour représenter la contribution des différentes variables sur un axe.
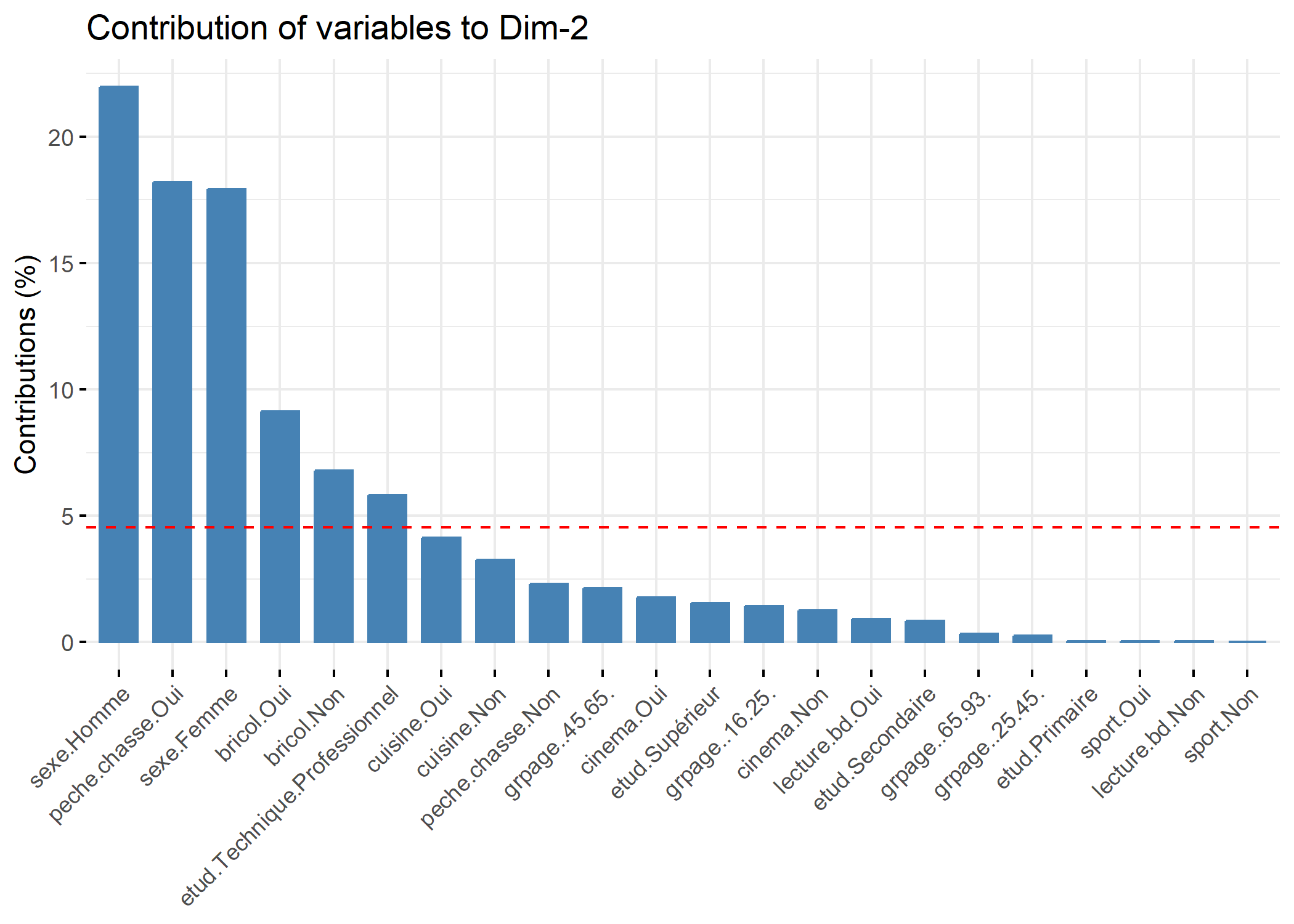
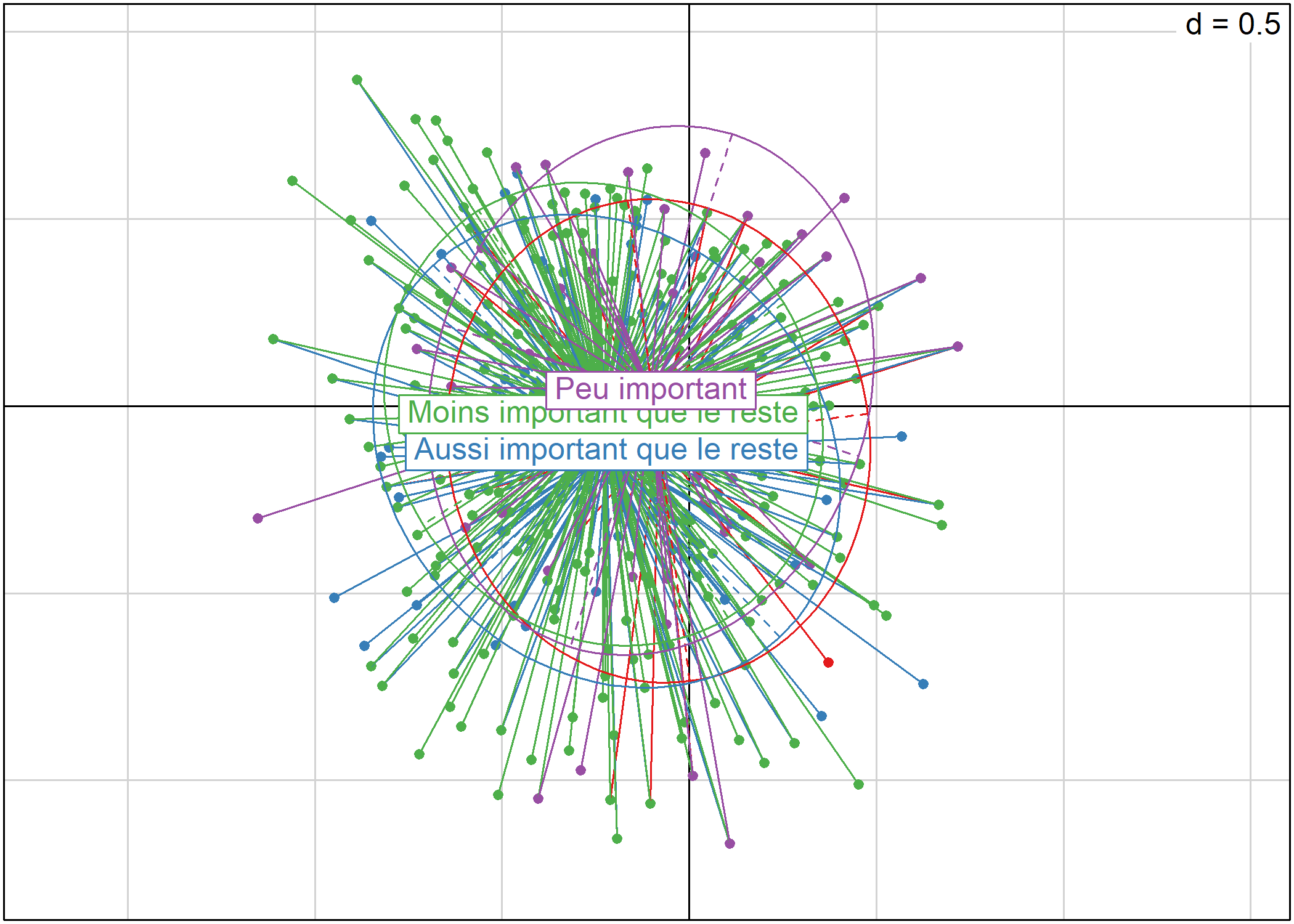
Le tableau acm$cr contient les rapports de corrélation (variant de 0 à 1) entre les variables et les axes choisis au départ de l’ACM. Pour représenter graphiquement ces rapports, utiliser la fonction barplot ainsi : barplot(acm$cr[,num],names.arg=row.names( acm$cr),las=2) où num est le numéro de l’axe à représenter. Pour l’interprétation des axes, se concentrer sur les variables les plus structurantes, c’est-à-dire dont le rapport de corrélation est le plus proche de 1.
par(mfrow = c(2, 2))
for (i in 1:4) barplot(acm$cr[, i], names.arg = row.names(acm$cr), las = 2, main = paste("Axe", i))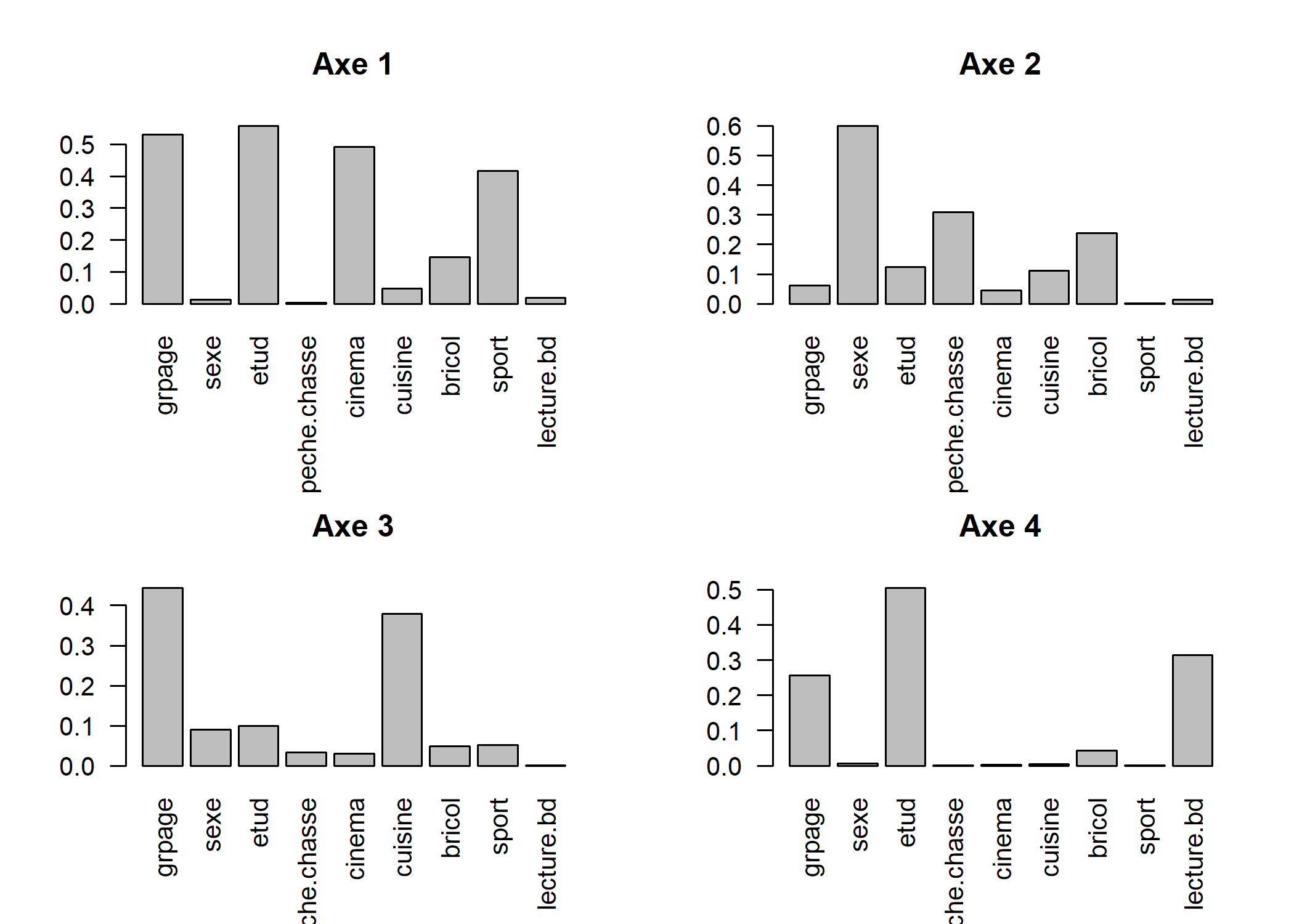
Le paramètre mfrow de la fonction par permet d’indiquer à R que l’on souhaite afficher plusieurs graphiques sur une seule et même fenêtre, plus précisément que l’on souhaite diviser la fenêtre en deux lignes et deux colonnes.
Dans l’exemple précédent, après avoir produit notre graphique, nous avons réinitilisé cette valeur à c(1, 1) (un seul graphique par fenêtre) pour ne pas affecter les prochains graphiques que nous allons produire.
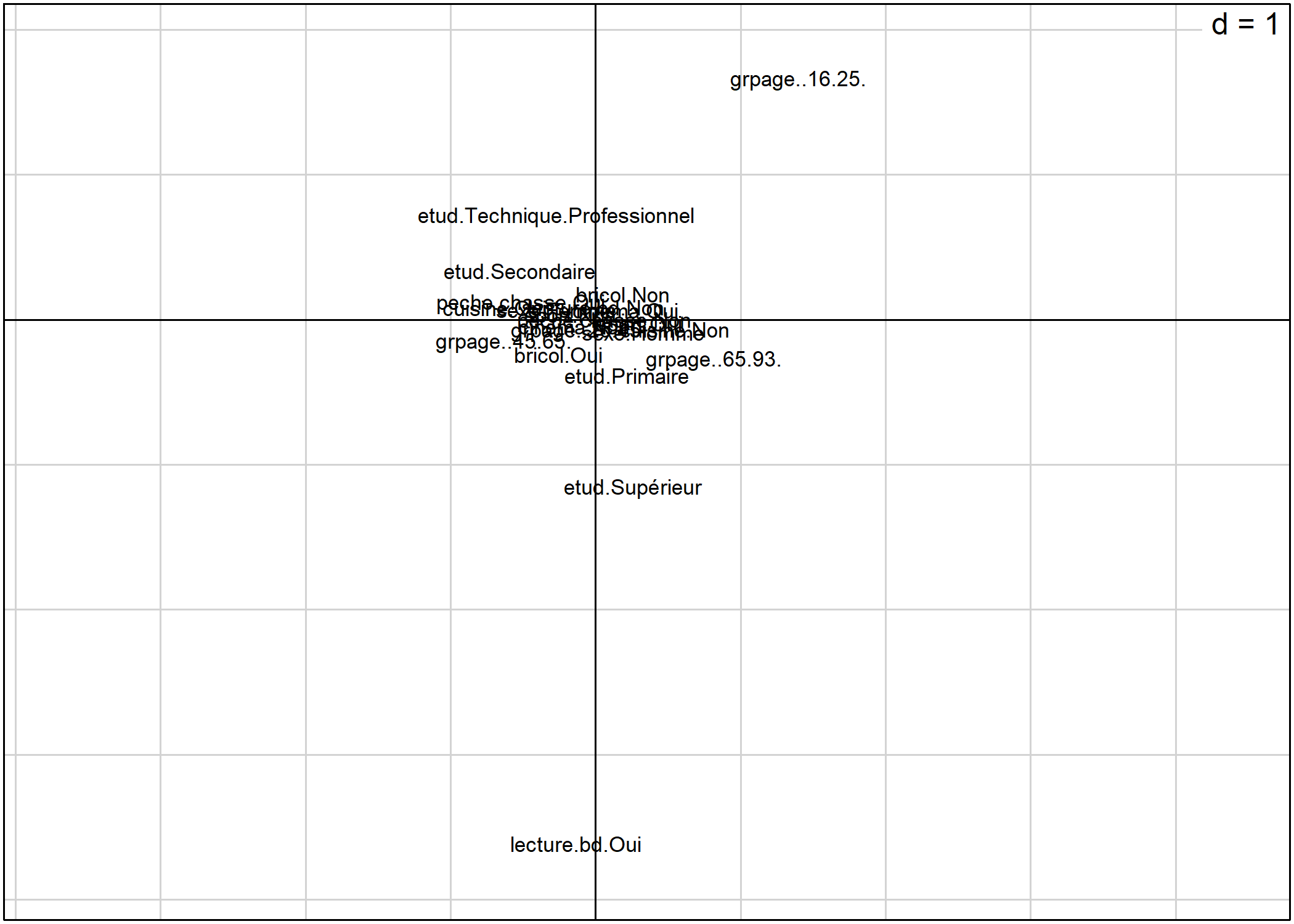
Pour représenter, les modalités dans le plan factoriel, on utilisera la fonction s.label. Par défaut, les deux premiers axes sont représentés.
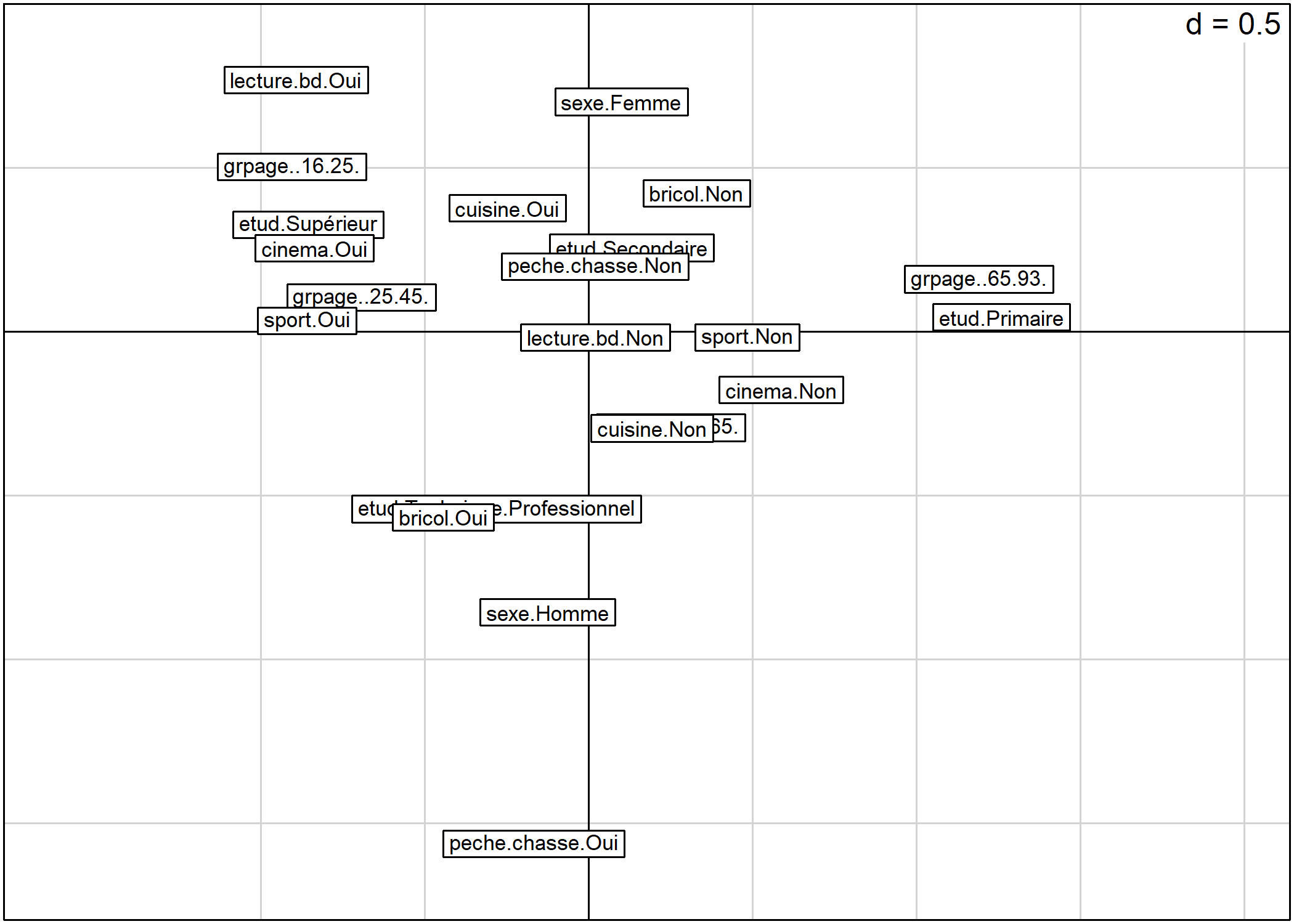
Il est bien sur possible de préciser les axes à représenter. L’argument boxes permet quant à lui d’indiquer si l’on souhaite tracer une boîte pour chaque modalité.
Bien entendu, on peut également représenter les individus. En indiquant clabel=0 (une taille nulle pour les étiquettes), s.label remplace chaque observation par un symbole qui peut être spécifié avec pch.
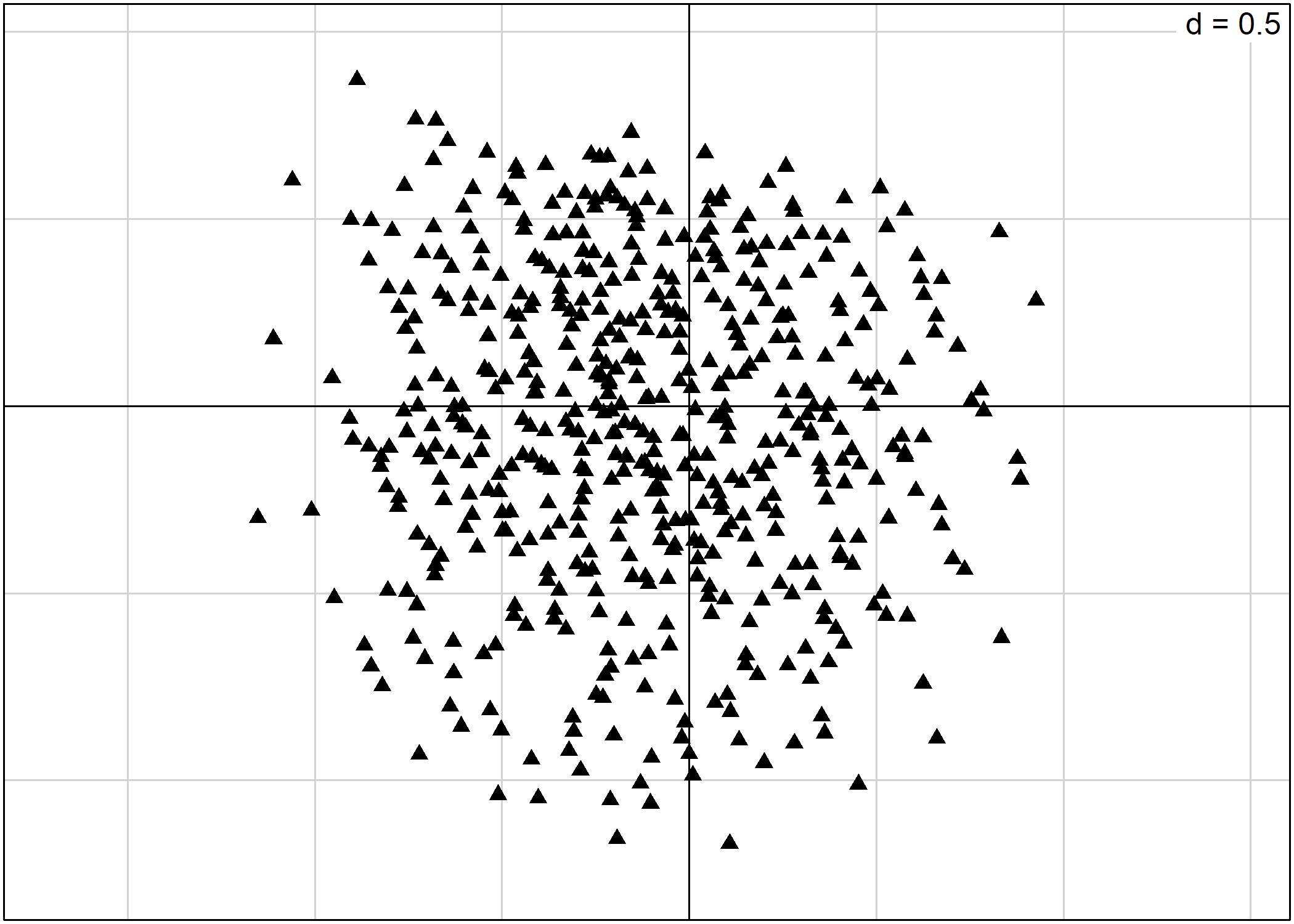
L’agument pch permet de spécifier le symbole à utiliser. Il peut prendre soit un nombre entier compris entre 0 et 25, soit un charactère textuel.

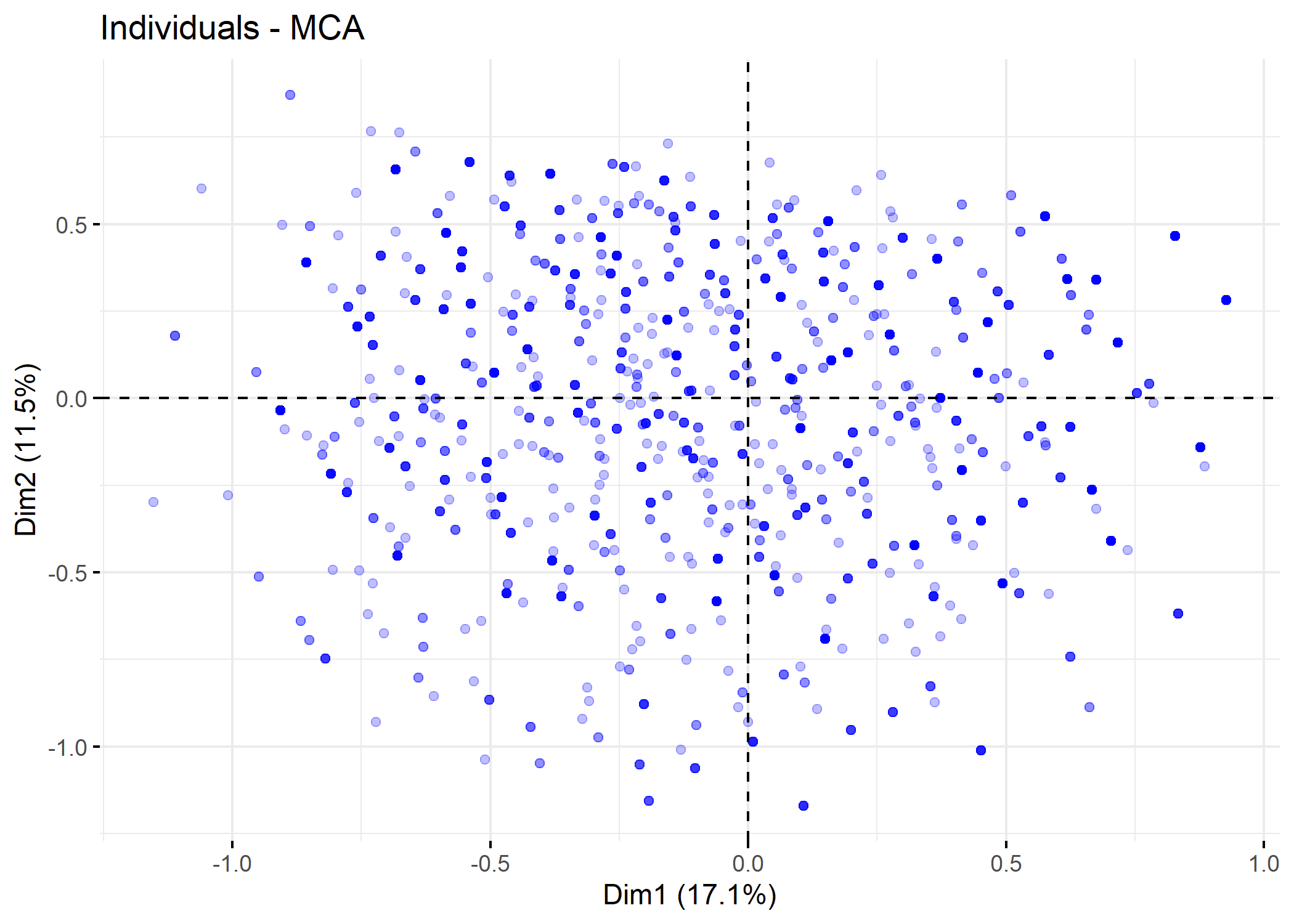
Il est également possible d’avoir recours à fviz_mca_ind de factoextra. geom = "point" permets de de ne réprésenter que les points sans leur étiquette. alpha.ind = .25 permets d’appliquer une transparance.
Lorsque l’on réalise une ACM, il n’est pas rare que plusieurs observations soient identiques, c’est-à-dire correspondent à la même combinaison de modalités. Dès lors, ces observations seront projetées sur le même point dans le plan factoriel. Une représentation classique des observations avec s.label ne permettra pas de rendre compte les effectifs de chaque point.
Le package JLutils, disponible seulement sur GitHub, propose une fonction s.freq représentant chaque point par un carré proportionnel au nombre d’individus.
Pour installer JLutils, on aura recours au package devtools et à sa fonction install_github :
La fonction s.freq s’emploie de manière similaire aux autres fonctions graphiques de ade4. Le paramètre csize permet d’ajuster la taille des carrés.
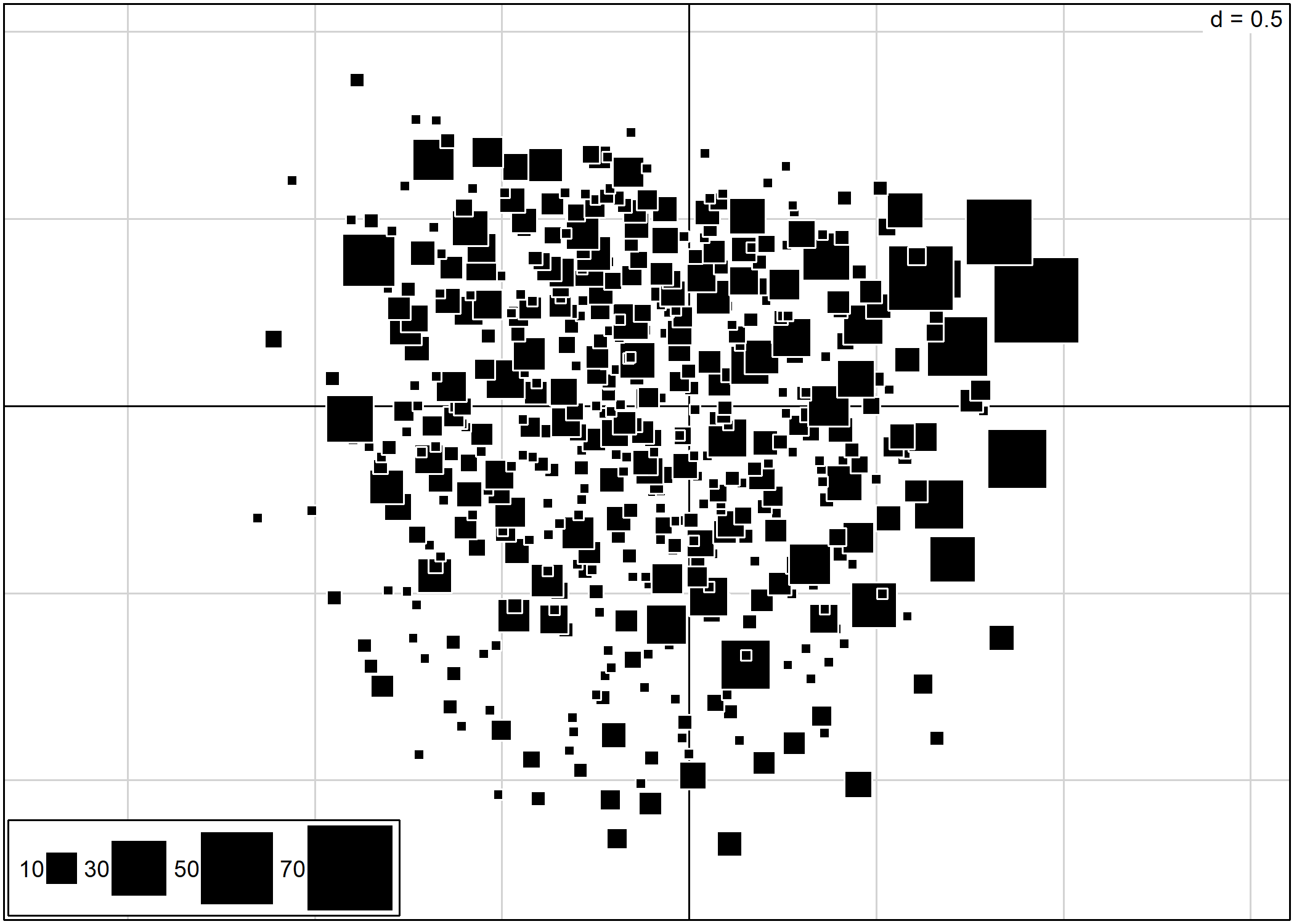
L’interprétation est tout autre, non ?
Gaston Sanchez propose un graphique amélioré des modalités dans le plan factoriel, avec notamment de coubes de densité, à cette adresse : http://rpubs.com/gaston/MCA.
La fonction s.value permet notamment de représenter un troisième axe factoriel. Dans l’exemple ci-après, nous projettons les individus selon les deux premiers axes factoriels. La taille et la couleur des carrés dépendent pour leur part de la coordonnée des individus sur le troisième axe factoriel. Le paramètre csi permet d’ajuster la taille des carrés.
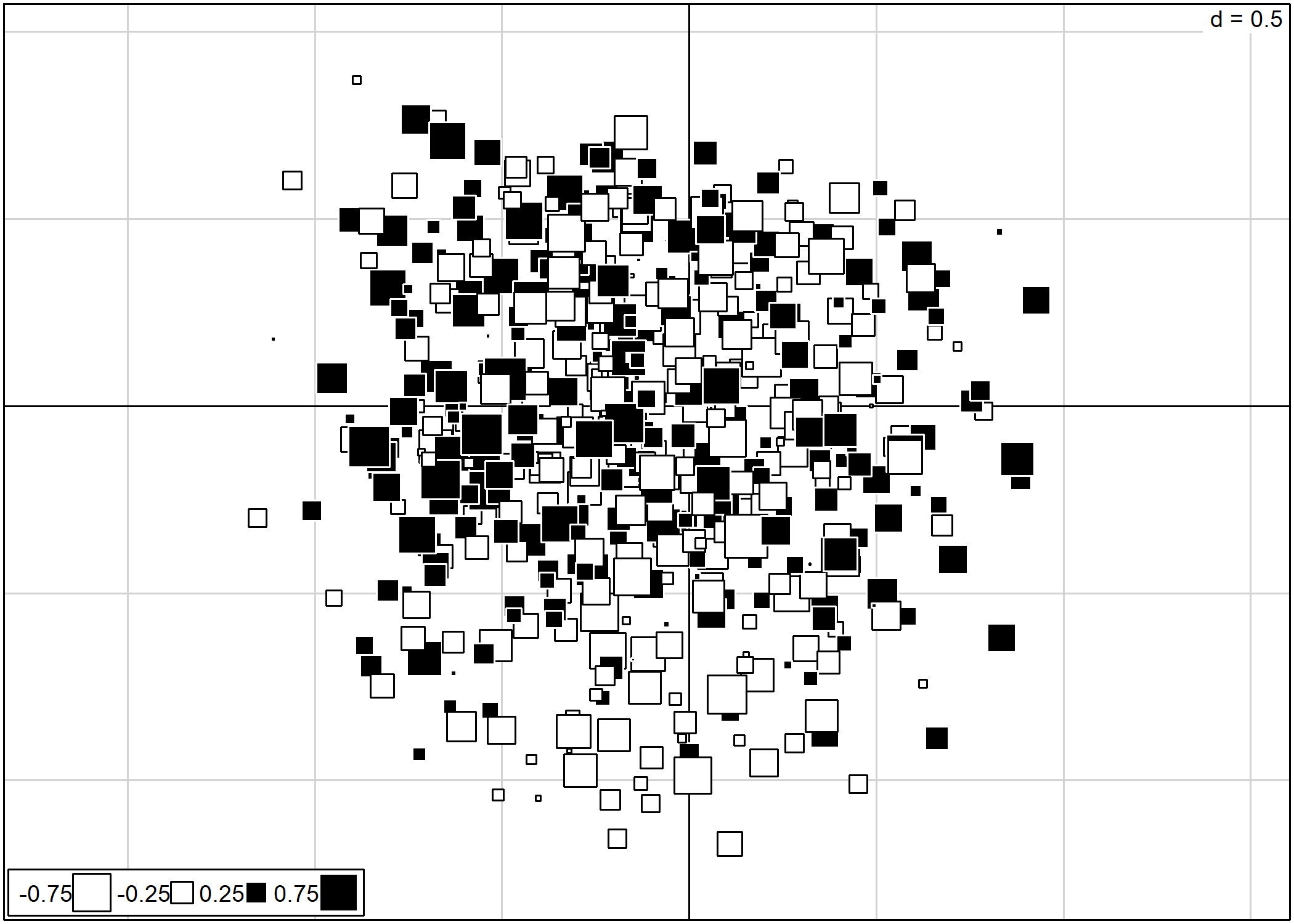
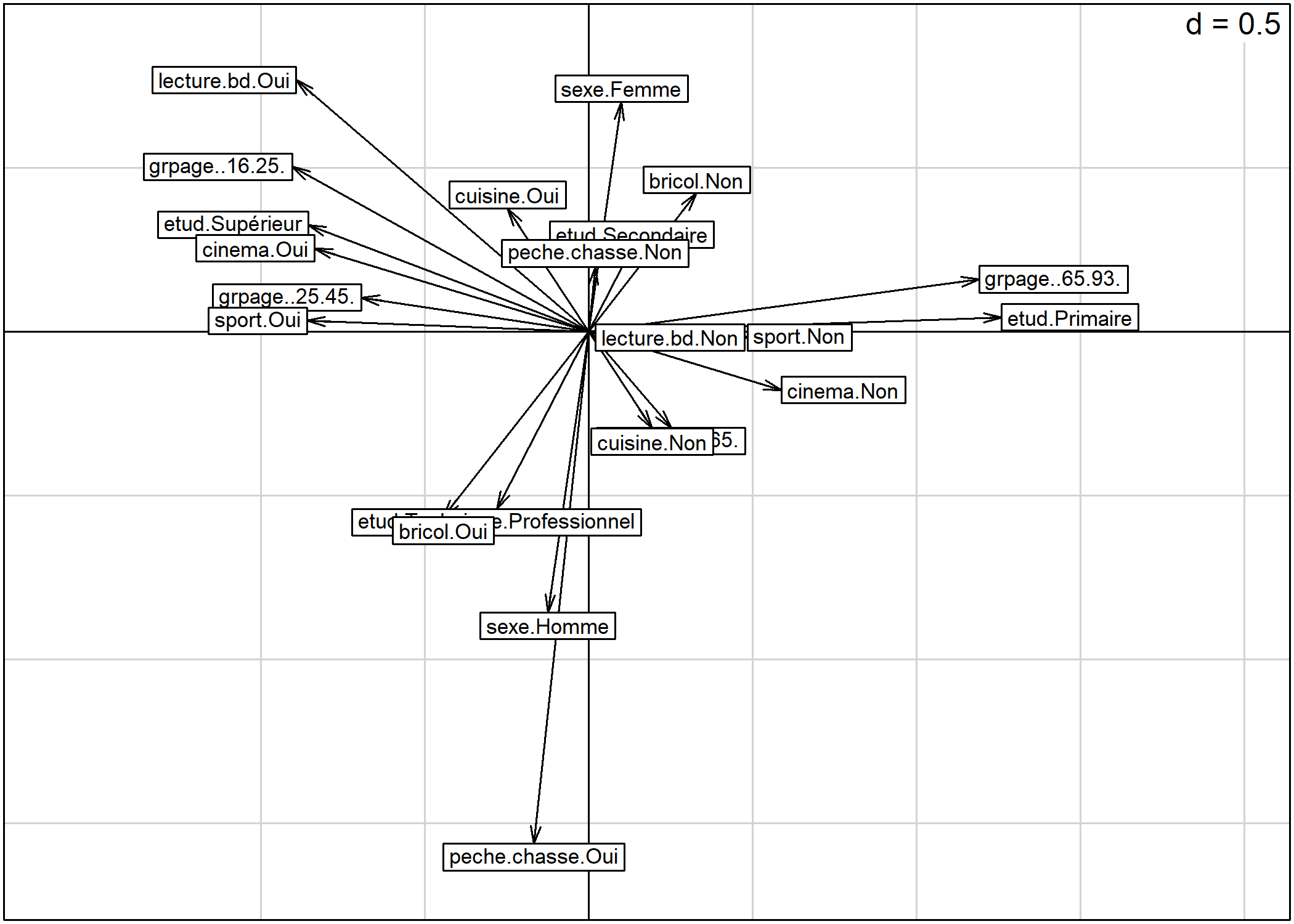
s.arrow permet de représenter les vecteurs variables ou les vecteurs individus sous la forme d’une flèche allant de l’origine du plan factoriel aux coordonnées des variables/individus :
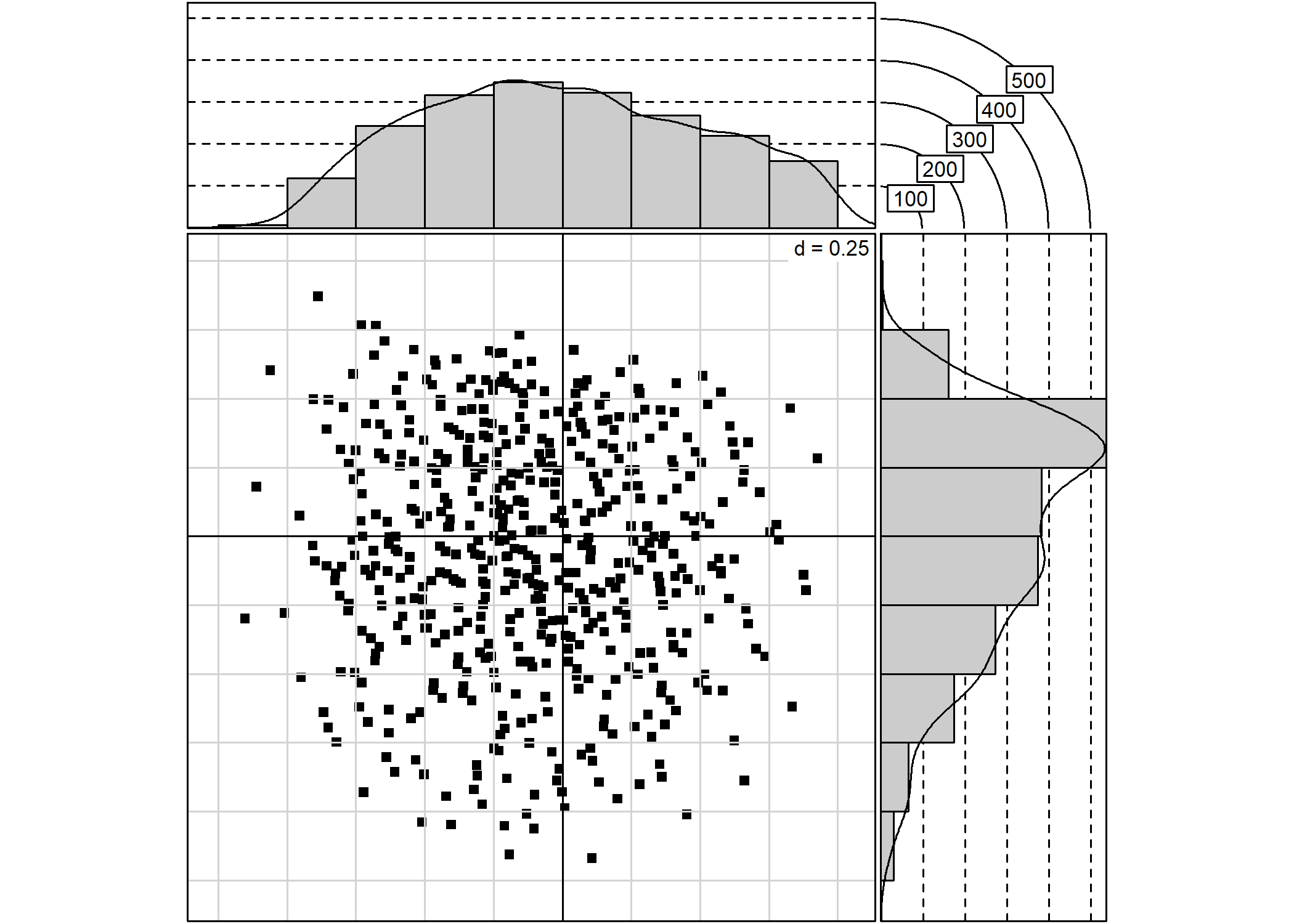
s.hist permet de représenter des individus (ou des modalités) sur le plan factoriel et d’afficher leur distribution sur chaque axe :
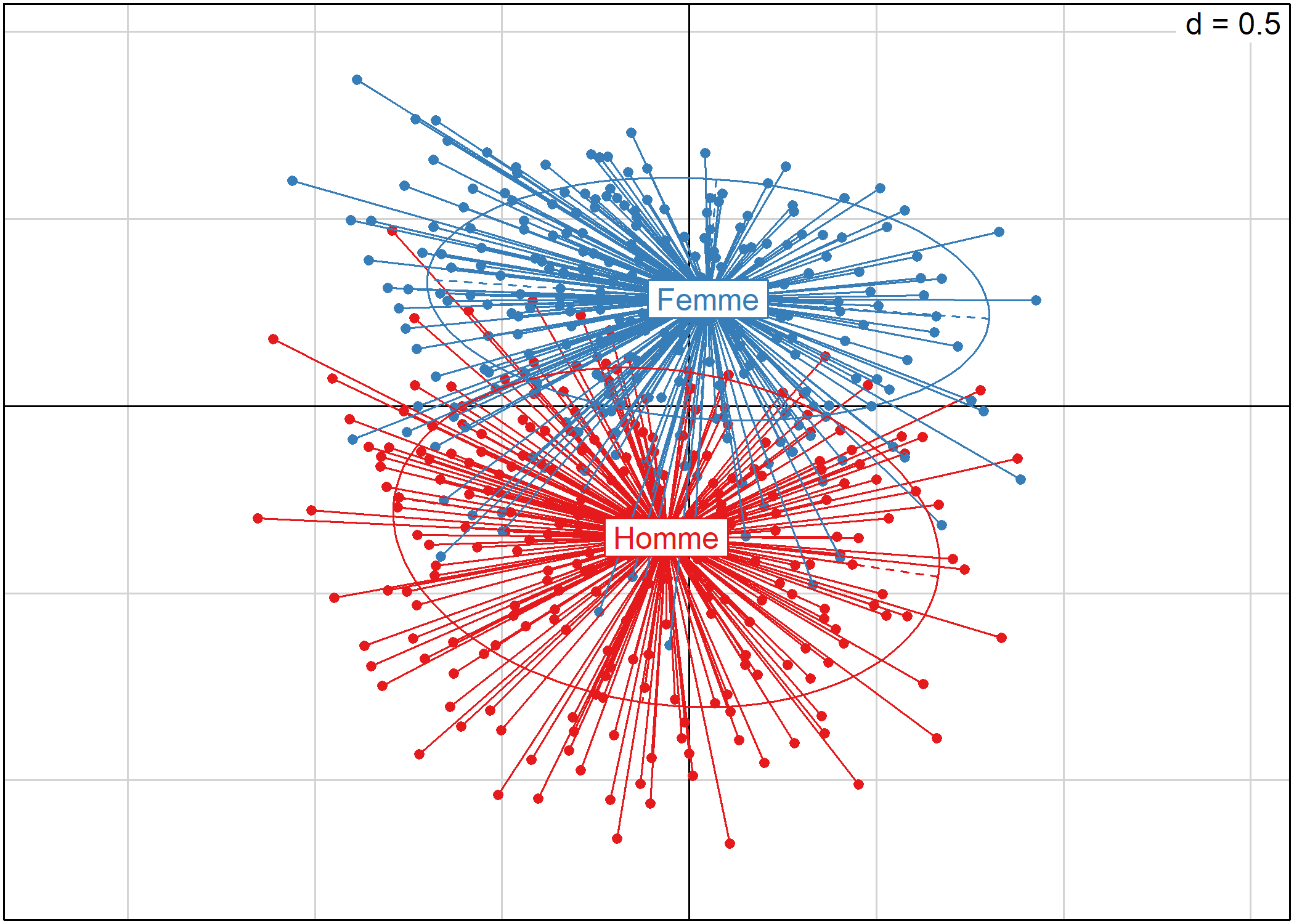
s.class et s.chull permettent de représenter les différentes observations classées en plusieurs catégories. Cela permet notamment de projeter certaines variables.
s.class représente les observations par des points, lie chaque observation au barycentre de la modalité à laquelle elle appartient et dessine une ellipse représentant la forme générale du nuage de points :
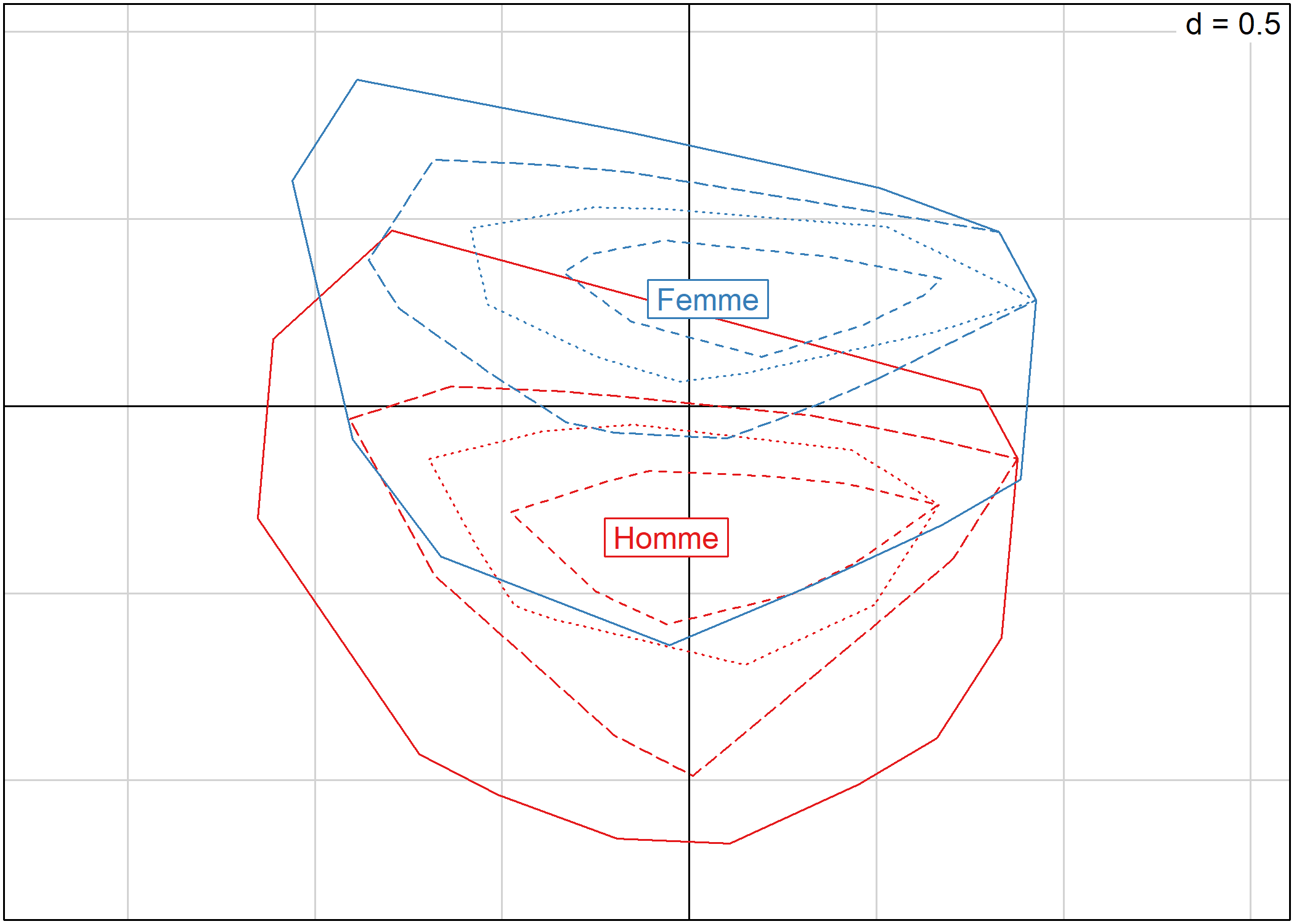
s.chull représente les barycentres de chaque catégorie et dessine des lignes de niveaux représentant la distribution des individus de cette catégorie. Les individus ne sont pas directement représentés :
Il est préférable de fournir une liste de couleurs (via le paramètre col) pour rendre le graphique plus lisible. Si vous avez installé l’extension RColorBrewer, vous pouvez utiliser les différentes palettes de couleurs proposées. Pour afficher les palettes disponibles, utilisez display.brewer.all.
Pour obtenir une palette de couleurs, utilisez la fonction brewer.pal avec les arguments n (nombre de couleurs demandées) et pal(nom de la palette de couleurs désirée).
Pour plus d’informations sur les palettes de couleurs de R, voir le chapitre dédié.
Il est aussi possible de passer à fviz_mca_ind une variable de regroupement via le paramètre habillage.
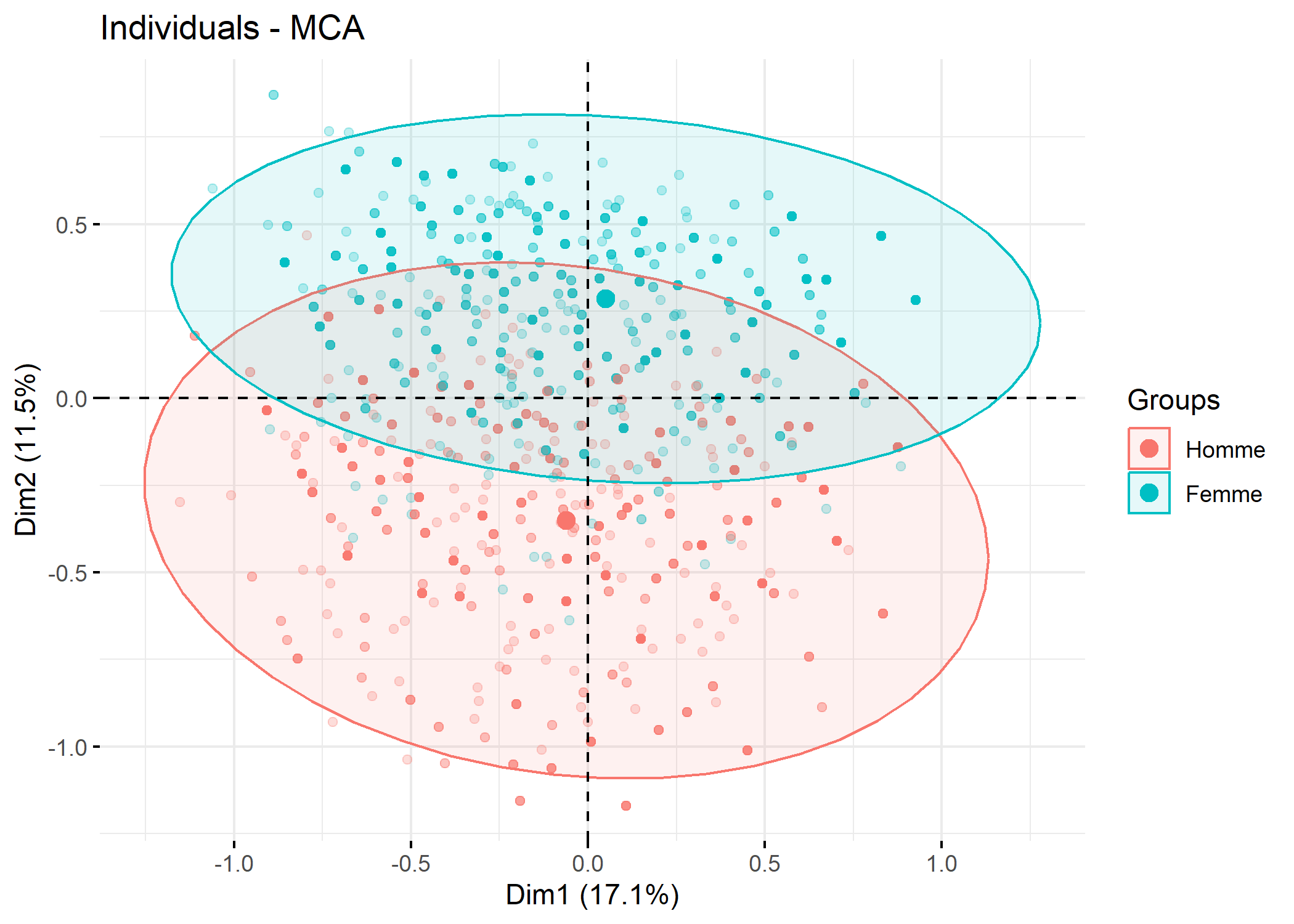
La variable catégorielle transmise à s.class ou s.chull n’est pas obligatoirement une des variables retenues pour l’ACM. Il est tout à fait possible d’utiliser une autre variable. Par exemple :
Les fonctions scatter et biplot sont équivalentes : elles appliquent s.class à chaque variable utilisée pour l’ACM.
ACM avec FactoMineR
Comme avec ade4, il est nécessaire de préparer les données au préalable (voir section précédente).
L’ACM se calcule avec la fonction MCA, l’argument ncp permettant de choisir le nombre d’axes à retenir :
**Results of the Multiple Correspondence Analysis (MCA)**
The analysis was performed on 2000 individuals, described by 9 variables
*The results are available in the following objects:
name description
1 "$eig" "eigenvalues"
2 "$var" "results for the variables"
3 "$var$coord" "coord. of the categories"
4 "$var$cos2" "cos2 for the categories"
5 "$var$contrib" "contributions of the categories"
6 "$var$v.test" "v-test for the categories"
7 "$ind" "results for the individuals"
8 "$ind$coord" "coord. for the individuals"
9 "$ind$cos2" "cos2 for the individuals"
10 "$ind$contrib" "contributions of the individuals"
11 "$call" "intermediate results"
12 "$call$marge.col" "weights of columns"
13 "$call$marge.li" "weights of rows" eigenvalue percentage of variance
dim 1 0.25757489 15.454493
dim 2 0.18363502 11.018101
dim 3 0.16164626 9.698776
dim 4 0.12871623 7.722974
dim 5 0.12135737 7.281442
dim 6 0.11213331 6.727999
dim 7 0.10959377 6.575626
dim 8 0.10340564 6.204338
dim 9 0.09867478 5.920487
dim 10 0.09192693 5.515616
dim 11 0.07501208 4.500725
dim 12 0.06679676 4.007805
dim 13 0.06002063 3.601238
dim 14 0.05832024 3.499215
dim 15 0.03785276 2.271166
cumulative percentage of variance
dim 1 15.45449
dim 2 26.47259
dim 3 36.17137
dim 4 43.89434
dim 5 51.17579
dim 6 57.90378
dim 7 64.47941
dim 8 70.68375
dim 9 76.60424
dim 10 82.11985
dim 11 86.62058
dim 12 90.62838
dim 13 94.22962
dim 14 97.72883
dim 15 100.00000[1] 1.666667En premier lieu, il apparait que l’inertie totale obtenue avec MCA est différente de celle observée avec dudi.acm. Cela est dû à un traitement différents des valeurs manquantes. Alors que dudi.acm exclu les valeurs manquantes, MCA les considèrent, par défaut, comme une modalité additionnelle. Pour calculer l’ACM uniquement sur les individus n’ayant pas de valeur manquante, on aura recours à complete.cases :
eigenvalue percentage of variance
dim 1 0.24790700 17.162792
dim 2 0.16758465 11.602014
dim 3 0.13042357 9.029324
dim 4 0.12595105 8.719688
dim 5 0.11338629 7.849820
dim 6 0.10976674 7.599236
dim 7 0.10060204 6.964757
dim 8 0.09802387 6.786268
dim 9 0.09283131 6.426783
dim 10 0.07673502 5.312425
dim 11 0.06609694 4.575942
dim 12 0.05950655 4.119684
dim 13 0.05562942 3.851267
cumulative percentage of variance
dim 1 17.16279
dim 2 28.76481
dim 3 37.79413
dim 4 46.51382
dim 5 54.36364
dim 6 61.96287
dim 7 68.92763
dim 8 75.71390
dim 9 82.14068
dim 10 87.45311
dim 11 92.02905
dim 12 96.14873
dim 13 100.00000[1] 1.444444Les possibilités graphiques de FactoMineR sont différentes de celles de ade4. Un recours à la fonction plot affichera par défaut les individus, les modalités et les variables. La commande ?plot.MCA permet d’accéder au fichier d’aide de cette fonction (i.e. de la méthode générique plot appliquée aux objets de type MCA) et de voir toutes les options graphiques. L’argument choix permet de spécifier ce que l’on souhaite afficher (« ind » pour les individus et les catégories, « var » pour les variables). L’argument invisible quant à lui permet de spécifier ce que l’on souhaite masquer. Les axes à afficher se précisent avec axes. Voir les exemples ci-dessous.
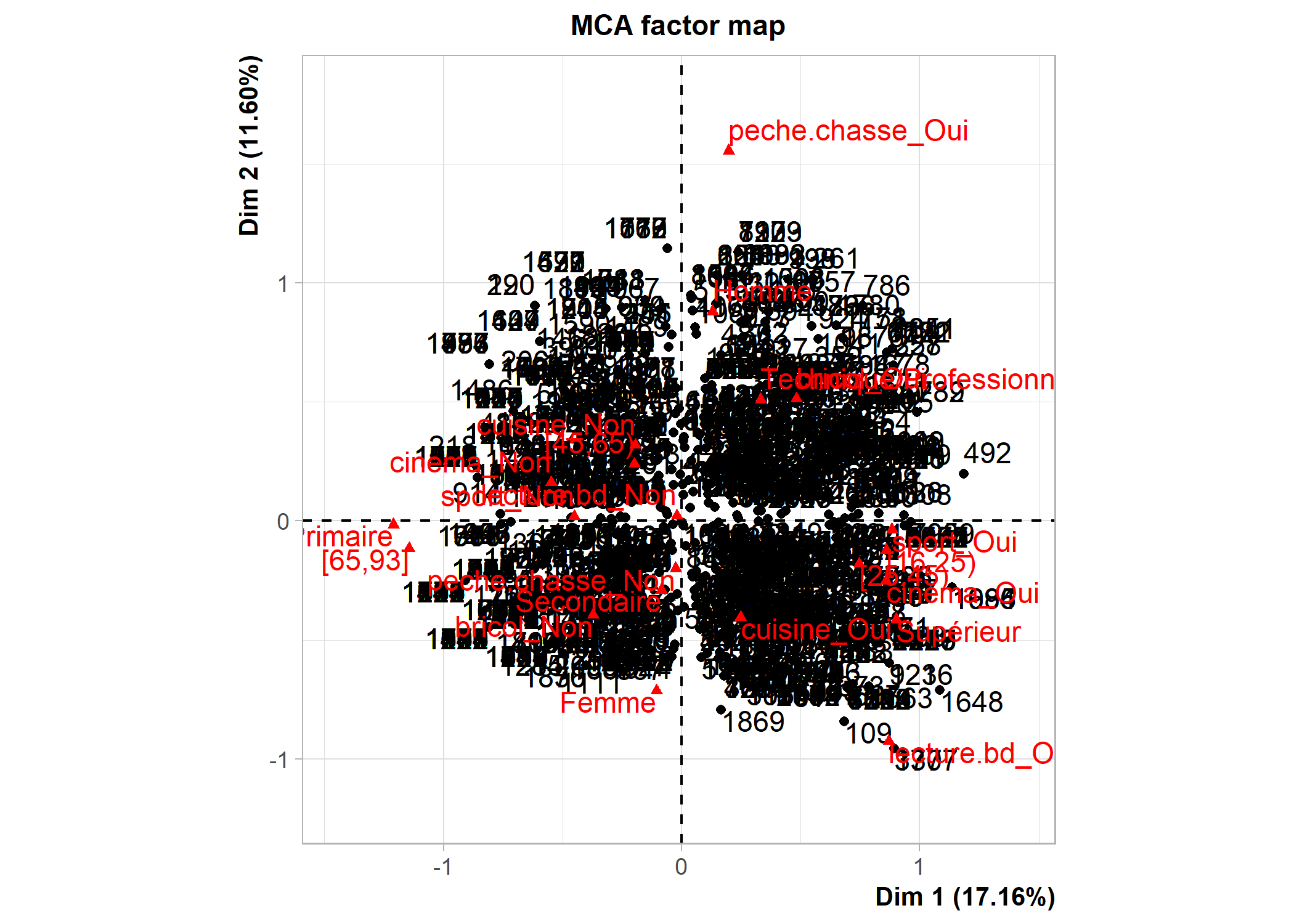
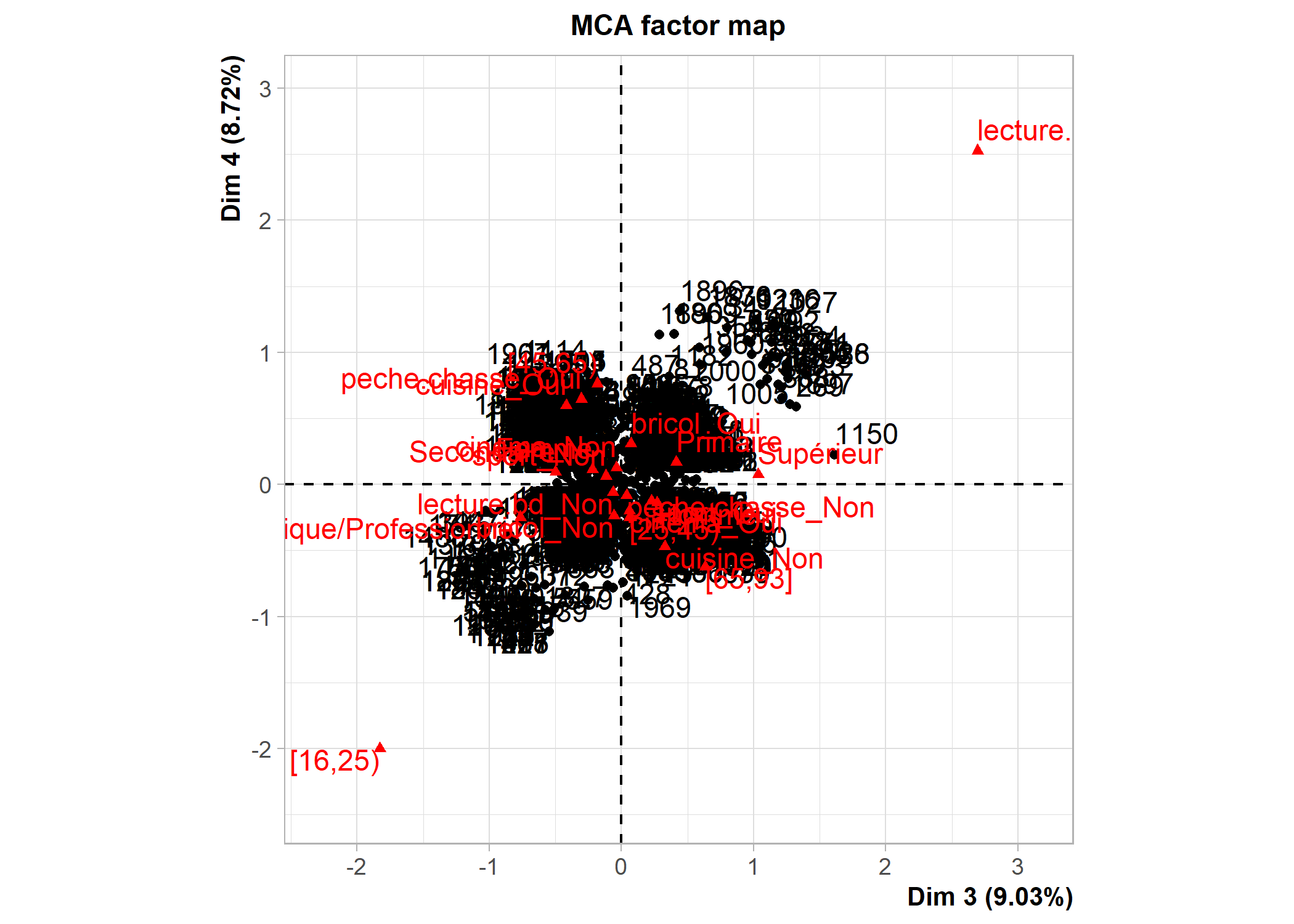
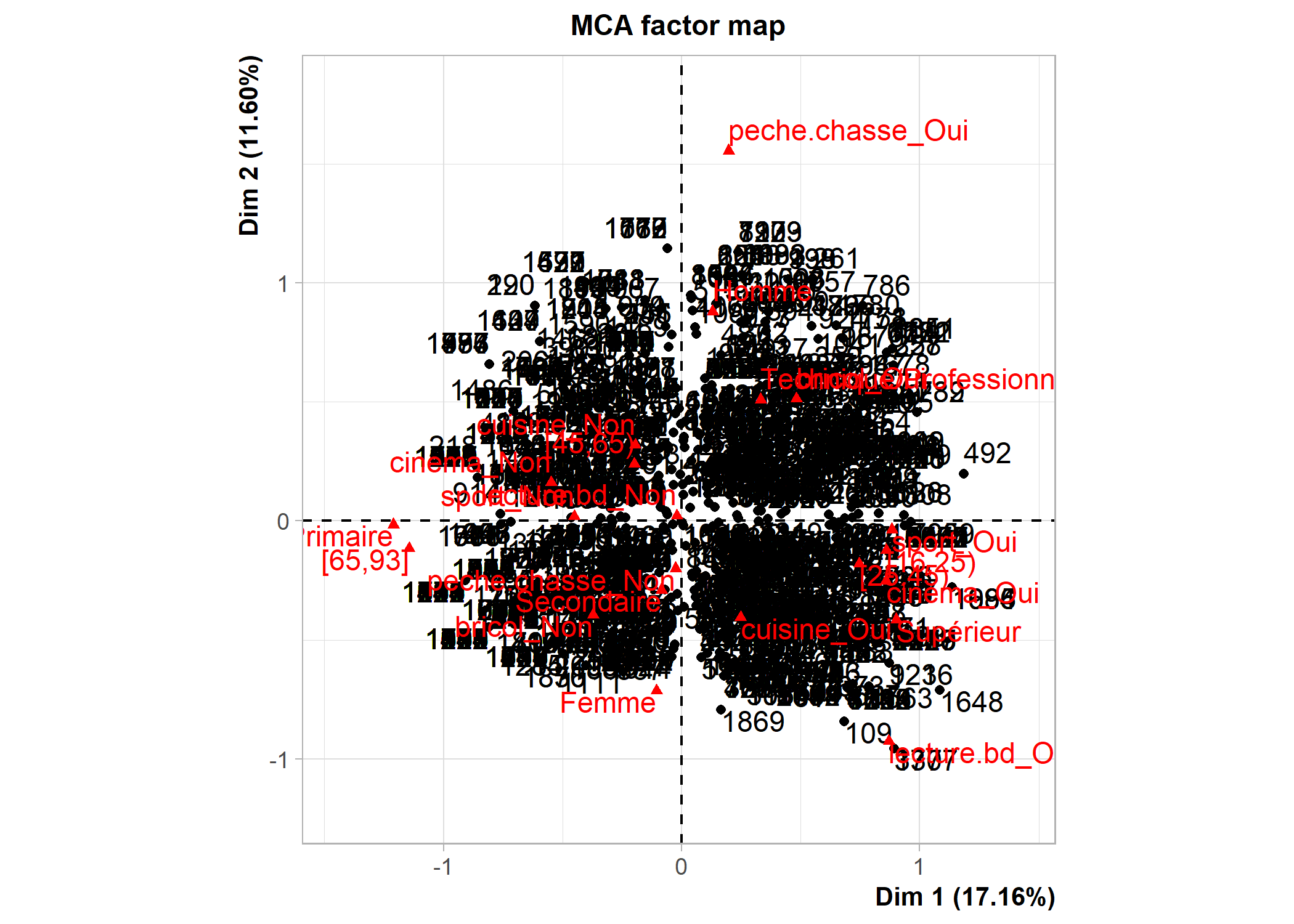
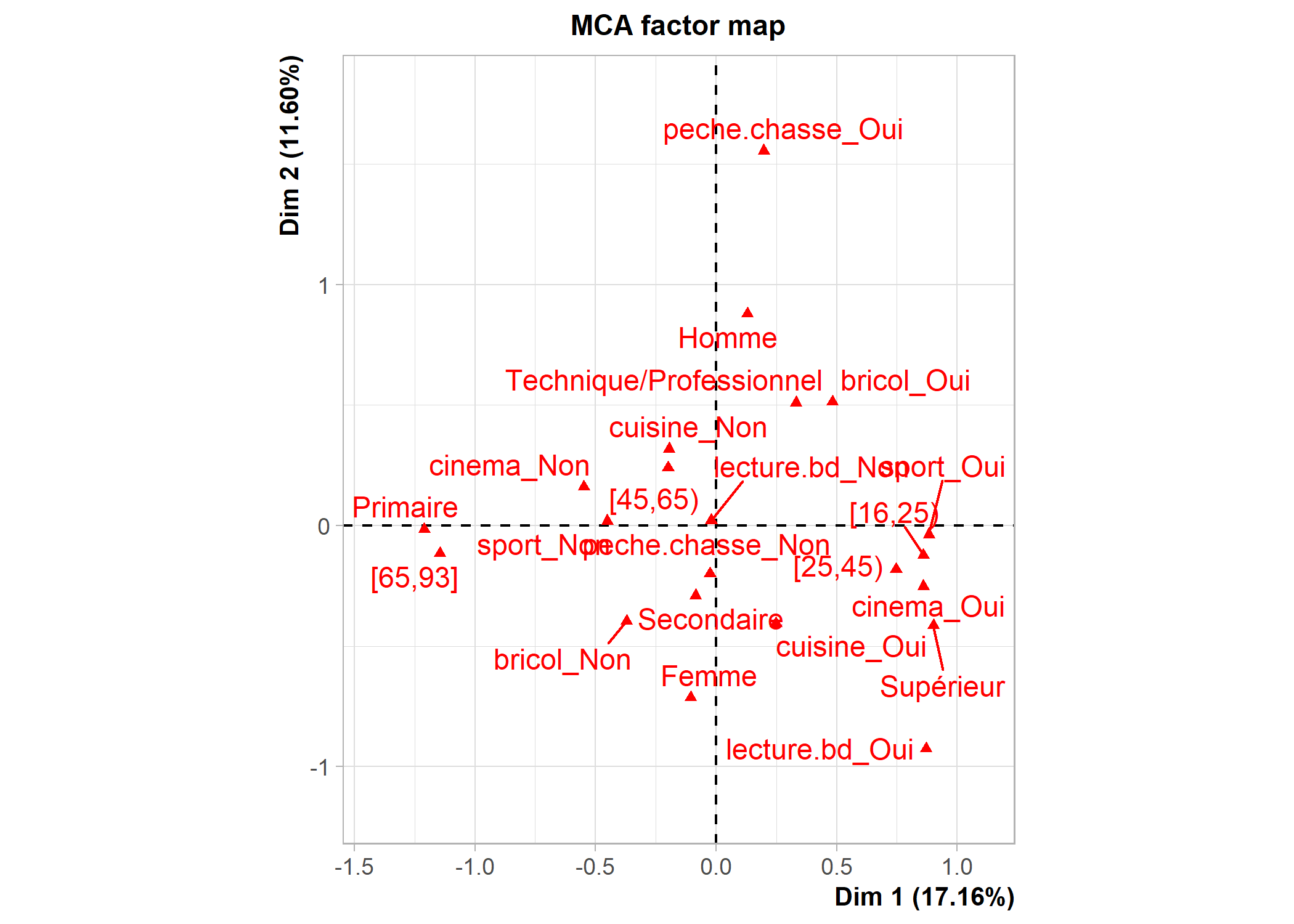
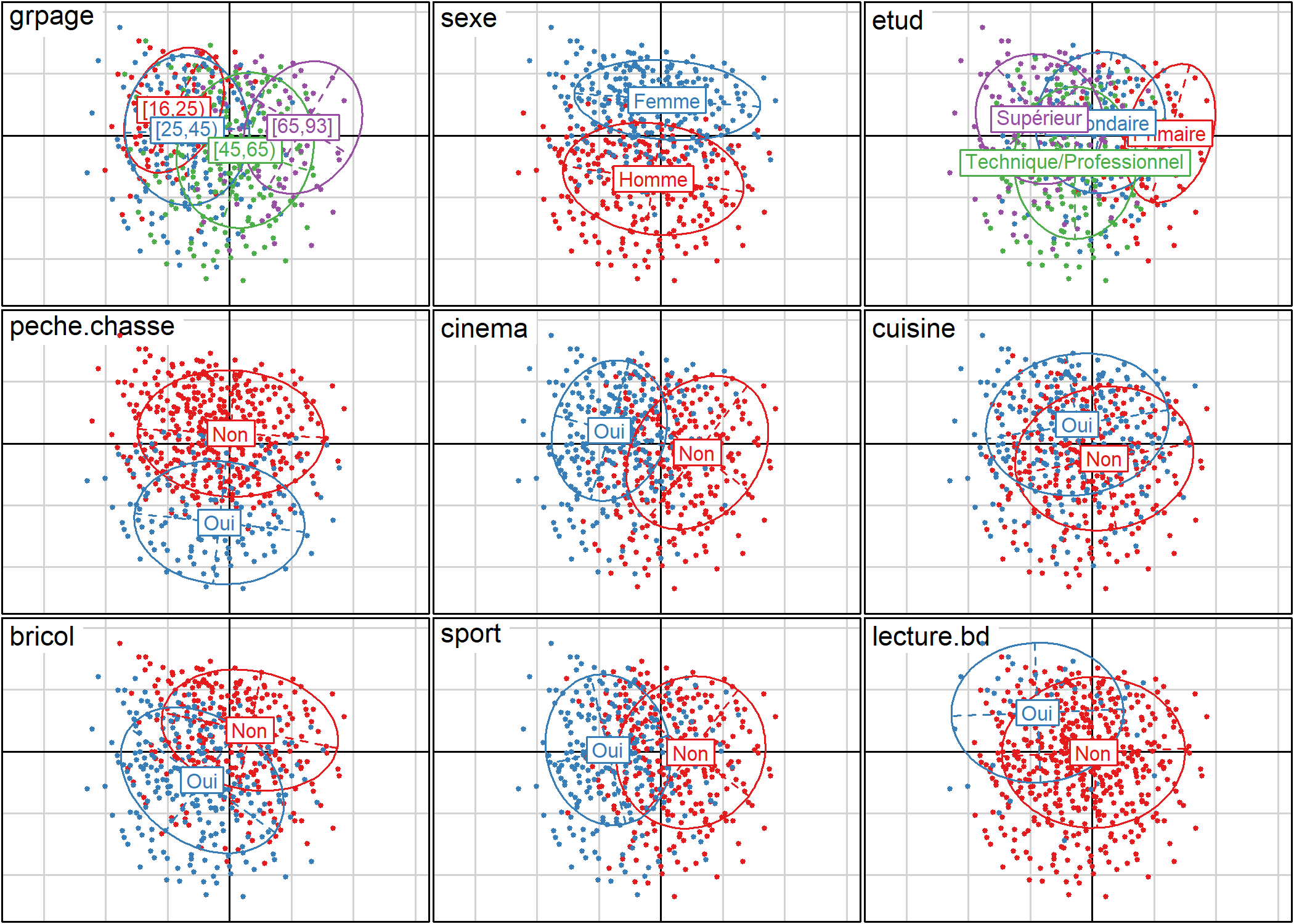
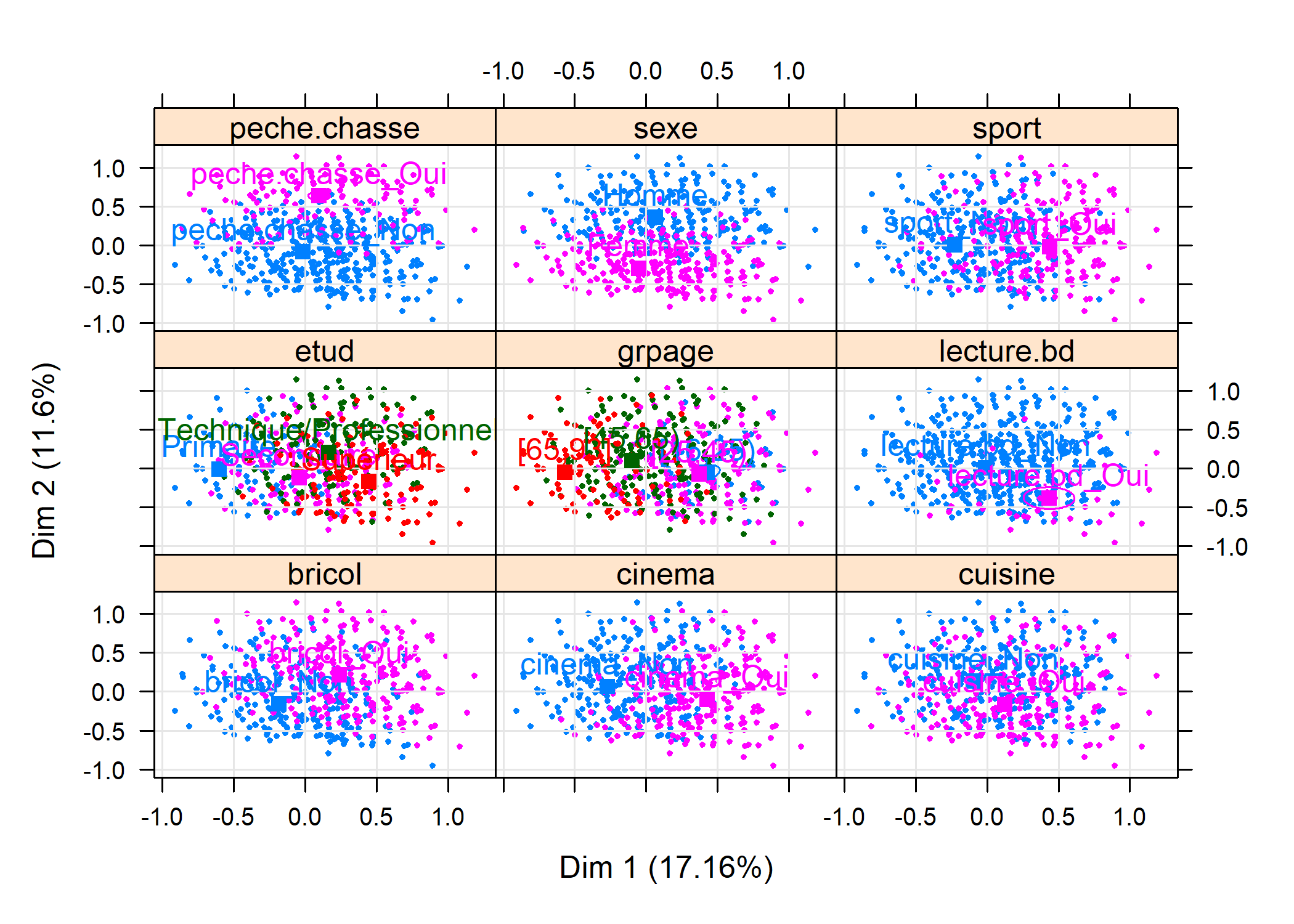
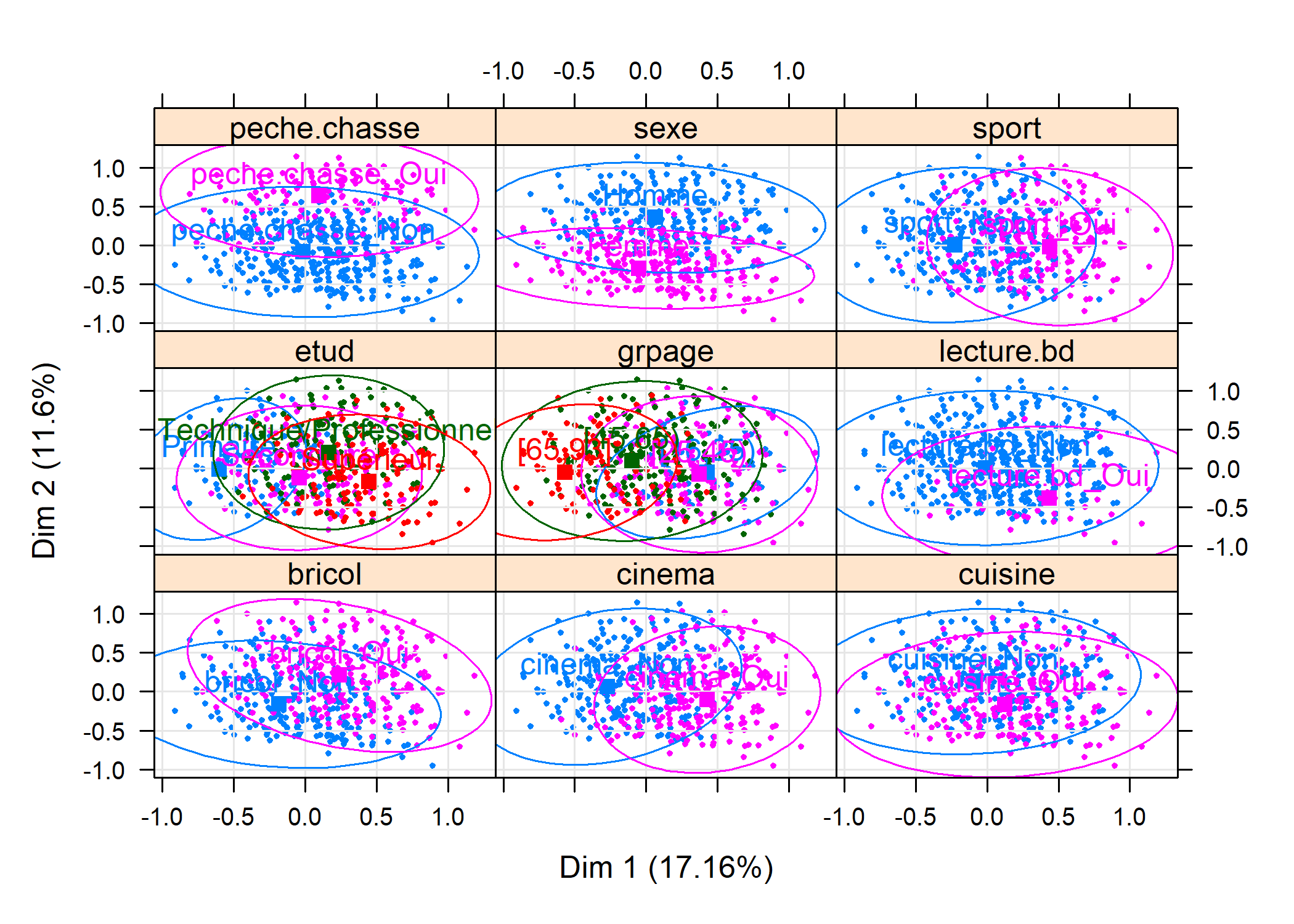
La fonction plotellipses trace des ellipses de confiance atour des modalités de variables qualitatives. L’objectif est de voir si les modalités d’une variable qualitative sont significativement différentes les unes des autres.
Par défaut (means=TRUE), les ellipses de confiance sont calculées pour les coordonnées moyennes de chaque catégorie.
L’option means=FALSE calculera les ellipses de confiance pour l’ensemble des coordonnées des observations relevant de chaque catégorie.
La fonction dimdesc aide à décrire et interpréter les dimensions de l’ACM. Cette fonction est très utile quand le nombre de variables est élevé. Elle permet de voir à quelles variables les axes sont le plus liés : quelles variables et quelles modalités décrivent le mieux chaque axe ?
Pour les variables qualitatives, un modèle d’analyse de variance à un facteur est réalisé pour chaque dimension ; les variables à expliquer sont les coordonnées des individus et la variable explicative est une des variables qualitatives. Un test F permet de voir si la variable a un effet significatif sur la dimension et des tests T sont réalisés modalité par modalité (avec le contraste somme des alpha_i=0). Cela montre si les coordonnées des individus de la sous-population définie par une modalité sont significativement différentes de celles de l’ensemble de la population (i.e. différentes de 0). Les variables et modalités sont triées par probabilité critique et seules celles qui sont significatives sont gardées dans le résultat.
Extensions complémentaires
factoextra
L’extension factoextra fournit des fonctions graphiques ggplot2 pour visualiser les résultats d’une analyse factorielle, réalisée avec ade4 ou FactoMineR.
Plus d’informations sur https://rpkgs.datanovia.com/factoextra/.
explor
L’extension explor fournit une interface graphique pour explorer les résultats d’une analyse factorielle, réalisée avec ade4 ou FactoMineR.
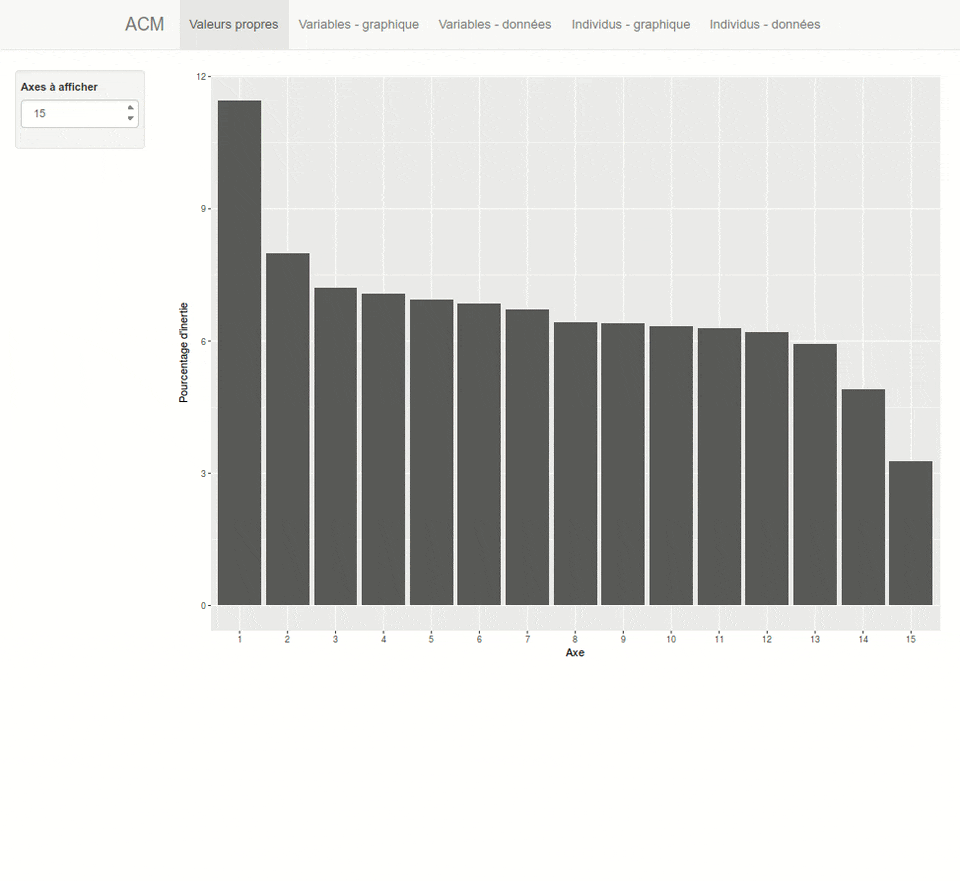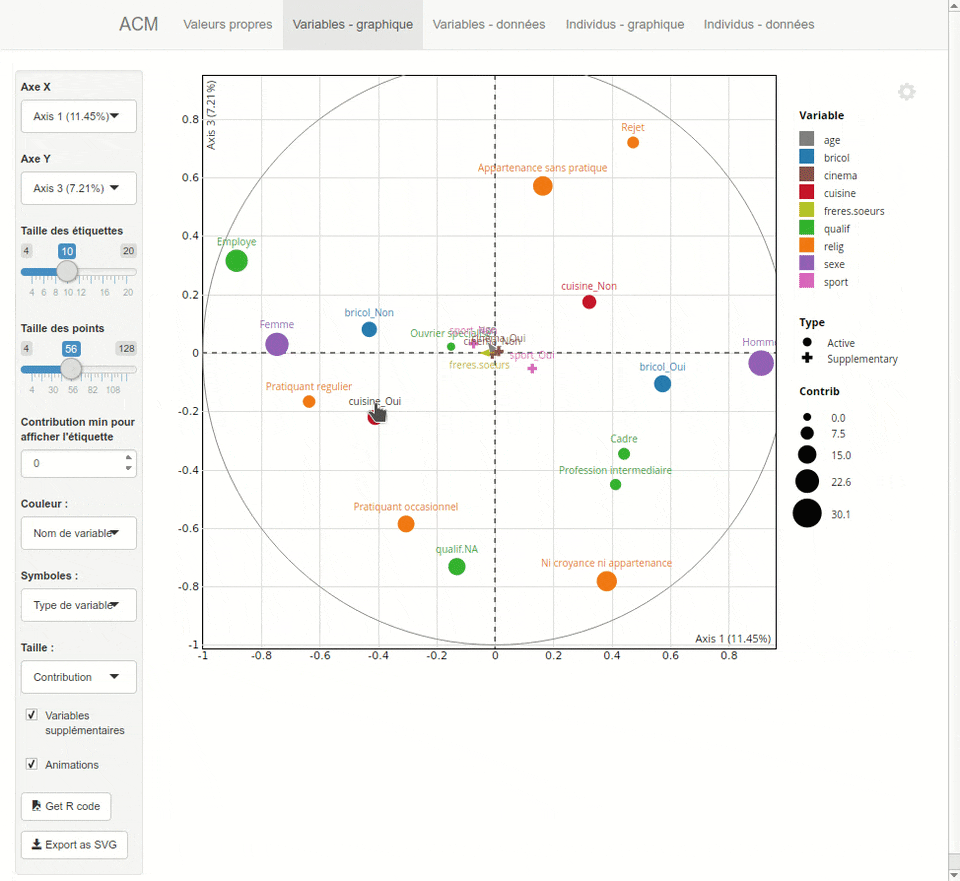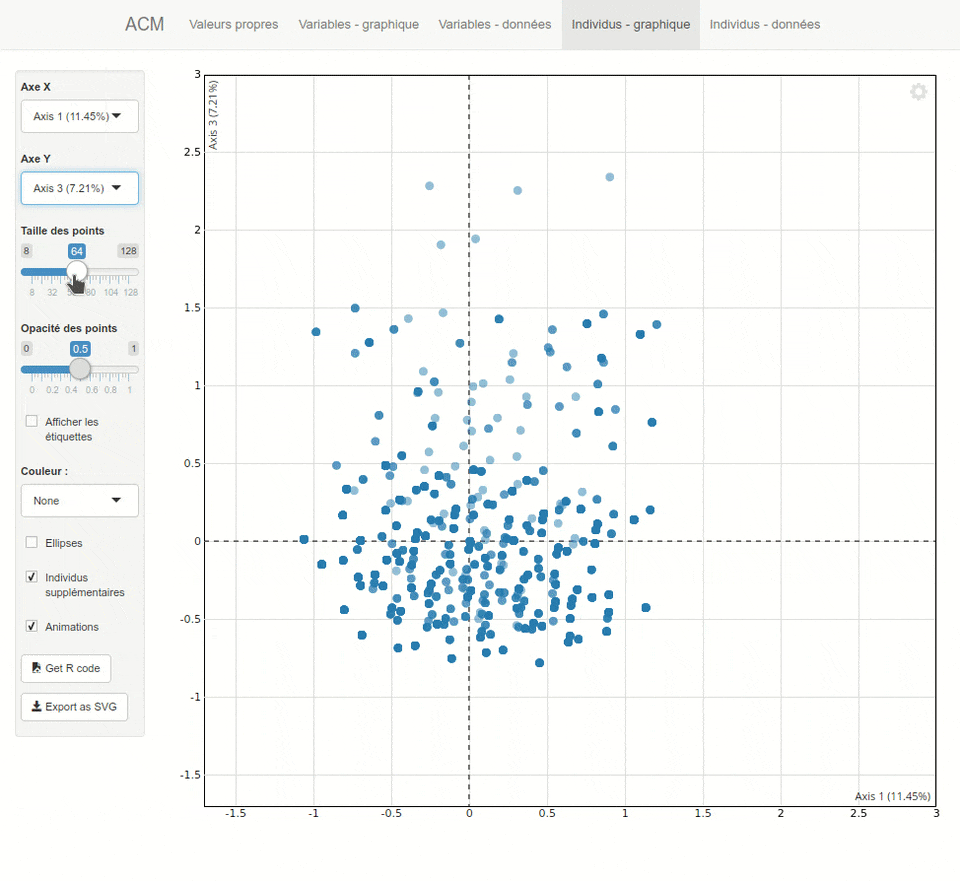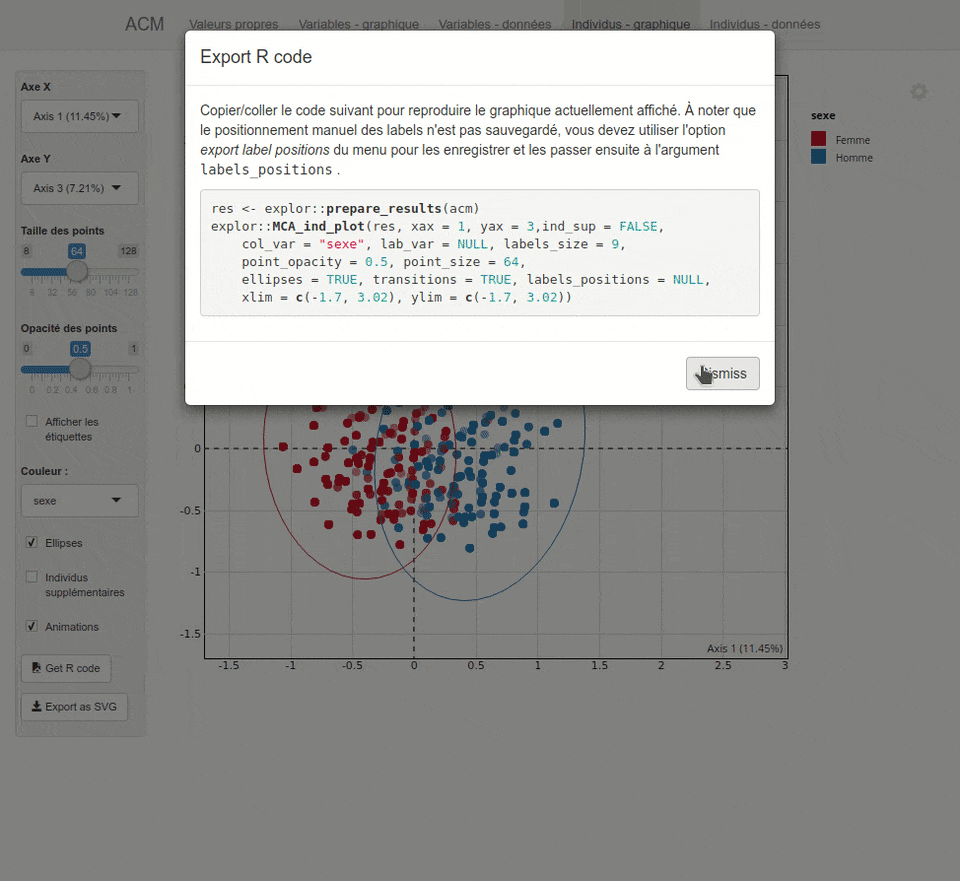
Plus d’informations sur https://github.com/juba/explor/.
GDAtools
L’extension GDAtools développé par Nicolas Robette propose plusieurs outils pour l’interprétation et la visualisation des analyses factorielles ainsi que différentes variables d’ACM, pour la prise en compte par exemple des valeurs manquantes.
On pourra se référer au tutoriel dédié disponible en français sur https://nicolas-robette.github.io/GDAtools/articles/french/Tutoriel_AGD.html.
Factoshiny
L’extension Factoshiny permet d’améliorer facilement et de façon interactive les graphiques produits par FactoMineR pour les rendre beaucoup plus lisibles.
Plus d’informations sur http://factominer.free.fr/graphs/factoshiny-fr.html.
FactoInvestigate
L’extension FactoInvestigate décrit et interprète automatiquement les résultats de votre analyse factorielle (ACP, AFC ou ACM) en choisissant les graphes les plus appropriés pour un rapport.
Vous avez juste à faire l’analyse comme habituellement avec FactoMineR ou Factoshiny, et ensuite utiliser FactoInvestigate pour obtenir un rapport automatisé.
Plus d’informations sur http://factominer.free.fr/reporting/index_fr.html.
Voir aussi
Un tutoriel détaillé en français, Visualiser une analyse géométrique des données avec ggplot2 (R/RStudio)
, est disponible sur le blog Quanti : https://quanti.hypotheses.org/1871.
Pour une présentation plus détaillée, voir
http://www.math.univ-toulouse.fr/~baccini/zpedago/asdm.pdf.↩︎La fonction
scoreconstituera également une aide à l’interprétation des axes.↩︎