

Premier travail avec des données
Ce chapitre est inspiré de la section Premier travail avec les données du support de cours Introduction à R réalisé par Julien Barnier.
Ce chapitre est évoqué dans le webin-R #01 (premier contact avec R & RStudio) sur YouTube.
Regrouper les commandes dans des scripts
Jusqu’à maintenant nous avons utilisé uniquement la console pour communiquer avec R via l’invite de commandes. Le principal problème de ce mode d’interaction est qu’une fois qu’une commande est tapée, elle est pour ainsi dire « perdue », c’est-à-dire qu’on doit la saisir à nouveau si on veut l’exécuter une seconde fois. L’utilisation de la console est donc restreinte aux petites commandes « jetables », le plus souvent utilisées comme test.
La plupart du temps, les commandes seront stockées dans un fichier à part, que l’on pourra facilement ouvrir, éditer et exécuter en tout ou partie si besoin. On appelle en général ce type de fichier un script.
Pour comprendre comment cela fonctionne, dans RStudio cliquez sur l’icône en haut à gauche représentant un fichier avec un signe plus vert, puis choisissez R script.
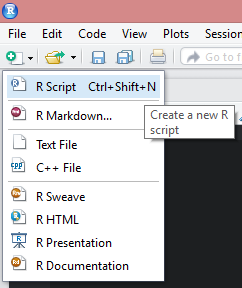
Un nouvel onglet apparaît dans le quadrant supérieur gauche.
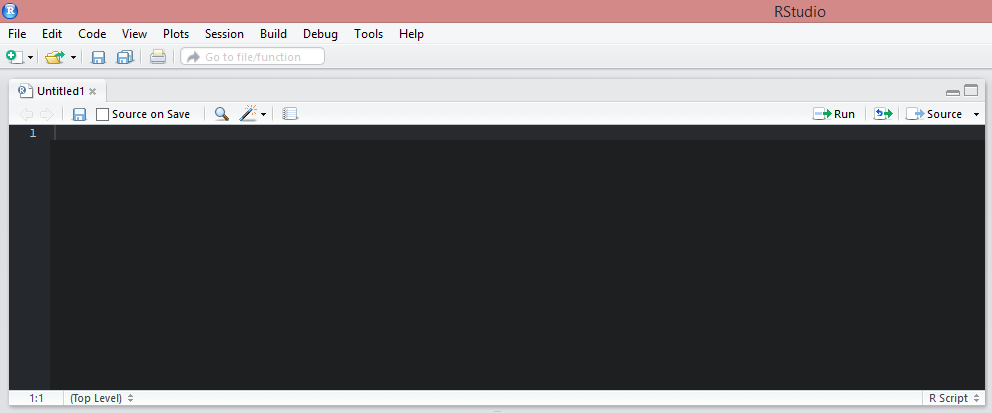
Nous pouvons désormais y saisir des commandes. Par exemple, tapez sur la première ligne la commande suivante : 2 + 2. Ensuite, cliquez sur l’icône Run (en haut à droite de l’onglet du script) ou bien pressez simulatément les touches CTRL et Entrée1.
Les lignes suivantes ont dû faire leur apparition dans la console :
[1] 4Voici donc comment soumettre rapidement à R les commandes saisies dans votre fichier. Vous pouvez désormais l’enregistrer, l’ouvrir plus tard, et en exécuter tout ou partie. À noter que vous avez plusieurs possibilités pour soumettre des commandes à R :
- vous pouvez exécuter la ligne sur laquelle se trouve votre curseur en cliquant sur Run ou en pressant simulatément les touches CTRL et Entrée ;
- vous pouvez sélectionner plusieurs lignes contenant des commandes et les exécuter toutes en une seule fois exactement de la même manière ;
- vous pouvez exécuter d’un coup l’intégralité de votre fichier en cliquant sur l’icône Source.
La plupart du travail sous R consistera donc à éditer un ou plusieurs fichiers de commandes et à envoyer régulièrement les commandes saisies à R en utilisant les raccourcis clavier ad hoc.
Pour plus d’information sur l’utilisation des scripts R dans RStudio, voir (en anglais) : https://support.rstudio.com/hc/en-us/articles/200484448-Editing-and-Executing-Code.
Quand vous enregistrez un script sous RStudio, il est possible qu’il vous demande de choisir un type d’encodage des caractères (Choose Encoding). Si tel est le cas, utilisez de préférence UTF-8.
Ajouter des commentaires
Un commentaire est une ligne ou une portion de ligne qui sera ignorée par R. Ceci signifie qu’on peut y écrire ce qu’on veut et qu’on va les utiliser pour ajouter tout un tas de commentaires à notre code permettant de décrire les différentes étapes du travail, les choses à se rappeler, les questions en suspens, etc.
Un commentaire sous R commence par un ou plusieurs symboles # (qui s’obtient avec les touches Alt Gr et 3 sur les claviers de type PC). Tout ce qui suit ce symbole jusqu’à la fin de la ligne est considéré comme un commentaire. On peut créer une ligne entière de commentaire en la faisant débuter par ##. Par exemple :
On peut aussi créer des commentaires pour une ligne en cours :
Dans tous les cas, il est très important de documenter ses fichiers R au fur et à mesure, faute de quoi on risque de ne plus y comprendre grand chose si on les reprend ne serait-ce que quelques semaines plus tard.
Avec RStudio, vous pouvez également utiliser les commentaires pour créer des sections au sein de votre script et naviguer plus rapidement. Il suffit de faire suivre une ligne de commentaires d’au moins 4 signes moins (----). Par exemple, si vous saisissez ceci dans votre script :
Vous verrez apparaître en bas à gauche de la fenêtre du script un symbole dièse orange. Si vous cliquez dessus, un menu de navigation s’affichera vous permettant de vous déplacez rapidement au sein de votre script. Pour plus d’information, voir la documentation de RStudio (en anglais) : https://support.rstudio.com/hc/en-us/articles/200484568-Code-Folding-and-Sections.
Les sections peuvent également être facilement créées avec le raccourci clavier CTRL + SHIFT + R.
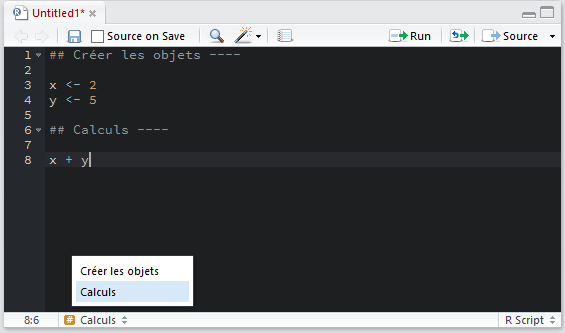
Note : on remarquera au passage que le titre de l’onglet est affiché en rouge et suivi d’une astérisque (*), nous indiquant ainsi qu’il y a des modifications non enregistrées dans notre fichier.
Tableaux de données
Dans cette partie nous allons utiliser un jeu de données inclus dans l’extension questionr. L’installation d’extension est décrite dans le chapitre Extensions.
Le jeu de données en question est un extrait de l’enquête Histoire de vie réalisée par l’INSEE en 2003. Il contient 2000 individus et 20 variables. Pour pouvoir utiliser ces données, il faut d’abord charger l’extension questionr (après l’avoir installée, bien entendu). Le chargement d’une extension en mémoire se fait à l’aide de la fonction library. Sous RStudio, vous pouvez également charger une extension en allant dans l’onglet Packages du quadrant inférieur droit qui liste l’ensemble des packages disponibles et en cliquant la case à cocher située à gauche du nom du package désiré.
Puis nous allons indiquer à R que nous souhaitons accéder au jeu de données hdv2003 à l’aide de la fonction data :
Bien. Et maintenant, elles sont où mes données ? Et bien elles se trouvent dans un objet nommé hdv2003 désormais chargé en mémoire et accessible directement. D’ailleurs, cet objet est maintenant visible dans l’onglet Environment du quadrant supérieur droit.
Essayons de taper son nom à l’invite de commande :
Le résultat (non reproduit ici) ne ressemble pas forcément à grand-chose… Il faut se rappeler que par défaut, lorsqu’on lui fournit seulement un nom d’objet, R essaye de l’afficher de la manière la meilleure (ou la moins pire) possible. La réponse à la commande hdv2003 n’est donc rien moins que l’affichage des données brutes contenues dans cet objet.
Ce qui signifie donc que l’intégralité de notre jeu de données est inclus dans l’objet nommé hdv2003 ! En effet, dans R, un objet peut très bien contenir un simple nombre, un vecteur ou bien le résultat d’une enquête tout entier. Dans ce cas, les objets sont appelés des data frames, ou tableaux de données. Ils peuvent être manipulés comme tout autre objet. Par exemple :
va entraîner la copie de l’ensemble de nos données dans un nouvel objet nommé d, ce qui peut paraître parfaitement inutile mais a en fait l’avantage de fournir un objet avec un nom beaucoup plus court, ce qui diminuera la quantité de texte à saisir par la suite.
Résumons
Comme nous avons désormais décidé de saisir nos commandes dans un script et non plus directement dans la console, les premières lignes de notre fichier de travail sur les données de l’enquête Histoire de vie pourraient donc ressembler à ceci :
Inspection visuelle des données
La particularité de R par rapport à d’autres logiciels comme Modalisa ou SPSS est de ne pas proposer, par défaut, de vue des données sous forme de tableau. Ceci peut parfois être un peu déstabilisant dans les premiers temps d’utilisation, même si l’on perd vite l’habitude et qu’on finit par se rendre compte que « voir » les données n’est pas forcément un gage de productivité ou de rigueur dans le traitement.
Néanmoins, R propose une interface permettant de visualiser le contenu d’un tableau de données à l’aide de la fonction View :
Sous RStudio, on peut aussi afficher la visionneusee (viewer) en cliquant sur la petite icône en forme de tableau située à droite de la ligne d’un tableau de données dans l’onglet Environment du quadrant supérieur droit (cf. figure ci-après).
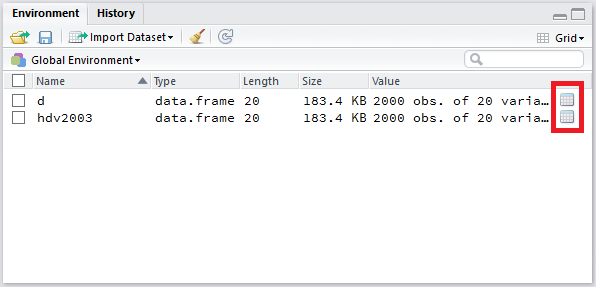
Dans tous les cas, RStudio lancera le viewer dans un onglet dédié dans le quadrant supérieur gauche. Le visualiseur de RStudio est plus avancé que celui-de base fournit par R. Il est possible de trier les données selon une variable en cliquant sur le nom de cette dernière. Il y a également un champs de recherche et un bouton Filter donnant accès à des options de filtrage avancées.
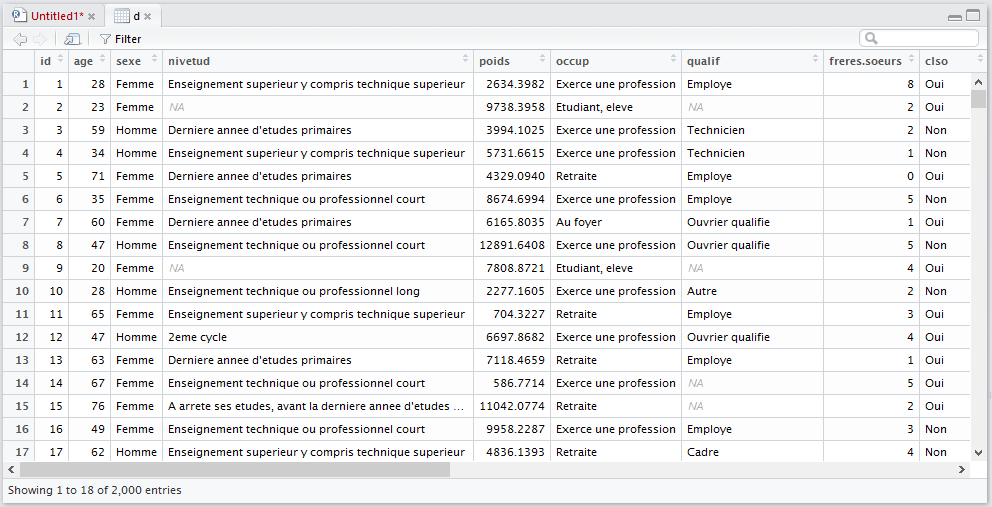
Structure du tableau
Avant de travailler sur les données, nous allons essayer de comprendre comment elles sont structurées. Lors de l’import de données depuis un autre logiciel (que nous aborderons dans un autre chapitre), il s’agira souvent de vérifier que l’importation s’est bien déroulée.
Nous avons déjà vu qu’un tableau de données est organisé en lignes et en colonnes, les lignes correspondant aux observations et les colonnes aux variables. Les fonctions nrow, ncol et dim donnent respectivement le nombre de lignes, le nombre de colonnes et les dimensions de notre tableau. Nous pouvons donc d’ores et déjà vérifier que nous avons bien 2000 lignes et 20 colonnes :
[1] 2000[1] 20[1] 2000 20La fonction names donne les noms des colonnes de notre tableau, c’est-à-dire les noms des variables :
[1] "id" "age" "sexe"
[4] "nivetud" "poids" "occup"
[7] "qualif" "freres.soeurs" "clso"
[10] "relig" "trav.imp" "trav.satisf"
[13] "hard.rock" "lecture.bd" "peche.chasse"
[16] "cuisine" "bricol" "cinema"
[19] "sport" "heures.tv" Accéder aux variables
d représente donc l’ensemble de notre tableau de données. Nous avons vu que si l’on saisit simplement d à l’invite de commandes, on obtient un affichage du tableau en question. Mais comment accéder aux variables, c’est à dire aux colonnes de notre tableau ?
La réponse est simple : on utilise le nom de l’objet, suivi de l’opérateur $, suivi du nom de la variable, comme ceci :
Au regard du résultat (non reproduit ici), on constate alors que R a bien accédé au contenu de notre variable sexe du tableau d et a affiché son contenu, c’est-à-dire l’ensemble des valeurs prises par la variable.
Les fonctions head et tail permettent d’afficher seulement les premières (respectivement les dernières) valeurs prises par la variable. On peut leur passer en argument le nombre d’éléments à afficher :
[1] Enseignement superieur y compris technique superieur
[2] <NA>
[3] Derniere annee d'etudes primaires
[4] Enseignement superieur y compris technique superieur
[5] Derniere annee d'etudes primaires
[6] Enseignement technique ou professionnel court
8 Levels: N'a jamais fait d'etudes ... [1] 52 42 50 41 46 45 46 24 24 66À noter que ces fonctions marchent aussi pour afficher les lignes du tableau d :
La fonction str
La fonction str est plus complète que names. Elle liste les différentes variables, indique leur type et donne le cas échéant des informations supplémentaires ainsi qu’un échantillon des premières valeurs prises par cette variable :
'data.frame': 2000 obs. of 20 variables:
$ id : int 1 2 3 4 5 6 7 8 9 10 ...
$ age : int 28 23 59 34 71 35 60 47 20 28 ...
$ sexe : Factor w/ 2 levels "Homme","Femme": 2 2 1 1 2 2 2 1 2 1 ...
$ nivetud : Factor w/ 8 levels "N'a jamais fait d'etudes",..: 8 NA 3 8 3 6 3 6 NA 7 ...
$ poids : num 2634 9738 3994 5732 4329 ...
$ occup : Factor w/ 7 levels "Exerce une profession",..: 1 3 1 1 4 1 6 1 3 1 ...
$ qualif : Factor w/ 7 levels "Ouvrier specialise",..: 6 NA 3 3 6 6 2 2 NA 7 ...
$ freres.soeurs: int 8 2 2 1 0 5 1 5 4 2 ...
$ clso : Factor w/ 3 levels "Oui","Non","Ne sait pas": 1 1 2 2 1 2 1 2 1 2 ...
$ relig : Factor w/ 6 levels "Pratiquant regulier",..: 4 4 4 3 1 4 3 4 3 2 ...
$ trav.imp : Factor w/ 4 levels "Le plus important",..: 4 NA 2 3 NA 1 NA 4 NA 3 ...
$ trav.satisf : Factor w/ 3 levels "Satisfaction",..: 2 NA 3 1 NA 3 NA 2 NA 1 ...
$ hard.rock : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 1 1 1 1 ...
$ lecture.bd : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 1 1 1 1 ...
$ peche.chasse : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 2 2 1 1 ...
$ cuisine : Factor w/ 2 levels "Non","Oui": 2 1 1 2 1 1 2 2 1 1 ...
$ bricol : Factor w/ 2 levels "Non","Oui": 1 1 1 2 1 1 1 2 1 1 ...
$ cinema : Factor w/ 2 levels "Non","Oui": 1 2 1 2 1 2 1 1 2 2 ...
$ sport : Factor w/ 2 levels "Non","Oui": 1 2 2 2 1 2 1 1 1 2 ...
$ heures.tv : num 0 1 0 2 3 2 2.9 1 2 2 ...La première ligne nous informe qu’il s’agit bien d’un tableau de données avec 2000 observations et 20 variables. Vient ensuite la liste des variables. La première se nomme id et est de type entier (int). La seconde se nomme age et est de type numérique. La troisième se nomme sexe, il s’agit d’un facteur (factor).
Un facteur est une variable pouvant prendre un nombre limité de modalités (levels). Ici notre variable a deux modalités possibles : « Homme » et « Femme ». Ce type de variable est décrit plus en détail dans le chapitre sur la manipulation de données.
La fonction str est essentielle à connaître et peut s’appliquer à n’importe quel type d’objet. C’est un excellent moyen de connaître en détail la structure d’un objet. Cependant, les résultats peuvent être parfois trop détaillés et on lui priviligiera dans certains cas la fonction describe que l’on abordera dans les prochains chapitres, cependant moins générique puisque ne s’appliquant qu’à des tableaux de données et à des vecteurs, tandis que str peut s’appliquer à absolument tout objet, y compris des fonctions.
d
20 Variables 2000 Observations
------------------------------------------------------------
id
n missing distinct Info Mean Gmd
2000 0 2000 1 1000 667
.05 .10 .25 .50 .75 .90
101.0 200.9 500.8 1000.5 1500.2 1800.1
.95
1900.0
lowest : 1 2 3 4 5, highest: 1996 1997 1998 1999 2000
------------------------------------------------------------
age
n missing distinct Info Mean Gmd
2000 0 78 1 48.16 19.4
.05 .10 .25 .50 .75 .90
22 26 35 48 60 72
.95
77
lowest : 18 19 20 21 22, highest: 91 92 93 96 97
------------------------------------------------------------
sexe
n missing distinct
2000 0 2
Value Homme Femme
Frequency 899 1101
Proportion 0.45 0.55
------------------------------------------------------------
nivetud
n missing distinct
1888 112 8
lowest : N'a jamais fait d'etudes A arrete ses etudes, avant la derniere annee d'etudes primaires Derniere annee d'etudes primaires 1er cycle 2eme cycle
highest: 1er cycle 2eme cycle Enseignement technique ou professionnel court Enseignement technique ou professionnel long Enseignement superieur y compris technique superieur
------------------------------------------------------------
poids
n missing distinct Info Mean Gmd
2000 0 1877 1 5536 4553
.05 .10 .25 .50 .75 .90
799.8 1161.7 2221.8 4631.2 7626.5 10819.0
.95
13647.9
lowest : 78.08 92.68 92.94 127.90 153.01
highest: 27195.84 29548.79 29570.79 29657.94 31092.14
------------------------------------------------------------
occup
n missing distinct
2000 0 7
lowest : Exerce une profession Chomeur Etudiant, eleve Retraite Retire des affaires
highest: Etudiant, eleve Retraite Retire des affaires Au foyer Autre inactif
Exerce une profession (1049, 0.524), Chomeur (134, 0.067),
Etudiant, eleve (94, 0.047), Retraite (392, 0.196), Retire
des affaires (77, 0.038), Au foyer (171, 0.086), Autre
inactif (83, 0.042)
------------------------------------------------------------
qualif
n missing distinct
1653 347 7
lowest : Ouvrier specialise Ouvrier qualifie Technicien Profession intermediaire Cadre
highest: Technicien Profession intermediaire Cadre Employe Autre
Ouvrier specialise (203, 0.123), Ouvrier qualifie (292,
0.177), Technicien (86, 0.052), Profession intermediaire
(160, 0.097), Cadre (260, 0.157), Employe (594, 0.359),
Autre (58, 0.035)
------------------------------------------------------------
freres.soeurs
n missing distinct Info Mean Gmd
2000 0 19 0.977 3.283 2.87
.05 .10 .25 .50 .75 .90
0 1 1 2 5 7
.95
9
lowest : 0 1 2 3 4, highest: 14 15 16 18 22
0 (167, 0.084), 1 (407, 0.203), 2 (427, 0.214), 3 (284,
0.142), 4 (210, 0.105), 5 (151, 0.076), 6 (99, 0.050), 7
(94, 0.047), 8 (52, 0.026), 9 (37, 0.018), 10 (21, 0.011),
11 (21, 0.011), 12 (8, 0.004), 13 (10, 0.005), 14 (4,
0.002), 15 (4, 0.002), 16 (1, 0.000), 18 (2, 0.001), 22 (1,
0.000)
------------------------------------------------------------
clso
n missing distinct
2000 0 3
Value Oui Non Ne sait pas
Frequency 936 1037 27
Proportion 0.468 0.518 0.014
------------------------------------------------------------
relig
n missing distinct
2000 0 6
lowest : Pratiquant regulier Pratiquant occasionnel Appartenance sans pratique Ni croyance ni appartenance Rejet
highest: Pratiquant occasionnel Appartenance sans pratique Ni croyance ni appartenance Rejet NSP ou NVPR
Pratiquant regulier (266, 0.133), Pratiquant occasionnel
(442, 0.221), Appartenance sans pratique (760, 0.380), Ni
croyance ni appartenance (399, 0.200), Rejet (93, 0.046),
NSP ou NVPR (40, 0.020)
------------------------------------------------------------
trav.imp
n missing distinct
1048 952 4
Le plus important (29, 0.028), Aussi important que le reste
(259, 0.247), Moins important que le reste (708, 0.676),
Peu important (52, 0.050)
------------------------------------------------------------
trav.satisf
n missing distinct
1048 952 3
Value Satisfaction Insatisfaction Equilibre
Frequency 480 117 451
Proportion 0.458 0.112 0.430
------------------------------------------------------------
hard.rock
n missing distinct
2000 0 2
Value Non Oui
Frequency 1986 14
Proportion 0.993 0.007
------------------------------------------------------------
lecture.bd
n missing distinct
2000 0 2
Value Non Oui
Frequency 1953 47
Proportion 0.977 0.024
------------------------------------------------------------
peche.chasse
n missing distinct
2000 0 2
Value Non Oui
Frequency 1776 224
Proportion 0.888 0.112
------------------------------------------------------------
cuisine
n missing distinct
2000 0 2
Value Non Oui
Frequency 1119 881
Proportion 0.559 0.440
------------------------------------------------------------
bricol
n missing distinct
2000 0 2
Value Non Oui
Frequency 1147 853
Proportion 0.574 0.426
------------------------------------------------------------
cinema
n missing distinct
2000 0 2
Value Non Oui
Frequency 1174 826
Proportion 0.587 0.413
------------------------------------------------------------
sport
n missing distinct
2000 0 2
Value Non Oui
Frequency 1277 723
Proportion 0.638 0.362
------------------------------------------------------------
heures.tv
n missing distinct Info Mean Gmd
1995 5 29 0.972 2.247 1.877
.05 .10 .25 .50 .75 .90
0 0 1 2 3 4
.95
5
lowest : 0.0 0.1 0.2 0.3 0.4, highest: 8.0 9.0 10.0 11.0 12.0
------------------------------------------------------------Quelques calculs simples
Maintenant que nous savons accéder aux variables, effectuons quelques calculs simples comme la moyenne, la médiane, le minimum et le maximum, à l’aide des fonctions mean, median, min et max.
[1] 48.16[1] 48[1] 18[1] 97Au sens strict, il ne s’agit pas d’un véritable âge moyen puisqu’il faudrait ajouter 0,5 à cette valeur calculée, un âge moyen se calculant à partir d’âges exacts et non à partir d’âges révolus. Voir le chapitre Calculer un âge.
On peut aussi très facilement obtenir un tri à plat à l’aide la fonction table :
Ouvrier specialise Ouvrier qualifie
203 292
Technicien Profession intermediaire
86 160
Cadre Employe
260 594
Autre
58 La fonction summary, bien pratique, permet d’avoir une vue résumée d’une variable. Elle s’applique à tout type d’objets (y compris un tableau de données entier) et s’adapte à celui-ci.
Min. 1st Qu. Median Mean 3rd Qu. Max.
18.0 35.0 48.0 48.2 60.0 97.0 Ouvrier specialise Ouvrier qualifie
203 292
Technicien Profession intermediaire
86 160
Cadre Employe
260 594
Autre NA's
58 347 id age sexe
Min. : 1 Min. :18.0 Homme: 899
1st Qu.: 501 1st Qu.:35.0 Femme:1101
Median :1000 Median :48.0
Mean :1000 Mean :48.2
3rd Qu.:1500 3rd Qu.:60.0
Max. :2000 Max. :97.0
nivetud
Enseignement technique ou professionnel court :463
Enseignement superieur y compris technique superieur:441
Derniere annee d'etudes primaires :341
1er cycle :204
2eme cycle :183
(Other) :256
NA's :112
poids occup
Min. : 78 Exerce une profession:1049
1st Qu.: 2222 Chomeur : 134
Median : 4631 Etudiant, eleve : 94
Mean : 5536 Retraite : 392
3rd Qu.: 7627 Retire des affaires : 77
Max. :31092 Au foyer : 171
Autre inactif : 83
qualif freres.soeurs
Employe :594 Min. : 0.00
Ouvrier qualifie :292 1st Qu.: 1.00
Cadre :260 Median : 2.00
Ouvrier specialise :203 Mean : 3.28
Profession intermediaire:160 3rd Qu.: 5.00
(Other) :144 Max. :22.00
NA's :347
clso relig
Oui : 936 Pratiquant regulier :266
Non :1037 Pratiquant occasionnel :442
Ne sait pas: 27 Appartenance sans pratique :760
Ni croyance ni appartenance:399
Rejet : 93
NSP ou NVPR : 40
trav.imp trav.satisf
Le plus important : 29 Satisfaction :480
Aussi important que le reste:259 Insatisfaction:117
Moins important que le reste:708 Equilibre :451
Peu important : 52 NA's :952
NA's :952
hard.rock lecture.bd peche.chasse cuisine bricol
Non:1986 Non:1953 Non:1776 Non:1119 Non:1147
Oui: 14 Oui: 47 Oui: 224 Oui: 881 Oui: 853
cinema sport heures.tv
Non:1174 Non:1277 Min. : 0.00
Oui: 826 Oui: 723 1st Qu.: 1.00
Median : 2.00
Mean : 2.25
3rd Qu.: 3.00
Max. :12.00
NA's :5 Nos premiers graphiques
R est très puissant en termes de représentations graphiques, notamment grâce à des extensions dédiées. Pour l’heure contentons-nous d’un premier essai à l’aide de la fonction générique plot.
Essayons avec deux variables :
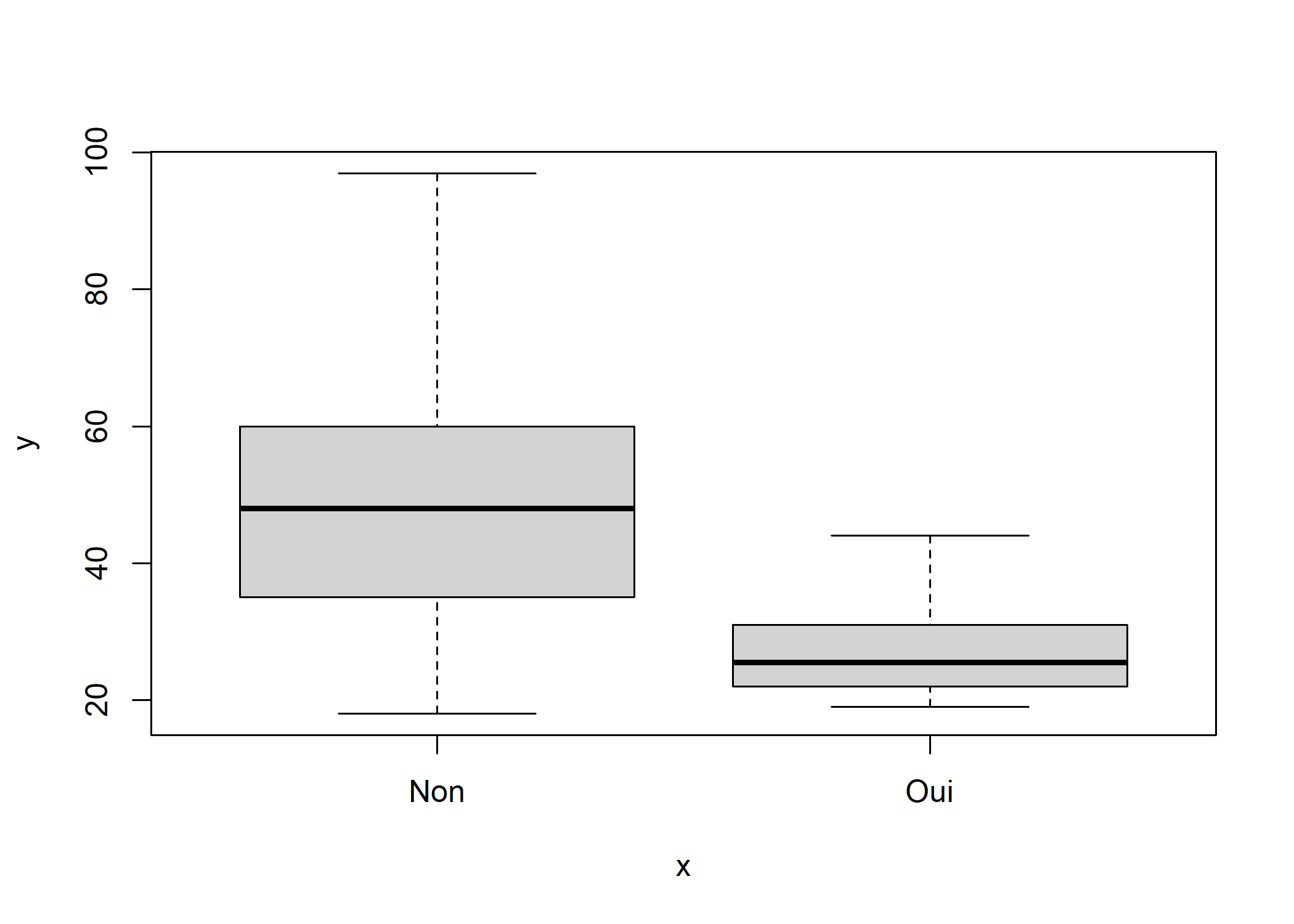
Il semblerait bien que les amateurs de hard rock soient plus jeunes.
Et ensuite ?
Nous n’avons qu’entr’aperçu les possibilités de R. Avant de pouvoir nous lancer dans des analyses statisques, il est préférable de revenir un peu aux fondamentaux de R (les types d’objets, la syntaxe, le recodage de variables…) mais aussi comment installer des extensions, importer des données, etc. Nous vous conseillons donc de poursuivre la lecture de la section Prise en main puis de vous lancer à l’assault de la section Statistique introductive.
Sous Mac OS X, on utilise les touches Pomme et Entrée.↩︎