

Visualiser ses données
Au fil des différents chapitres, nous avons abordé diverses fonctions utiles au quotidien et permettant de visualiser ses données. Ce chapitre se propose de les regrouper.
Chargeons tout d’abord quelques fichiers de données à titre d’exemple.
Inspection visuelle des données
La particularité de R par rapport à d’autres logiciels comme Modalisa ou SPSS est de ne pas proposer, par défaut, de vue des données sous forme de tableau. Ceci peut parfois être un peu déstabilisant dans les premiers temps d’utilisation, même si l’on perd vite l’habitude et qu’on finit par se rendre compte que « voir » les données n’est pas forcément un gage de productivité ou de rigueur dans le traitement.
Néanmoins, R propose une interface permettant de visualiser le contenu d’un tableau de données à l’aide de la fonction View :
Sous RStudio, on peut aussi afficher la visionneusee (viewer) en cliquant sur la petite icône en forme de tableau située à droite de la ligne d’un tableau de données dans l’onglet Environment du quadrant supérieur droit (cf. figure ci-après).
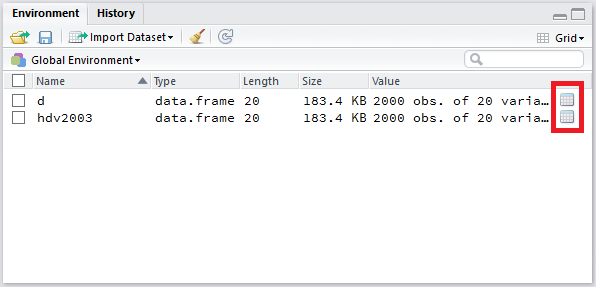
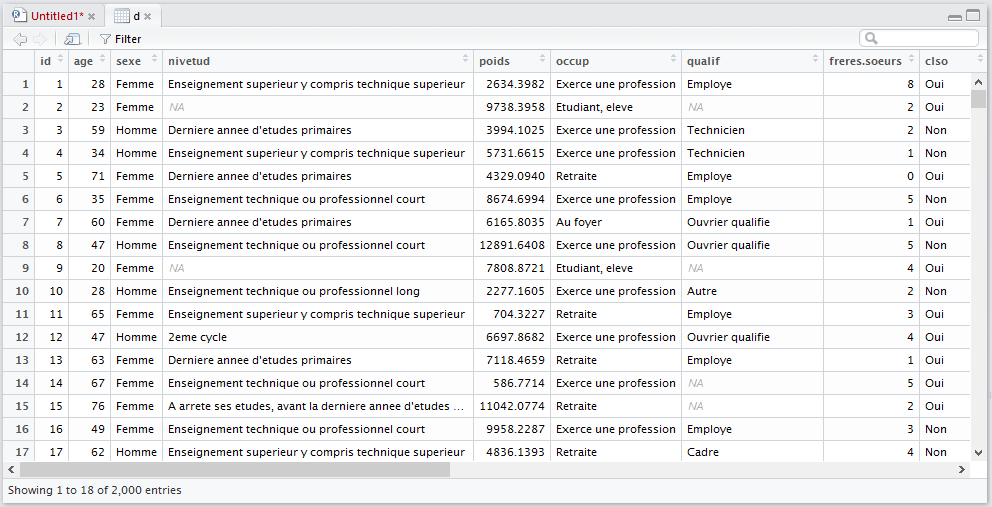
Dans tous les cas, RStudio lancera le viewer dans un onglet dédié dans le quadrant supérieur gauche. Le visualiseur de RStudio est plus avancé que celui-de base fournit par R. Il est possible de trier les données selon une variable en cliquant sur le nom de cette dernière. Il y a également un champs de recherche et un bouton Filter donnant accès à des options de filtrage avancées.
summary
La fonction summary permet d’avoir une vue résumée d’une variable. Elle s’applique à tout type d’objets (y compris un tableau de données entier) et s’adapte à celui-ci.
Min. 1st Qu. Median Mean 3rd Qu. Max.
18.00 35.00 48.00 48.16 60.00 97.00 Ouvrier specialise Ouvrier qualifie
203 292
Technicien Profession intermediaire
86 160
Cadre Employe
260 594
Autre NA's
58 347 id age sexe
Min. : 1.0 Min. :18.00 Homme: 899
1st Qu.: 500.8 1st Qu.:35.00 Femme:1101
Median :1000.5 Median :48.00
Mean :1000.5 Mean :48.16
3rd Qu.:1500.2 3rd Qu.:60.00
Max. :2000.0 Max. :97.00
nivetud
Enseignement technique ou professionnel court :463
Enseignement superieur y compris technique superieur:441
Derniere annee d'etudes primaires :341
1er cycle :204
2eme cycle :183
(Other) :256
NA's :112
poids occup
Min. : 78.08 Exerce une profession:1049
1st Qu.: 2221.82 Chomeur : 134
Median : 4631.19 Etudiant, eleve : 94
Mean : 5535.61 Retraite : 392
3rd Qu.: 7626.53 Retire des affaires : 77
Max. :31092.14 Au foyer : 171
Autre inactif : 83
qualif freres.soeurs
Employe :594 Min. : 0.000
Ouvrier qualifie :292 1st Qu.: 1.000
Cadre :260 Median : 2.000
Ouvrier specialise :203 Mean : 3.283
Profession intermediaire:160 3rd Qu.: 5.000
(Other) :144 Max. :22.000
NA's :347
clso relig
Oui : 936 Pratiquant regulier :266
Non :1037 Pratiquant occasionnel :442
Ne sait pas: 27 Appartenance sans pratique :760
Ni croyance ni appartenance:399
Rejet : 93
NSP ou NVPR : 40
trav.imp trav.satisf
Le plus important : 29 Satisfaction :480
Aussi important que le reste:259 Insatisfaction:117
Moins important que le reste:708 Equilibre :451
Peu important : 52 NA's :952
NA's :952
hard.rock lecture.bd peche.chasse cuisine bricol
Non:1986 Non:1953 Non:1776 Non:1119 Non:1147
Oui: 14 Oui: 47 Oui: 224 Oui: 881 Oui: 853
cinema sport heures.tv
Non:1174 Non:1277 Min. : 0.000
Oui: 826 Oui: 723 1st Qu.: 1.000
Median : 2.000
Mean : 2.247
3rd Qu.: 3.000
Max. :12.000
NA's :5 str
La fonction str est plus complète que names. Elle liste les différentes variables, indique leur type et donne le cas échéant des informations supplémentaires ainsi qu’un échantillon des premières valeurs prises par cette variable :
'data.frame': 2000 obs. of 20 variables:
$ id : int 1 2 3 4 5 6 7 8 9 10 ...
$ age : int 28 23 59 34 71 35 60 47 20 28 ...
$ sexe : Factor w/ 2 levels "Homme","Femme": 2 2 1 1 2 2 2 1 2 1 ...
$ nivetud : Factor w/ 8 levels "N'a jamais fait d'etudes",..: 8 NA 3 8 3 6 3 6 NA 7 ...
$ poids : num 2634 9738 3994 5732 4329 ...
$ occup : Factor w/ 7 levels "Exerce une profession",..: 1 3 1 1 4 1 6 1 3 1 ...
$ qualif : Factor w/ 7 levels "Ouvrier specialise",..: 6 NA 3 3 6 6 2 2 NA 7 ...
$ freres.soeurs: int 8 2 2 1 0 5 1 5 4 2 ...
$ clso : Factor w/ 3 levels "Oui","Non","Ne sait pas": 1 1 2 2 1 2 1 2 1 2 ...
$ relig : Factor w/ 6 levels "Pratiquant regulier",..: 4 4 4 3 1 4 3 4 3 2 ...
$ trav.imp : Factor w/ 4 levels "Le plus important",..: 4 NA 2 3 NA 1 NA 4 NA 3 ...
$ trav.satisf : Factor w/ 3 levels "Satisfaction",..: 2 NA 3 1 NA 3 NA 2 NA 1 ...
$ hard.rock : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 1 1 1 1 ...
$ lecture.bd : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 1 1 1 1 ...
$ peche.chasse : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 2 2 1 1 ...
$ cuisine : Factor w/ 2 levels "Non","Oui": 2 1 1 2 1 1 2 2 1 1 ...
$ bricol : Factor w/ 2 levels "Non","Oui": 1 1 1 2 1 1 1 2 1 1 ...
$ cinema : Factor w/ 2 levels "Non","Oui": 1 2 1 2 1 2 1 1 2 2 ...
$ sport : Factor w/ 2 levels "Non","Oui": 1 2 2 2 1 2 1 1 1 2 ...
$ heures.tv : num 0 1 0 2 3 2 2.9 1 2 2 ...La fonction str est essentielle à connaître et peut s’appliquer à n’importe quel type d’objet. C’est un excellent moyen de connaître en détail la structure d’un objet. Cependant, les résultats peuvent être parfois trop détaillés et on lui priviligiera dans certains cas les fonctions suivantes.
glimpse (dplyr)
L’extension dplyr (voir le chapitre dédié), propose une fonction glimpse (ce qui signifie aperçu
en anglais) qui permet de visualiser rapidement et de manière condensée le contenu d’un tableau de données.
Rows: 2,000
Columns: 20
$ id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 1…
$ age <int> 28, 23, 59, 34, 71, 35, 60, 47, 20, …
$ sexe <fct> Femme, Femme, Homme, Homme, Femme, F…
$ nivetud <fct> "Enseignement superieur y compris te…
$ poids <dbl> 2634.3982, 9738.3958, 3994.1025, 573…
$ occup <fct> "Exerce une profession", "Etudiant, …
$ qualif <fct> Employe, NA, Technicien, Technicien,…
$ freres.soeurs <int> 8, 2, 2, 1, 0, 5, 1, 5, 4, 2, 3, 4, …
$ clso <fct> Oui, Oui, Non, Non, Oui, Non, Oui, N…
$ relig <fct> Ni croyance ni appartenance, Ni croy…
$ trav.imp <fct> Peu important, NA, Aussi important q…
$ trav.satisf <fct> Insatisfaction, NA, Equilibre, Satis…
$ hard.rock <fct> Non, Non, Non, Non, Non, Non, Non, N…
$ lecture.bd <fct> Non, Non, Non, Non, Non, Non, Non, N…
$ peche.chasse <fct> Non, Non, Non, Non, Non, Non, Oui, O…
$ cuisine <fct> Oui, Non, Non, Oui, Non, Non, Oui, O…
$ bricol <fct> Non, Non, Non, Oui, Non, Non, Non, O…
$ cinema <fct> Non, Oui, Non, Oui, Non, Oui, Non, N…
$ sport <fct> Non, Oui, Oui, Oui, Non, Oui, Non, N…
$ heures.tv <dbl> 0.0, 1.0, 0.0, 2.0, 3.0, 2.0, 2.9, 1…look_for (labelled)
L’extension labelled propose une fonction look_for, inspirée de Stata, qui permet de lister les différentes variables d’un fichier de données, ainsi que leurs principales caractéristiques :
pos variable label col_type values
<chr> <chr> <chr> <chr> <chr>
1 id — int range: 1 - 2000
2 age — int range: 18 - 97
3 sexe — fct Homme
Femme
4 nivetud — fct N'a jamais fait d'etudes
A arrete ses etudes, avant la derniere annee d'etudes primaires
Derniere annee d'etudes primaires
1er cycle
2eme cycle
Enseignement technique ou professionnel court
Enseignement technique ou professionnel long
Enseignement superieur y compris technique superieur
5 poids — dbl range: 78.0783403 - 31092.14132
6 occup — fct Exerce une profession
Chomeur
Etudiant, eleve
Retraite
Retire des affaires
Au foyer
Autre inactif
7 qualif — fct Ouvrier specialise
Ouvrier qualifie
Technicien
Profession intermediaire
Cadre
Employe
Autre
8 freres.soeurs — int range: 0 - 22
9 clso — fct Oui
Non
Ne sait pas
10 relig — fct Pratiquant regulier
Pratiquant occasionnel
Appartenance sans pratique
Ni croyance ni appartenance
Rejet
NSP ou NVPR
11 trav.imp — fct Le plus important
Aussi important que le reste
Moins important que le reste
Peu important
12 trav.satisf — fct Satisfaction
Insatisfaction
Equilibre
13 hard.rock — fct Non
Oui
14 lecture.bd — fct Non
Oui
15 peche.chasse — fct Non
Oui
16 cuisine — fct Non
Oui
17 bricol — fct Non
Oui
18 cinema — fct Non
Oui
19 sport — fct Non
Oui
20 heures.tv — dbl range: 0 - 12 Lorsque l’on a un gros tableau de données avec de nombreuses variables, il peut être difficile de retrouver la ou les variables d’intérêt. Il est possible d’indiquer à look_for un mot-clé pour limiter la recherche. Par exemple :
pos variable label col_type values
<chr> <chr> <chr> <chr> <chr>
11 trav.imp — fct Le plus important
Aussi important que le reste
Moins important que le reste
Peu important
12 trav.satisf — fct Satisfaction
Insatisfaction
Equilibre Il est à noter que si la recherche n’est pas sensible à la casse (i.e. aux majuscules et aux minuscules), elle est sensible aux accents. Il est aussi possible de fournir plusieurs expressions de recherche.
La fonction look_for est par ailleurs compatible avec les étiquettes de variable de l’extension labelled, les étiquettes étant prise en compte dans la recherche d’une variable.
pos variable label col_type values
<chr> <chr> <chr> <chr> <chr>
7 milieu Milieu de résidence dbl+lbl [1] urbain
[2] rural
8 region Région de résidence dbl+lbl [1] Nord
[2] Est
[3] Sud
[4] Ouestpos variable label col_type values
<chr> <chr> <chr> <chr> <chr>
7 milieu Milieu de résidence dbl+lbl [1] urbain
[2] rural
8 region Région de résidence dbl+lbl [1] Nord
[2] Est
[3] Sud
[4] Ouest
16 nb_enf_ideal Nombre idéal d'enfants dbl+lbl [96] Ne sait pas
[99] manquant À noter, le résultat renvoyé par look_for est un tableau de données qui peut ensuite être aisément manipulé (voir l’aide de la fonction).
describe (questionr)
L’extension questionr fournit également une fonction bien pratique pour décrire les différentes variables d’un tableau de données. Il s’agit de describe. Faisons de suite un essai :
[2000 obs. x 20 variables] tbl_df tbl data.frame
$id:
integer: 1 2 3 4 5 6 7 8 9 10 ...
min: 1 - max: 2000 - NAs: 0 (0%) - 2000 unique values
$age:
integer: 28 23 59 34 71 35 60 47 20 28 ...
min: 18 - max: 97 - NAs: 0 (0%) - 78 unique values
$sexe:
nominal factor: "Femme" "Femme" "Homme" "Homme" "Femme" "Femme" "Femme" "Homme" "Femme" "Homme" ...
2 levels: Homme | Femme
NAs: 0 (0%)
$nivetud:
nominal factor: "Enseignement superieur y compris technique superieur" NA "Derniere annee d'etudes primaires" "Enseignement superieur y compris technique superieur" "Derniere annee d'etudes primaires" "Enseignement technique ou professionnel court" "Derniere annee d'etudes primaires" "Enseignement technique ou professionnel court" NA "Enseignement technique ou professionnel long" ...
8 levels: N'a jamais fait d'etudes | A arrete ses etudes, avant la derniere annee d'etudes primaires | Derniere annee d'etudes primaires | 1er cycle | 2eme cycle | Enseignement technique ou professionnel court | Enseignement technique ou professionnel long | Enseignement superieur y compris technique superieur
NAs: 112 (5.6%)
$poids:
numeric: 2634.3982157 9738.3957759 3994.1024587 5731.6615081 4329.0940022 8674.6993828 6165.8034861 12891.640759 7808.8720636 2277.160471 ...
min: 78.0783403 - max: 31092.14132 - NAs: 0 (0%) - 1877 unique values
$occup:
nominal factor: "Exerce une profession" "Etudiant, eleve" "Exerce une profession" "Exerce une profession" "Retraite" "Exerce une profession" "Au foyer" "Exerce une profession" "Etudiant, eleve" "Exerce une profession" ...
7 levels: Exerce une profession | Chomeur | Etudiant, eleve | Retraite | Retire des affaires | Au foyer | Autre inactif
NAs: 0 (0%)
$qualif:
nominal factor: "Employe" NA "Technicien" "Technicien" "Employe" "Employe" "Ouvrier qualifie" "Ouvrier qualifie" NA "Autre" ...
7 levels: Ouvrier specialise | Ouvrier qualifie | Technicien | Profession intermediaire | Cadre | Employe | Autre
NAs: 347 (17.3%)
$freres.soeurs:
integer: 8 2 2 1 0 5 1 5 4 2 ...
min: 0 - max: 22 - NAs: 0 (0%) - 19 unique values
$clso:
nominal factor: "Oui" "Oui" "Non" "Non" "Oui" "Non" "Oui" "Non" "Oui" "Non" ...
3 levels: Oui | Non | Ne sait pas
NAs: 0 (0%)
$relig:
nominal factor: "Ni croyance ni appartenance" "Ni croyance ni appartenance" "Ni croyance ni appartenance" "Appartenance sans pratique" "Pratiquant regulier" "Ni croyance ni appartenance" "Appartenance sans pratique" "Ni croyance ni appartenance" "Appartenance sans pratique" "Pratiquant occasionnel" ...
6 levels: Pratiquant regulier | Pratiquant occasionnel | Appartenance sans pratique | Ni croyance ni appartenance | Rejet | NSP ou NVPR
NAs: 0 (0%)
$trav.imp:
nominal factor: "Peu important" NA "Aussi important que le reste" "Moins important que le reste" NA "Le plus important" NA "Peu important" NA "Moins important que le reste" ...
4 levels: Le plus important | Aussi important que le reste | Moins important que le reste | Peu important
NAs: 952 (47.6%)
$trav.satisf:
nominal factor: "Insatisfaction" NA "Equilibre" "Satisfaction" NA "Equilibre" NA "Insatisfaction" NA "Satisfaction" ...
3 levels: Satisfaction | Insatisfaction | Equilibre
NAs: 952 (47.6%)
$hard.rock:
nominal factor: "Non" "Non" "Non" "Non" "Non" "Non" "Non" "Non" "Non" "Non" ...
2 levels: Non | Oui
NAs: 0 (0%)
$lecture.bd:
nominal factor: "Non" "Non" "Non" "Non" "Non" "Non" "Non" "Non" "Non" "Non" ...
2 levels: Non | Oui
NAs: 0 (0%)
$peche.chasse:
nominal factor: "Non" "Non" "Non" "Non" "Non" "Non" "Oui" "Oui" "Non" "Non" ...
2 levels: Non | Oui
NAs: 0 (0%)
$cuisine:
nominal factor: "Oui" "Non" "Non" "Oui" "Non" "Non" "Oui" "Oui" "Non" "Non" ...
2 levels: Non | Oui
NAs: 0 (0%)
$bricol:
nominal factor: "Non" "Non" "Non" "Oui" "Non" "Non" "Non" "Oui" "Non" "Non" ...
2 levels: Non | Oui
NAs: 0 (0%)
$cinema:
nominal factor: "Non" "Oui" "Non" "Oui" "Non" "Oui" "Non" "Non" "Oui" "Oui" ...
2 levels: Non | Oui
NAs: 0 (0%)
$sport:
nominal factor: "Non" "Oui" "Oui" "Oui" "Non" "Oui" "Non" "Non" "Non" "Oui" ...
2 levels: Non | Oui
NAs: 0 (0%)
$heures.tv:
numeric: 0 1 0 2 3 2 2.9 1 2 2 ...
min: 0 - max: 12 - NAs: 5 (0.2%) - 30 unique valuesComme on le voit sur cet exemple, describe nous affiche le type des variables, les premières valeurs de chacune, le nombre de valeurs manquantes, le nombre de valeurs différentes (uniques) ainsi que quelques autres informations suivant le type de variables.
Il est possible de restreindre l’affichage à seulement quelques variables en indiquant le nom de ces dernières ou une expression de recherche (comme avec lookfor).
[2000 obs. x 20 variables] tbl_df tbl data.frame
$age:
integer: 28 23 59 34 71 35 60 47 20 28 ...
min: 18 - max: 97 - NAs: 0 (0%) - 78 unique values
$trav.imp:
nominal factor: "Peu important" NA "Aussi important que le reste" "Moins important que le reste" NA "Le plus important" NA "Peu important" NA "Moins important que le reste" ...
4 levels: Le plus important | Aussi important que le reste | Moins important que le reste | Peu important
NAs: 952 (47.6%)
$trav.satisf:
nominal factor: "Insatisfaction" NA "Equilibre" "Satisfaction" NA "Equilibre" NA "Insatisfaction" NA "Satisfaction" ...
3 levels: Satisfaction | Insatisfaction | Equilibre
NAs: 952 (47.6%)On peut également transmettre juste une variable :
[2000 obs.]
nominal factor: "Femme" "Femme" "Homme" "Homme" "Femme" "Femme" "Femme" "Homme" "Femme" "Homme" ...
2 levels: Homme | Femme
NAs: 0 (0%)
n %
Homme 899 45
Femme 1101 55
Total 2000 100Enfin, describe est également compatible avec les vecteurs labellisés.
[2000 obs. x 17 variables] tbl_df tbl data.frame
$milieu: Milieu de résidence
labelled double: 2 2 2 2 2 2 2 2 2 2 ...
min: 1 - max: 2 - NAs: 0 (0%) - 2 unique values
2 value labels: [1] urbain [2] ruralÀ noter, l’argument freq.n.max permets d’indiquer le nombre de modalités en-dessous duquel describe renverra également un tri à plat de la variable.
[1814 obs. x 5 variables] tbl_df tbl data.frame
$id_menage: Identifiant du ménage
numeric: 1 2 3 4 5 6 7 8 9 10 ...
min: 1 - max: 1814 - NAs: 0 (0%) - 1814 unique values
$taille: Taille du ménage (nombre de membres)
numeric: 7 3 6 5 7 6 15 6 5 19 ...
min: 1 - max: 31 - NAs: 0 (0%) - 30 unique values
$sexe_chef: Sexe du chef de ménage
labelled double: 2 1 1 1 1 2 2 2 1 1 ...
min: 1 - max: 2 - NAs: 0 (0%) - 2 unique values
2 value labels: [1] homme [2] femme
n %
[1] homme 1420 78.3
[2] femme 394 21.7
Total 1814 100.0
$structure: Structure démographique du ménage
labelled double: 4 2 5 4 4 4 5 2 5 5 ...
min: 1 - max: 5 - NAs: 0 (0%) - 5 unique values
6 value labels: [0] pas d'adulte [1] un adulte [2] deux adultes de sexe opposé [3] deux adultes de même sexe [4] trois adultes ou plus avec lien de parenté [5] adultes sans lien de parenté
n %
[0] pas d'adulte 0 0.0
[1] un adulte 78 4.3
[2] deux adultes de sexe opposé 439 24.2
[3] deux adultes de même sexe 75 4.1
[4] trois adultes ou plus avec lien de parenté 920 50.7
[5] adultes sans lien de parenté 302 16.6
Total 1814 100.0
$richesse: Niveau de vie (quintiles)
labelled double: 1 2 2 1 1 3 2 5 4 3 ...
min: 1 - max: 5 - NAs: 0 (0%) - 5 unique values
5 value labels: [1] très pauvre [2] pauvre [3] moyen [4] riche [5] très riche
n %
[1] très pauvre 335 18.5
[2] pauvre 357 19.7
[3] moyen 402 22.2
[4] riche 350 19.3
[5] très riche 370 20.4
Total 1814 100.0Addins de codebook
L’extension codebook fournit plusieurs addins permettant d’explorer les étiquettes des différentes variables d’un tableau de données. Ils sont accessibles par le menu Addins de RStudio.
On peut aussi lancer les addins manuellement, par exemple avec la commande suivante :
skim (skimr)
L’extension skimr a pour objectif de fournir une fonction skim comme alternative à summary{base} pour les vecteurs et les tableaux de données afin de fournir plus de statistiques dans un format plus compact. Elle peut être appliquée à un vecteur donné ou directement à un tableau de données.
| Name | hdv2003$cuisine |
| Number of rows | 2000 |
| Number of columns | 1 |
| _______________________ | |
| Column type frequency: | |
| factor | 1 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| data | 0 | 1 | FALSE | 2 | Non: 1119, Oui: 881 |
| Name | hdv2003 |
| Number of rows | 2000 |
| Number of columns | 20 |
| _______________________ | |
| Column type frequency: | |
| factor | 15 |
| numeric | 5 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| sexe | 0 | 1.00 | FALSE | 2 | Fem: 1101, Hom: 899 |
| nivetud | 112 | 0.94 | FALSE | 8 | Ens: 463, Ens: 441, Der: 341, 1er: 204 |
| occup | 0 | 1.00 | FALSE | 7 | Exe: 1049, Ret: 392, Au : 171, Cho: 134 |
| qualif | 347 | 0.83 | FALSE | 7 | Emp: 594, Ouv: 292, Cad: 260, Ouv: 203 |
| clso | 0 | 1.00 | FALSE | 3 | Non: 1037, Oui: 936, Ne : 27 |
| relig | 0 | 1.00 | FALSE | 6 | App: 760, Pra: 442, Ni : 399, Pra: 266 |
| trav.imp | 952 | 0.52 | FALSE | 4 | Moi: 708, Aus: 259, Peu: 52, Le : 29 |
| trav.satisf | 952 | 0.52 | FALSE | 3 | Sat: 480, Equ: 451, Ins: 117 |
| hard.rock | 0 | 1.00 | FALSE | 2 | Non: 1986, Oui: 14 |
| lecture.bd | 0 | 1.00 | FALSE | 2 | Non: 1953, Oui: 47 |
| peche.chasse | 0 | 1.00 | FALSE | 2 | Non: 1776, Oui: 224 |
| cuisine | 0 | 1.00 | FALSE | 2 | Non: 1119, Oui: 881 |
| bricol | 0 | 1.00 | FALSE | 2 | Non: 1147, Oui: 853 |
| cinema | 0 | 1.00 | FALSE | 2 | Non: 1174, Oui: 826 |
| sport | 0 | 1.00 | FALSE | 2 | Non: 1277, Oui: 723 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| id | 0 | 1 | 1000.50 | 577.49 | 1.00 | 500.75 | 1000.50 | 1500.25 | 2000.00 | ▇▇▇▇▇ |
| age | 0 | 1 | 48.16 | 16.94 | 18.00 | 35.00 | 48.00 | 60.00 | 97.00 | ▆▇▇▅▁ |
| poids | 0 | 1 | 5535.61 | 4375.03 | 78.08 | 2221.82 | 4631.19 | 7626.54 | 31092.14 | ▇▃▁▁▁ |
| freres.soeurs | 0 | 1 | 3.28 | 2.77 | 0.00 | 1.00 | 2.00 | 5.00 | 22.00 | ▇▂▁▁▁ |
| heures.tv | 5 | 1 | 2.25 | 1.78 | 0.00 | 1.00 | 2.00 | 3.00 | 12.00 | ▇▃▁▁▁ |
On peut noter que les variables sont regroupées par type.
Il est possible de sélectionner des variables à la manière de dplyr. Voir l’aide de contains.
| Name | hdv2003 |
| Number of rows | 2000 |
| Number of columns | 20 |
| _______________________ | |
| Column type frequency: | |
| factor | 2 |
| numeric | 2 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| relig | 0 | 1 | FALSE | 6 | App: 760, Pra: 442, Ni : 399, Pra: 266 |
| lecture.bd | 0 | 1 | FALSE | 2 | Non: 1953, Oui: 47 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| freres.soeurs | 0 | 1 | 3.28 | 2.77 | 0 | 1 | 2 | 5 | 22 | ▇▂▁▁▁ |
| heures.tv | 5 | 1 | 2.25 | 1.78 | 0 | 1 | 2 | 3 | 12 | ▇▃▁▁▁ |
Le support des vecteurs labellisés est encore en cours d’intégration.
| Name | menages |
| Number of rows | 1814 |
| Number of columns | 5 |
| _______________________ | |
| Column type frequency: | |
| numeric | 5 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| id_menage | 0 | 1 | 907.50 | 523.80 | 1 | 454.25 | 907.5 | 1360.75 | 1814 | ▇▇▇▇▇ |
| taille | 0 | 1 | 7.50 | 4.42 | 1 | 4.00 | 6.0 | 9.00 | 31 | ▇▅▁▁▁ |
| sexe_chef | 0 | 1 | 1.22 | 0.41 | 1 | 1.00 | 1.0 | 1.00 | 2 | ▇▁▁▁▂ |
| structure | 0 | 1 | 3.51 | 1.15 | 1 | 2.00 | 4.0 | 4.00 | 5 | ▁▃▁▇▂ |
| richesse | 0 | 1 | 3.03 | 1.39 | 1 | 2.00 | 3.0 | 4.00 | 5 | ▇▇▇▇▇ |
create_report (DataExplorer)
L’extension DataExplorer fournit des outils d’exploration graphique d’un fichier de données. En premier lieu, sa fonction create_report génère un rapport automatique à partir d’un tableau de données.
Le résultat de ce rapport est visible sur http://larmarange.github.io/analyse-R/data/hdv2003_DataExplorer_report.html.
L’extension fournit également différentes fonctions graphiques, présentées en détail dans la vignette inclue dans l’extension et visible sur https://cran.r-project.org/web/packages/DataExplorer/vignettes/dataexplorer-intro.html.
makeCodebook (dataMaid)
L’extension dataMaid propose une fonction makeCodebook permettant de générer une présentation de l’ensemble des variables d’un tableau de données, au format PDF, Word ou HTML.
Vous pouvez cliquer sur ce lien pour voir le PDF produit par dataMaid.
scan_data (pointblank)
L’extension pointblank propose une fonction scan_data permettant de générer un rapport automatisé sur un jeu de données. Le rapport est surtout détaillé pour les variables continues mais ne fournit que peu d’informations que les variables catégorielles. La fonction ne tient pas compte non plus des variables labellisées. La fonction export_report permet d’exporter le rapport obtenu au format HTML.
library(pointblank)
rapport <- scan_data(hdv2003)
export_report(rapport, filename = "data/scan_data_hdv2003.html")Vous pouvez cliquer sur ce lien pour voir le fichier HTML produit par pointblank.